越聰明越難贏:波動率模型的複雜度天花板
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
越聰明越難贏:波動率模型的複雜度天花板
VIX 上週收在 17.28,比 6 月初那次短暫衝上 22 已經降了很多,但距離真正安靜(VIX 低於 15)還差一截。這種「不高不低、隱隱有點壓」的市場氛圍,其實最容易讓人想去尋找更厲害的預測工具。
既然波動率不太好猜,那就用更複雜的模型?加更多指標?換深度學習?
我們在過去幾週把這個直覺拿去正式測了。結果很不給面子。
複雜度這條路,我們走過很多趟
過去幾週的研究有一條隱藏的共同主線,與其說它是不同的個別問題,更像是同一件事從不同角度反覆給出同一個答案。
第一站:「老方法」比「聰明的升級版」更頑固
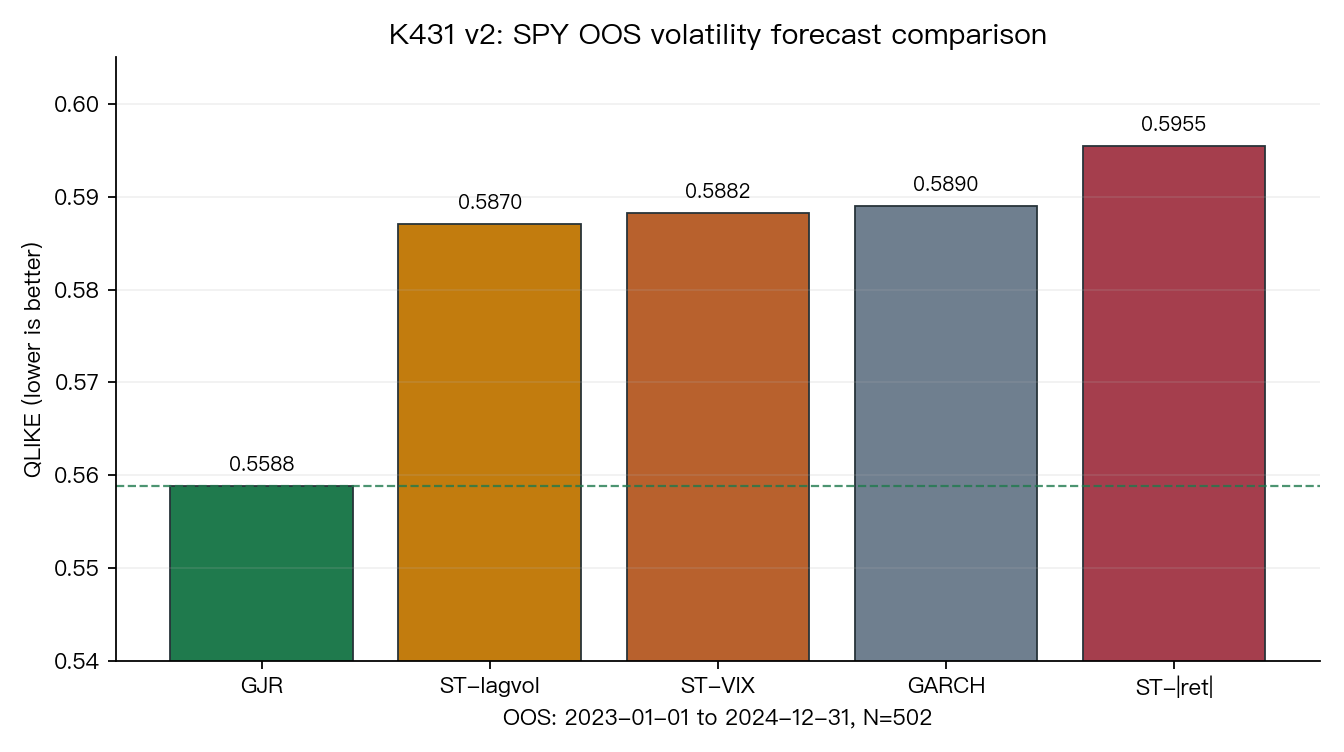
6 月 16 日那篇〈把 GARCH 改聰明反而更笨〉,做了一個在教科書裡看起來很合理的嘗試:把標準 GARCH 加上「平滑切換」(smooth transition)機制,讓波動率模型能感知市場現在的狀態,是恐慌期還是平靜期,然後自動切換不同的參數組合。試了三種版本:用 VIX 判斷、用當天報酬幅度判斷、用滯後波動率判斷。
OOS 期間是 2023 到 2024 年,502 個交易日。
三種版本全輸。不是小輸,是顯著輸。最差的輸 GJR-GARCH 超過 6%(以 QLIKE 衡量)。GJR 只比標準 GARCH 多了一個參數:壞消息造成的波動比好消息大這件事(就是 leverage effect)。一個參數,加上 20 年的市場觀察,就讓那些多估了 4 個參數的複雜版本無從反擊。
第二站:看起來有關係,卻沒法賺錢
6 月 15 日那篇〈看起來很準,卻完全沒用〉記錄了一個更微妙的失敗。研究人員發現一個 GARCH 衍生指標(g component)和市場隱含的波動率溢酬(VRP)同期相關性很高。Granger causality 檢定說顯著,F 統計量看起來漂亮。
但到了真正的預測比賽,所有時間尺度的嚴格統計檢驗都未通過門檻。搬進交易策略之後,用這個訊號操作的年化 Sharpe 是 -1.06,而什麼都不做、永遠賣波動率的 naive baseline 是 +0.85。
統計上看起來有關係的東西,預測時就是沒用。
第三站:多裝指標,反而打架
6 月 19 日那篇〈幫風險模型多裝一大包聰明指標,結果反而更差〉測的是另一種直覺:既然單一特徵不夠,那多塞一堆有沒有幫助?波動加速度、跳躍強度、下行占比、隱含波動率和已實現波動率的差距,全部丟進去。
結果很乾脆:最簡單的版本(只看短中長三個尺度的歷史波動)反而排第一。加強版誤差從 1.283 惡化到 1.627。機器自動篩選特徵?也輸,只是輸少一點(1.483)。
問題出在特徵之間互相搶解釋權,讓模型不知道該信哪個,係數因此跳動不穩。真正有訊號的其實只有一個(隱含波動率和已實現波動率的落差),但把它和另外五個一起塞,訊號被稀釋掉了。
第四站:跑一萬次,假設不對還是白搭
6 月 20 日那篇〈跑一萬次模擬,不一定比老方法更懂風險〉說的是蒙地卡羅模擬在 VaR 估計上的限制。「模擬一萬次」聽起來比歷史模擬更精密,但如果底層假設把市場尾巴估得太扁(常態分布或太平滑的假設),那你跑再多次,只是在重複一個不夠真的故事。
常態版模擬:8 組只過 2 組。直接讀最近一年市場極端波動痕跡的方法:8 組全過。
計算量大,不等於結果更可靠。
同樣的故事,在不同角度重複出現
回到更早的 6 月 11 日,那篇〈做了 305 次投資研究後,真正活下來的結論有多少?〉把整個研究系統做了一次體檢。305 個實驗,最後偏正向的只有 86 個(28.2%)。大部分「看起來合理的投資直覺」,只要放進嚴格測試,就會縮水。
最後活下來的結論反而很樸素:波動控管是風險管理工具,不是報酬放大器;模型之間的差距通常沒有想像中大;偷看未來是最高優先防範的設計缺陷。
也有一篇 6 月 9 日的文獻整理(〈2025 的波動率文獻,其實沒有叫你先追 AI 模型〉)梳理了 2025 年前後 6 篇主流研究,結論同樣沒有給「AI 已全面壓過老模型」的支持。文獻真正在說的,是比較規則本身常常沒鎖好:預測目標不一樣、評估指標換一換排名就變、baseline 選太弱就讓新模型顯得很強。
天花板在哪裡,為什麼存在?
把這幾篇串起來,有一個共同的解釋。
波動率預測的精度上限,不主要是被模型複雜度決定的,而是被 資料本身的噪訊比 決定的。SPY 日頻報酬裡,真正可以被線性結構捕捉的「訊號」部分非常有限;超過那個上限,再多的參數和計算量,只是在把噪訊打磨得更漂亮,然後稱之為擬合。
GJR-GARCH 用一個 leverage effect 係數抓到了最關鍵的那塊。加 smooth transition 只是在問「哪個時段 leverage 更強?」,但這個問題的答案已經在 GJR 的非對稱項裡面了。
HAR-RV 用三個尺度的歷史已實現波動做預測,隱含地抓住了波動率的長記憶性。再加六個衍生特徵,大部分都是原本三個尺度的線性組合,所以只是在描述同一件事。
這不代表永遠不該嘗試更複雜的模型。但它代表一件很有用的事:
在你認真嘗試複雜模型之前,先確定你對老模型做了足夠公平、足夠嚴格的比較。大部分時候你會發現,差距其實比你想的小。
對一般投資人的意思
如果你在評估一套風險管理或波動率預測工具,有幾個問題比「它用的模型有多新」更值得先問:
- 它的比較 baseline 夠強嗎?如果對手只是 GARCH(1,1) 而不是 GJR,那勝利的含金量就有限。
- 是樣本內還是樣本外的表現?很多策略在歷史數據裡看起來很強,但這段數據可能剛好就是用來設計它的。
- 統計顯著和賺不賺錢是兩件事。K998 的 g 指標統計上顯著,交易 Sharpe 卻是 -1.06。
這幾篇累積下來的訊息,其實是一個很老派但很有用的提醒:
多做一點本來就說得過去的事,少追那些聽起來很聰明但還沒被嚴格驗證的升級。
VIX 在 17 的時候,最容易想去找更厲害的工具。但這幾篇告訴我們,這個念頭通常讓你花更多力氣,卻不一定走到更遠的地方。
本期精選
從複雜模型失敗實錄出發
把 GARCH 改聰明反而更笨:3 種 STGARCH 在 SPY 上全輸給老派 GJR(2026-06-16)— 三種平滑切換版本在 502 天 OOS 差距 5–7%,輸給只多一個參數的 GJR。
看起來很準,卻完全沒用:一個 GARCH 指標的預測失敗紀錄(2026-06-15)— g 指標 Granger 顯著,卻在實盤 Sharpe -1.06;統計顯著從來就不是賺錢的同義詞。
幫風險模型多裝一大包聰明指標,結果反而更差(2026-06-19)— HAR 加六個特徵 QLIKE 從 1.283 退步到 1.627,最簡單版本排第一。
跑一萬次模擬,不一定比老方法更懂風險(2026-06-20)— 假設把市場尾巴估扁,計算量再大也只是在重複同一個不夠真的故事。
更大的背景
做了 305 次投資研究後,真正活下來的結論有多少?(2026-06-11)— 305 個實驗、86 個正向、28.2% 站得住;最樸素的結論最耐壓。
2025 的波動率文獻,其實沒有叫你先追 AI 模型(2026-06-09)— 6 篇主流研究整理:問題出在比較規則沒鎖好,不是老模型輸了。
資料說明:VIX 數值取自 yfinance(收盤價 2026-06-22),QLIKE 指標、實驗結果來自 VolPred 內部研究資料庫(experiments/k431、k998、k1014、k1046、k286、k1428),所有數字與圖表均可在對應報告中查閱。
延伸閱讀
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊