每一次失敗都在說同一件事:日頻資料的訊號天花板
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
每一次失敗都在說同一件事:日頻資料的訊號天花板
VIX 最近維持在 18 附近,市場沒有恐慌,也沒有太安靜。這種盤面最容易讓人覺得:如果有更精準的預測工具,此刻應該特別有用。
過去幾週,VolPred 從六篇文章、五個個別實驗加一次研究系統體檢,把這個直覺拿去測。每次的出發點不同,最後回答的是同一個問題。
真正的問題換個方向問: 在日頻資料這個條件下,強化模型到底還有多少空間?
六月十一日的體檢:三百零五次,兩成八通關
最早的一筆記錄在六月十一日(做了 305 次投資研究後,真正活下來的結論有多少?)。
這篇不是個別實驗,是整個研究系統的一次自我清查。2026 年 3 月 14 日到 3 月 22 日之間,同一套流程累積了 305 個實驗。最後被歸到「偏正向結果」的只有 86 個,佔 28.2%。剩下七成出頭的想法,經過長樣本、跨市場、樣本外的嚴格測試後,縮水了。
這個 28.2% 剛好是一個可信度的標誌。一個系統如果九成以上的想法都通關,那你大概要懷疑它在篩什麼。
裡面有兩個修正特別值得記:一個是把「同一天看到訊號、同一天算報酬」這種偷看到未來的設計改掉後,績效明顯縮水;另一個是某個波動控管策略曾一度聲稱能把退休提領安全率從 4% 拉到 8%,更嚴格的交叉驗證跑完,站不住。
修正這些,不是在推翻結論,是在讓結論變得可信。
六月十五、十六日:加更多參數,結果輸更多
兩週後出現了兩篇性質相近的實驗,出發點都是同一個直覺:舊模型太陽春,多一層邏輯應該更準。
六月十五日(看起來很準,卻完全沒用)記錄的是實驗 K998。在 SPY 2005 年到 2026 年、共 5,346 個交易日的資料上,研究者找到一個 GARCH 衍生指標(g proxy),Granger 因果檢定在一天和五天的 horizon 上看起來都很漂亮,F 統計量 66.17,統計上達顯著水準。
問題是,控制 VRP 自身的 lag 之後,g 的係數在所有 horizon 都沒過學術界更嚴格的預測顯著性門檻,t 統計量最高約 2.15,遠不足以支持預測宣稱。樣本外 R² 也是負的。把它設計成交易策略,Sharpe 是 -1.06,而什麼都不做的 naive baseline 是 +0.85。
統計上看起來有關係,預測時就是沒用。
六月十六日(把 GARCH 改聰明反而更笨)則是實驗 K431 的 v2 報告。這次試的是把 GARCH 加上平滑切換機制(STGARCH),讓模型能感知市場是在恐慌期還是平靜期。三種版本:用 VIX 判斷、用當天報酬幅度、用滯後波動率。OOS 期間 2023 至 2024 年,502 個交易日。
結果是這樣的:
| 模型 | QLIKE | 比 GJR 差多少 |
|---|---|---|
| GJR-GARCH(1,1) | 0.5588 | 基準 |
| STGARCH-lagvol | 0.5870 | +5.05% |
| STGARCH-VIX | 0.5882 | +5.26% |
| STGARCH-|ret| | 0.5955 | +6.56% |
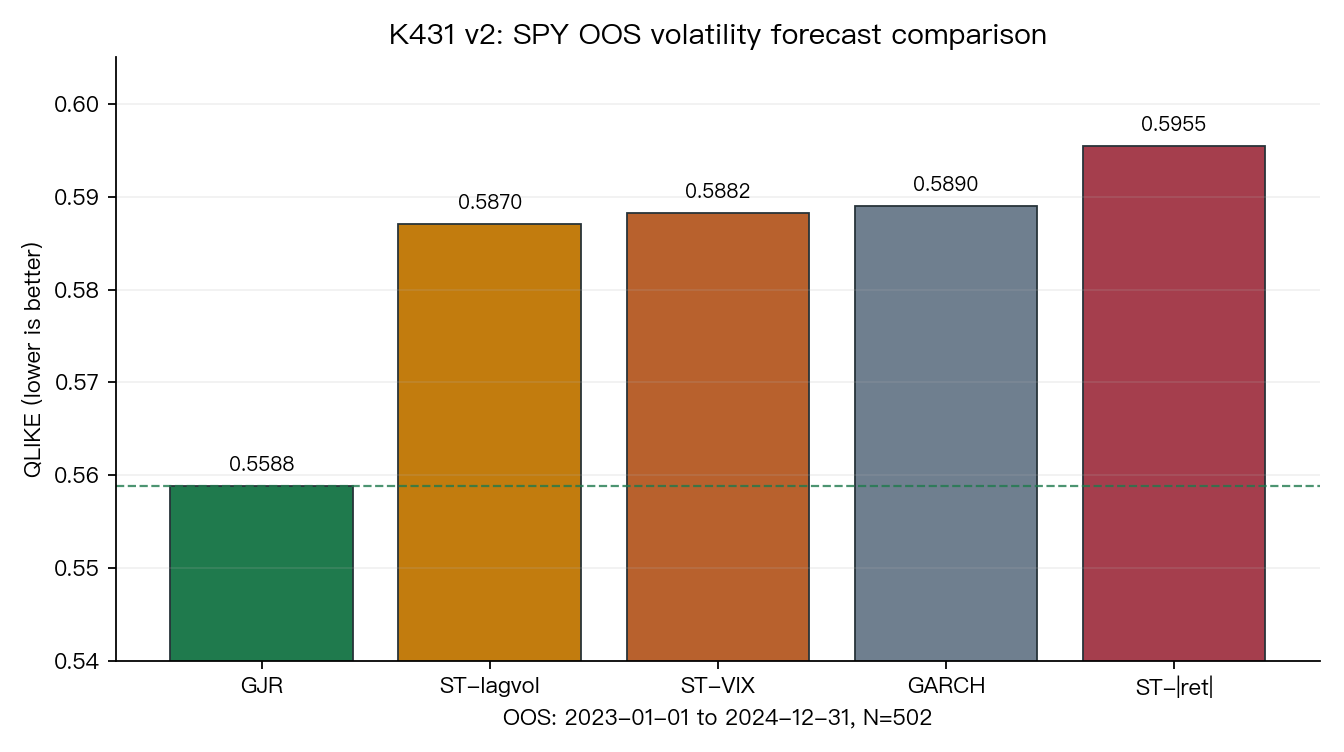
GJR-GARCH 比標準 GARCH 多了一個參數:壞消息導致的波動比好消息更大(槓桿效應)。三種 STGARCH 多估了 4 個參數,換來的是 DM 檢定全輸(p 值 0.001 到 0.014)。
六月十九日:把更多特徵塞進去,模型反而更搞不清楚
六月十九日(幫風險模型多裝一大包聰明指標,結果反而更差)延伸的是另一個思路:既然單一特徵不夠,那多塞一整包呢?
實驗 K1014 用 SPY 2005 至 2026 年資料,OOS 從 2019 年起,共 1,824 個交易日。把波動加速度、跳躍強度、下行占比、隱含波動率與已實現波動的差距全部丟進 HAR。
| 模型版本 | QLIKE(越低越好) |
|---|---|
| 基準版(三尺度歷史波動) | 1.283 |
| 精簡挑選版 | 1.483 |
| 加強版(全塞) | 1.627 |
最簡單的版本排第一,加了特徵之後誤差從 1.283 惡化到 1.627。這一整包新增特徵裡,真正有訊號的只有一個(隱含波動率與已實現波動的差距),但和另外五個一起塞進去,訊號被稀釋掉了。係數跳動,模型不知道該信哪個。
六月二十三日:連骨架都嵌進去的神經網路,還是輸了
六月二十三日(把老模型塞進 LSTM,為什麼預測反而更差?)是這個系列裡最有野心的嘗試。
做法更進一步:把舊波動率公式的骨架直接寫進 LSTM,讓神經網路從有金融邏輯的起跑點開始學,少走冤枉路。
SPY 和 QQQ,OOS 從 2021 年 1 月到 2026 年 5 月,各 1,348 個交易日。
主評分(QLIKE):SPY 新模型 3.451,基準 1.730;QQQ 新模型 3.292,基準 1.746。誤差分別大了 99% 和 89%。
唯一讓新模型「看起來」有進步的指標是平方誤差:SPY 改善 14.7%,QQQ 改善 6.0%。但平方誤差對波動率預測本來就比 QLIKE 鈍很多。在重要的那把尺上,新模型全面退步。
六月二十八日:換到日內高低價代理,HAR 依然沒改善
昨天的實驗(日頻波動率,HAR-RV 贏不了 GARCH:60 場跨資產對戰的紀錄)是整個脈絡的收尾。
K188 改變了角度:不再測「加更多參數」,而是測「換更好的波動率代理」。把收盤價算出的波動換成 Parkinson、Garman-Klass、Rogers-Satchell 估計量,這些用日內高低價算出來的代理,理論上比收盤價包含更多資訊。再用三個 HAR 變體對打 GJR-GARCH,五資產 × 四代理 × 三模型,共 60 場。
| 勝者 | 場數 | 佔比 |
|---|---|---|
| GARCH 勝 | 31 | 51.7% |
| HAR 勝 | 1 | 1.7% |
| 平手 | 28 | 46.7% |
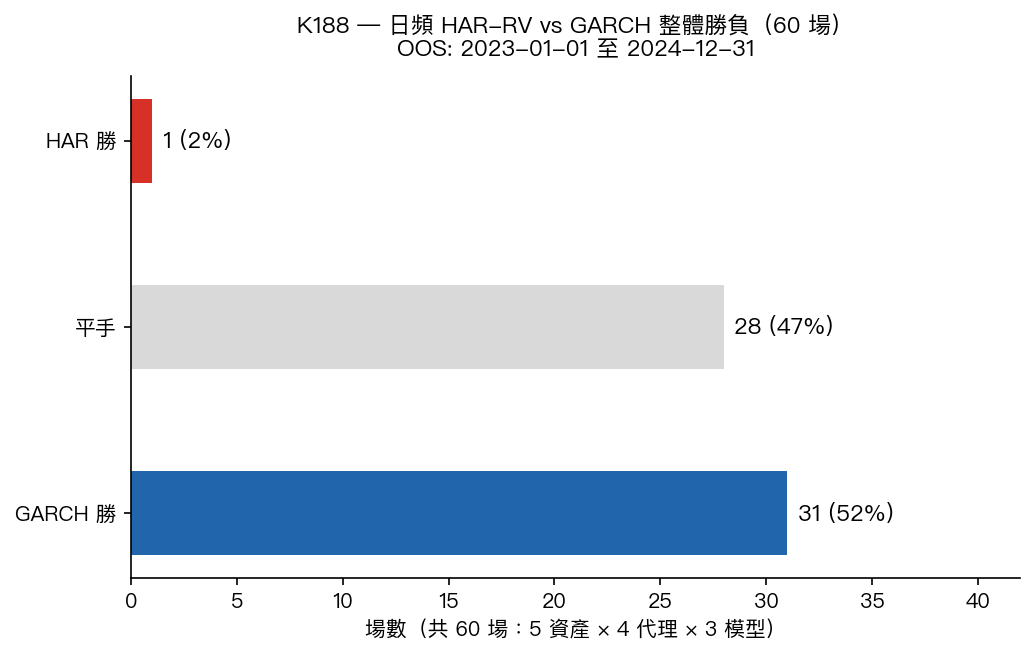
換了更好的代理,HAR 不但沒改善,GARCH 反而勝出更多。用 Parkinson / Garman-Klass 時,GARCH 每組 3-4 勝,因為 GARCH 對代理噪音的處理方式更簡潔。
HAR 唯一的 1 勝是 SPY × HAR-X(c2c):在美股流動性最高的標的上,加入 VIX 作為外生輸入,勉強在收盤價代理上贏了一場。這個組合極窄。
這些失敗說的是同一件事
這六篇橫跨六月十一日到六月二十八日,說的是同一件事,但從不同方向切進去。
Granger 顯著但嚴格預測門檻不過(K998)、STGARCH 加了四個參數輸 5-6.5%(K431)、特徵包讓誤差退步 27%(K1014)、骨架嵌進 LSTM 後 QLIKE 惡化 99%(深度學習)、換了日內高低價代理 HAR 依然 1:31(K188),這些失敗的機制各不相同,但共同的起點是一樣的:
日頻資料的訊噪比很低。已實現波動本身就是個粗糙的估計,可以被線性結構捕捉的訊號有限。到了那個上限,加特徵、加層次、換結構,只是在把噪訊打磨得更漂亮,不會讓預測變準。
HAR 在高頻(五分鐘 RV)的主場是真的強,因為五分鐘 RV 直接量測盤中每一分鐘的波動,訊號濃度高。搬到日頻,燃料不夠,分解就失去意義。
這不是說日頻波動率預測沒有空間。這 17 天的記錄一起說的是: 空間到底在哪裡,要從資料的訊噪比去理解,不是從模型的複雜度去想。 複雜模型幫你找的,大部分是噪訊裡的巧合。
對一般投資人的意思:如果你在評估一個新的風險預測工具,比「它用的模型有多新」更值得先問的問題,是它的樣本外期間是什麼時候、用的評估指標是 QLIKE 還是 MSE、以及有沒有和 GJR-GARCH 這個樸素的 baseline 認真比過。
本期精選
這六篇文章的發佈日期橫跨 17 天(2026-06-11 至 2026-06-28),記錄了同一個天花板從六個不同角度留下的輪廓。
-
做了 305 次投資研究後,真正活下來的結論有多少?(2026-06-11)— 305 個實驗、28.2% 正向通關;修正偷看未來讓績效縮水,更嚴格的驗證讓聲稱更可信。
-
看起來很準,卻完全沒用:一個 GARCH 指標的預測失敗紀錄(2026-06-15)— K998,g proxy Granger F=66.17 達統計顯著水準,但嚴格預測門檻未過,Sharpe -1.06;Granger 顯著從來不等於可以預測。
-
把 GARCH 改聰明反而更笨:三種 STGARCH 在 SPY 上全輸給老派 GJR(2026-06-16)— K431 v2,多四個參數換來 QLIKE 惡化 5.05–6.56%,DM 全輸。
-
幫風險模型多裝一大包聰明指標,結果反而更差(2026-06-19)— K1014,六個新特徵讓 QLIKE 從 1.283 退步到 1.627;係數打架,訊號被稀釋。
-
把老模型塞進 LSTM,為什麼預測反而更差?(2026-06-23)— SPY QLIKE 惡化 99%,QQQ 惡化 89%;連嵌進骨架都救不回。
-
日頻波動率,HAR-RV 贏不了 GARCH:60 場跨資產對戰的紀錄(2026-06-28)— K188,五資產 × 四代理 × 三模型,GARCH 勝 31:HAR 勝 1,換日內高低價代理仍讓 GARCH 優勢更大。
資料說明:各實驗 K 編號對應 VolPred 研究資料庫,QLIKE / DM 統計量可在各實驗原始報告查閱。VIX 水位參考發文時 yfinance 讀數(約 18.4)。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊