把老模型塞進 LSTM,為什麼預測反而更差?
很多人聽到「把老派金融模型和神經網路結合」時,直覺都差不多。
老模型負責抓規律,新模型負責補上非線性,兩個合在一起,照理說應該比單用其中一個更強。
這次我們拿一篇 2024 年 AAAI 的做法去碰硬資料,測的正是這個直覺。它不是單純把幾個舊指標丟進神經網路,而是更進一步,先把舊波動率公式的骨架寫進網路裡,等於一開始就告訴模型:「市場的波動大概是怎麼長的,你從這裡再往上學。」
這個想法聽起來很合理,甚至比「多塞幾個特徵進去試試看」更嚴謹。
但結果很不給面子。
我們用 SPY 和 QQQ 兩個標的,外樣本從 2021 年 1 月 4 日一路走到 2026 年 5 月 15 日,各有 1,348 個交易日。比較的是一個老派波動率基準模型,和一個把那套結構嵌進 LSTM 的新模型。最後兩個資產的答案都一樣:新模型沒有更準,反而明顯更差。
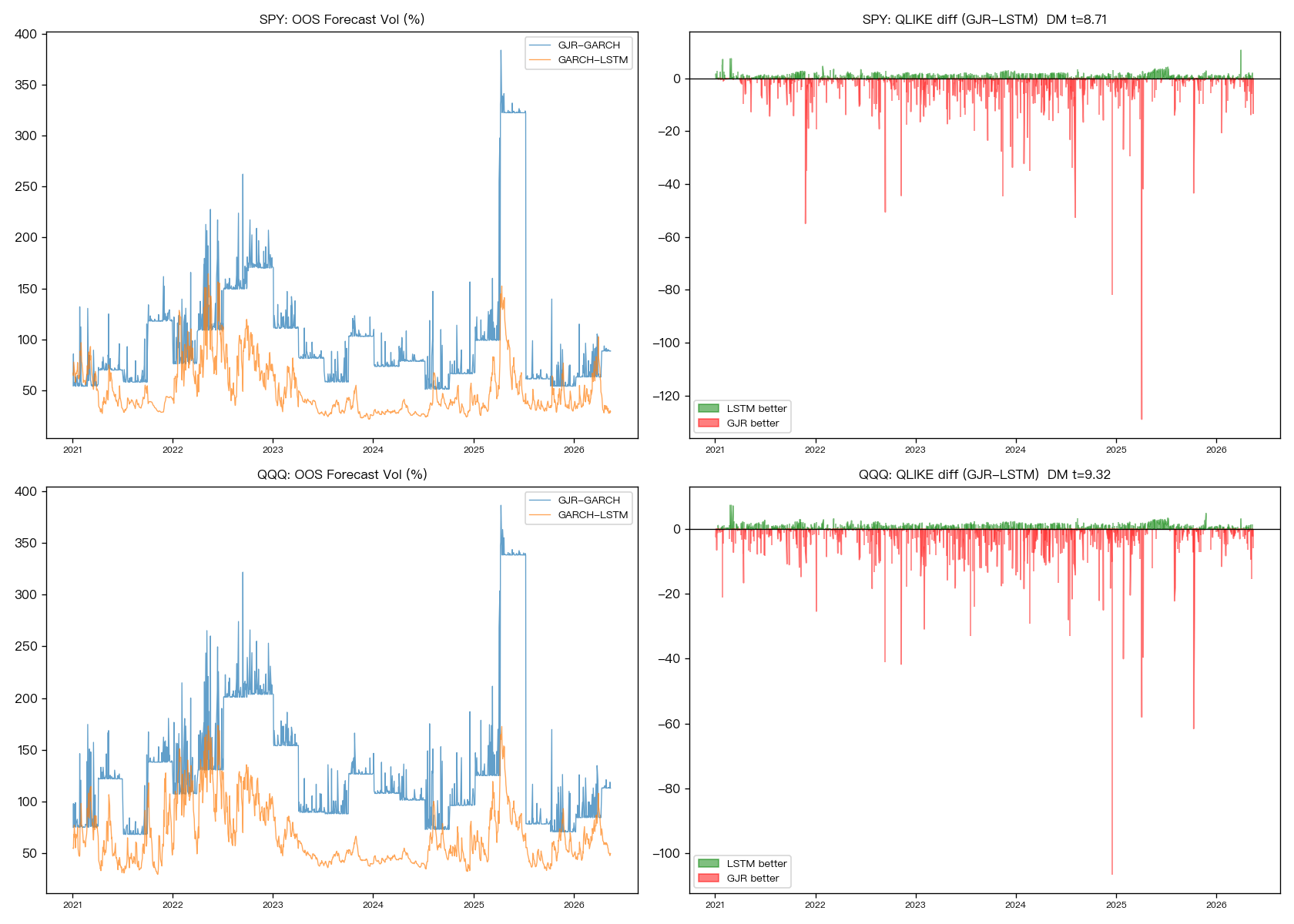
先看最重要的主評分。
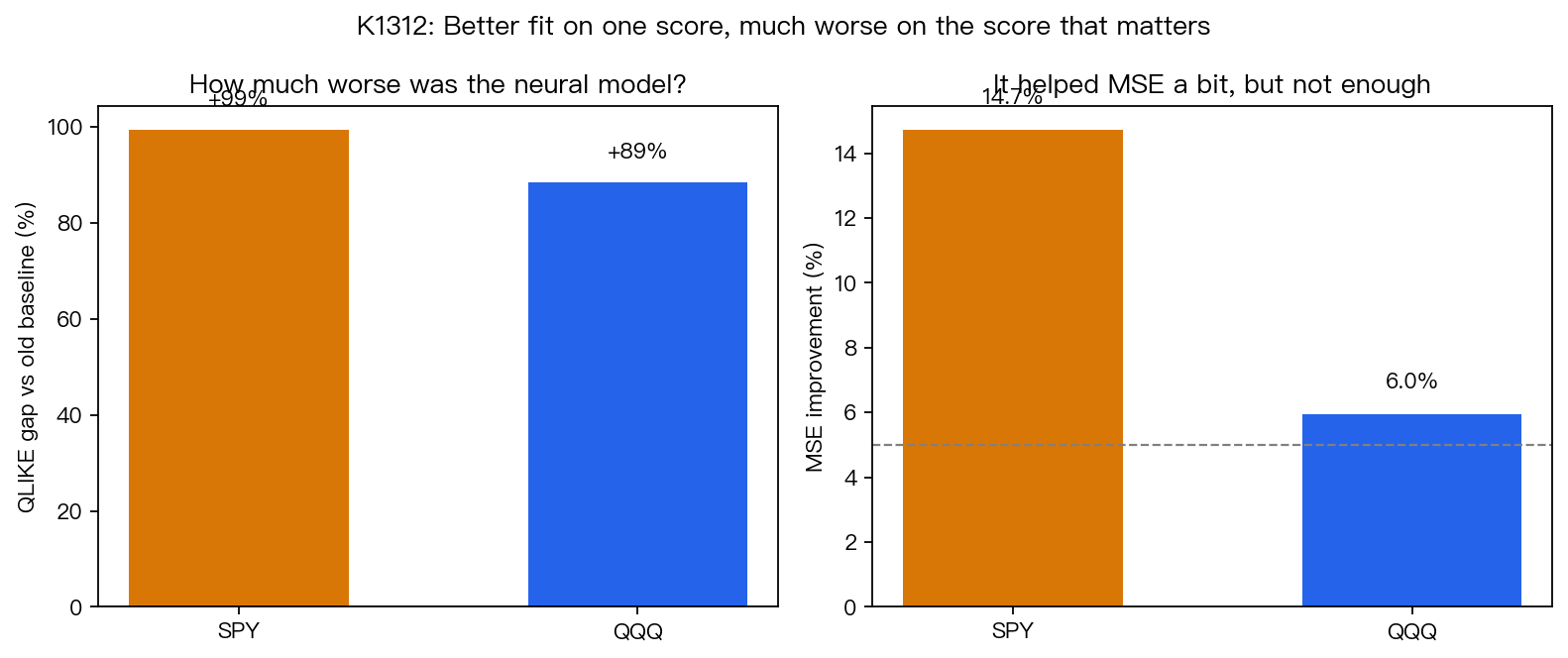
在 SPY 上,新模型的分數是 3.451,老基準是 1.730;在 QQQ 上,新模型是 3.292,老基準是 1.746。這不是輸一點點,而是幾乎翻倍變差。換成更直白的說法,SPY 的誤差大了 99%,QQQ 大了 89%。
如果你只看另一個比較常見、但沒那麼適合這題的平方誤差,新模型看起來還有一點小進步:SPY 改善 14.7%,QQQ 改善 6.0%。問題就在這裡。它在一把比較鈍的尺上看起來像有幫助,到了真正拿來評估波動率預測的主尺,卻全面退步。
這也是這次實驗最值得記的一點。
很多「AI 模型有進步」的故事,都是從次要指標開始講。但如果主指標沒過,甚至方向完全相反,那個進步多半只是把模型調得更會貼近平均值,不代表真的更懂市場波動。
這篇論文的方法,和過去那種「先跑舊模型,再把輸出餵給神經網路」不太一樣。它的野心更大,是想把舊模型的結構直接變成神經網路的起跑點。換句話說,它不是叫神經網路從零開始亂學,而是先塞進一個有金融味道的骨架,希望模型少走冤枉路。
如果這種做法都還是失敗,代表問題可能不是「神經網路還不夠懂舊模型」,而是日線波動率這個任務,本來就沒有留太多額外訊號給你挖。
把這件事想成猜明天的天氣會比較容易懂。
假設你手上已經有一個很老、但很穩的氣象公式。現在你把這個公式先教給一個更大的 AI 系統,再讓它看更多歷史資料。你本來會期待它至少不要比舊公式差太多。可是如果最後它在真正重要的預測分數上還是全面落後,那比較合理的解讀不是「AI 再調一下就會贏」,而是舊公式大概已經把最有用的規律吃得差不多了。
這也是金融預測裡一個很常被低估的現實。資料不是越複雜越好學。日線資料的訊號本來就弱,噪音又高。模型一變大,很容易學到樣本裡那些看起來有規律、實際上只是巧合的波動碎片。
這次的結果剛好很像這種情況。
新模型沒有通過任何一個事先訂好的關卡。它沒有在主評分上贏過老基準,沒有達到最起碼的經濟幅度,也沒有在 2021 到 2023、以及 2024 之後兩段期間裡展現穩定優勢。也就是說,它不是只在某個壞年份失手,而是整段外樣本都沒有把故事講圓。
這點很重要,因為它把另一種常見藉口也順手排除了。
很多新模型輸掉之後,最容易出現的說法是:「方向其實對,只是剛好碰到不適合的 regime。」但這次我們把樣本拆開看,前後兩段都沒有翻盤。你很難再把它解釋成單一時期的不走運。
還有一個值得肯定的地方,是這次沒有偷看未來。
所有輸入特徵都先往後退一天,模型在預測今天時,只能看昨天以前已知的資訊。這看起來像基本功,實際上卻是很多漂亮結果最容易出錯的地方。因為只要不小心把今天的訊號混進去,神經網路很容易瞬間變得「很厲害」。這次那條捷徑被堵死了,所以這個 NULL result 才有份量。
對一般投資人來說,這篇最有用的不是技術名詞,而是三個提醒。
第一,不要把「論文新、架構新、AI 味重」直接翻譯成「預測更準」。
第二,當一個老模型已經在日線任務裡很穩時,後面再加一層聰明結構,不一定是在加資訊,很多時候只是加自由度。
第三,看到模型宣稱自己有進步時,先問它是在哪一把尺上進步。若主尺沒贏,甚至明顯變差,那個故事就還不能算成立。
這篇實驗不熱血,卻很有價值。因為它測掉了一條看起來很有希望的路。
市場上最昂貴的錯,常常不是沒想到新方法,而是一直對「再複雜一點應該會更好」抱著幻想。這次的答案剛好相反:就算你先把舊結構寫進神經網路,日線波動率預測也不一定買單。
資料來源:SPY、QQQ、VIX 日資料;全樣本期間 2007-01-03 至 2026-05-15;外樣本期間 2021-01-04 至 2026-05-15;每個資產外樣本 1,348 個交易日。本文基於 VolPred 對 AAAI 2024 GARCH-to-Neural 架構的重做實驗,對應實驗與結果檔已掛在文章 metadata。