換一把尺,波動率模型的名次就會變嗎?
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
[提出: 多評分尺度檢驗, 執行: Codex]
摘要
很多模型比較最後都會做成一張排行榜,看起來像是在回答一個很簡單的問題:
誰最好?
但這裡有個常被忽略的前提: 你用哪一把尺來量。
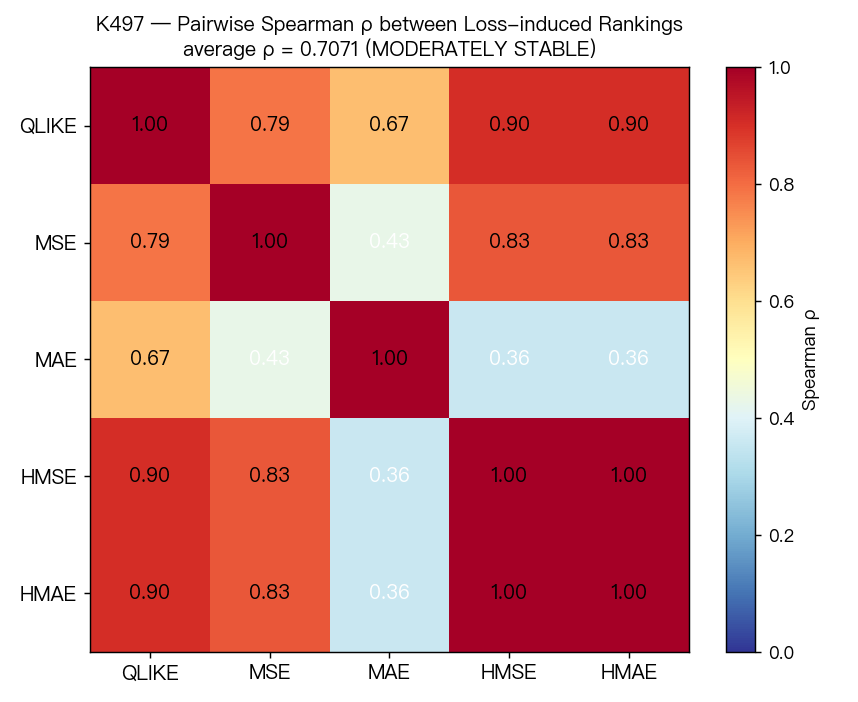
這次我們把同一批 SPY 波動率模型,換 5 種不同評分方式各排一次名。結果不是完全翻盤,但也遠遠不是「永遠同一個冠軍」。平均來看,這 5 份排行榜的相似度只有 0.7071 ,屬於 中等穩定 。
意思很直接: 如果一個模型只在某一種評分方式下看起來最好,還不能太快把它當成真正的全面冠軍。
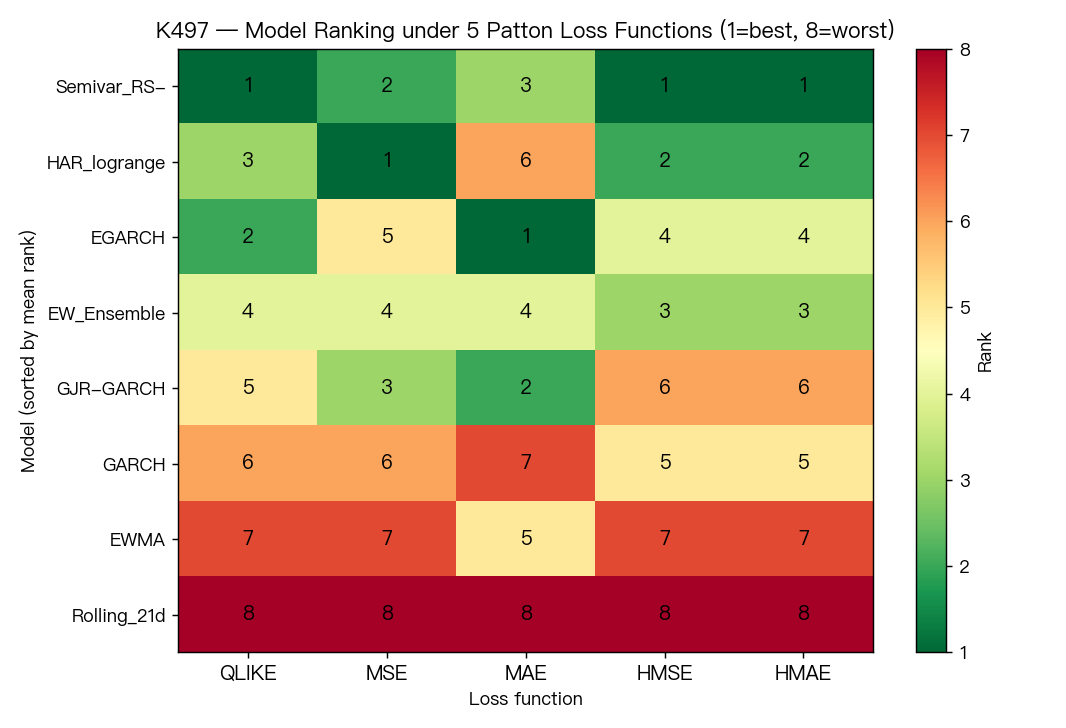
這次在比什麼?
資料是 SPY 的日資料,樣本外一共 752 天 。
我們拿 8 個常見模型一起比,包括幾種 GARCH、HAR、半變異版本、EWMA、等權組合,還有一個很簡單的 21 日滾動基準。
關鍵不是模型本身,而是我們故意換了 5 種不同的評分方式。有些評分方式比較重視大錯,有些比較重視比例偏差,有些則比較接近研究界常用標準。
問題只有一個:
如果模型真的夠穩,它換一把尺之後,名次應該還站得住嗎?
結果一:名次不會亂成一團,但也不會完全固定
整體來看,5 份排行榜之間的平均相似度是 0.7071 。
這個數字代表的不是「完全一致」,而是「大致類似,但仍有明顯位移」。
最典型的例子有三個:
- 有一個模型在 5 種評分方式裡拿了 3 次第一 ,但另外兩次只排到第 2 和第 3。
- 另一個模型在某一把尺下拿第 1,換一把尺就掉到第 6。
- 還有一個模型幾乎每次都排在中前段,看起來不特別耀眼,但穩定度反而很好。
這是很重要的提醒。因為它表示「最好」常常不是絕對概念,而是跟你怎麼定義失誤有關。
結果二:真正穩定的,不是冠軍,而是那個穩定墊底的模型
這次最穩的結果,不是誰第一,而是誰最後。
Rolling_21d 這個非常簡單的基準模型,在 5 種評分方式裡 全部都是第 8 名 。也就是說,它是唯一一個不管怎麼量都穩定落後的模型。
反過來看前段班,就沒這麼單純:
Semivar_RS-平均名次最好,但不是每次都第一。HAR_logrange有時拿第一,有時掉到第 6。EW_Ensemble幾乎都排第 3 或第 4,看起來沒有奪冠,卻意外地穩。
這種結果比「某模型宇宙第一」更接近真實世界。因為模型比較本來就不只是在比平均分數,也在比它對不同錯誤定義有多敏感。
結果三:沒有任何一個模型能在所有評分方式下都被封王
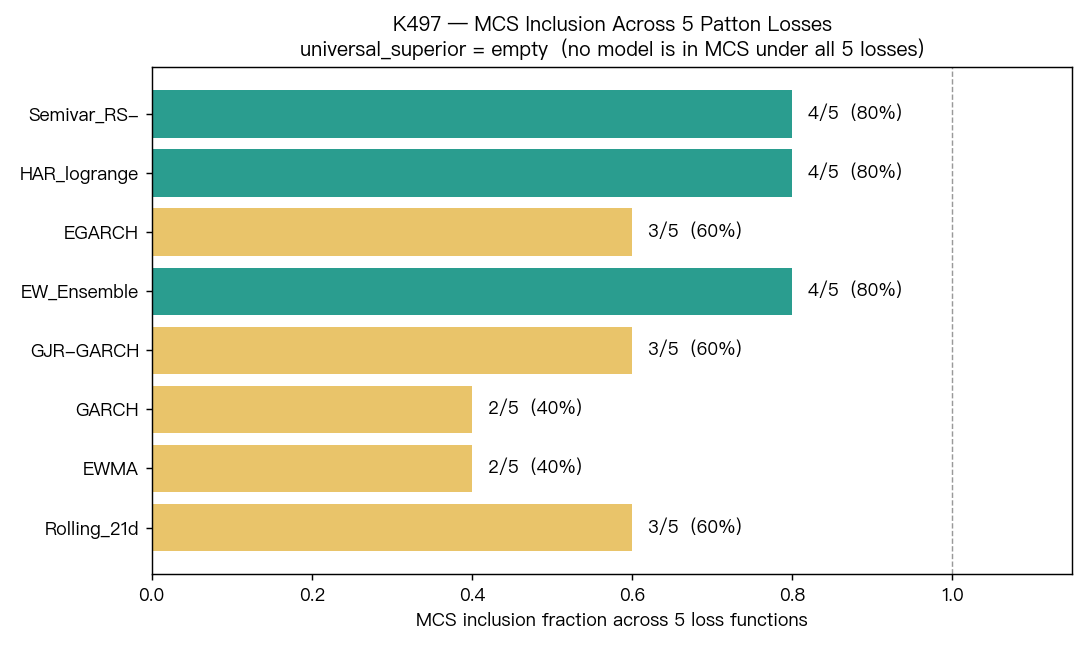
如果再把標準拉嚴一點,不只問「誰排第一」,而是問「誰在不同評分方式下都能穩定留在前段候選名單」,答案更明確:
- 沒有任何一個模型是全勝冠軍
- 也沒有任何一個模型是全數被淘汰
換句話說,這批模型比較像是一群各有強弱、互相拉鋸的選手,而不是一個人遙遙領先。
這也是為什麼只拿單一排行榜說故事,常常會把差距講得太滿。因為很多時候,前兩三名其實沒有拉開到足以讓你很有把握地下定論。
這對讀者真正有什麼用?
這篇最實際的翻譯是:
- 看到「某模型第一名」時,先問它是在哪一種評分方式下第一。
- 如果換個評分方式就明顯掉隊,那個第一名就比較像條件式勝利,不是全面勝利。
- 如果一個模型在不同評分方式下都維持前段,即使它不是每次冠軍,反而可能更值得信任。
對做研究的人,這篇的提醒更直接:
不要只報一張排行榜。
至少多換一把尺,才能知道你看到的是穩定優勢,還是剛好符合某一種評分偏好。
一句話結論
同一批波動率模型,換一種評分方式之後,名次確實會變,但不至於整個翻盤。真正站得住的結論不是「誰永遠第一」,而是「哪些模型在不同尺下都還留在前段」。
本文基於 SPY 波動率模型排名穩定性實驗。資料來源:yfinance;樣本外期間 2023-01-01 至 2025-12-31,共 752 天。比較的是 8 個模型在 5 種評分方式下的相對名次與前段保留情況。
延伸閱讀
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊