跑一萬次模擬,不一定比老方法更懂風險
很多人一聽到「模擬一萬次」,直覺就會覺得這一定比老方法更準。
畢竟聽起來比較先進,算得也比較大陣仗。
但這次測試得到的答案剛好相反:在估「明天最糟可能跌多少」這件事上,跑很多次模擬的方法不只沒有明顯更好,反而常常輸給兩種更樸素的做法。
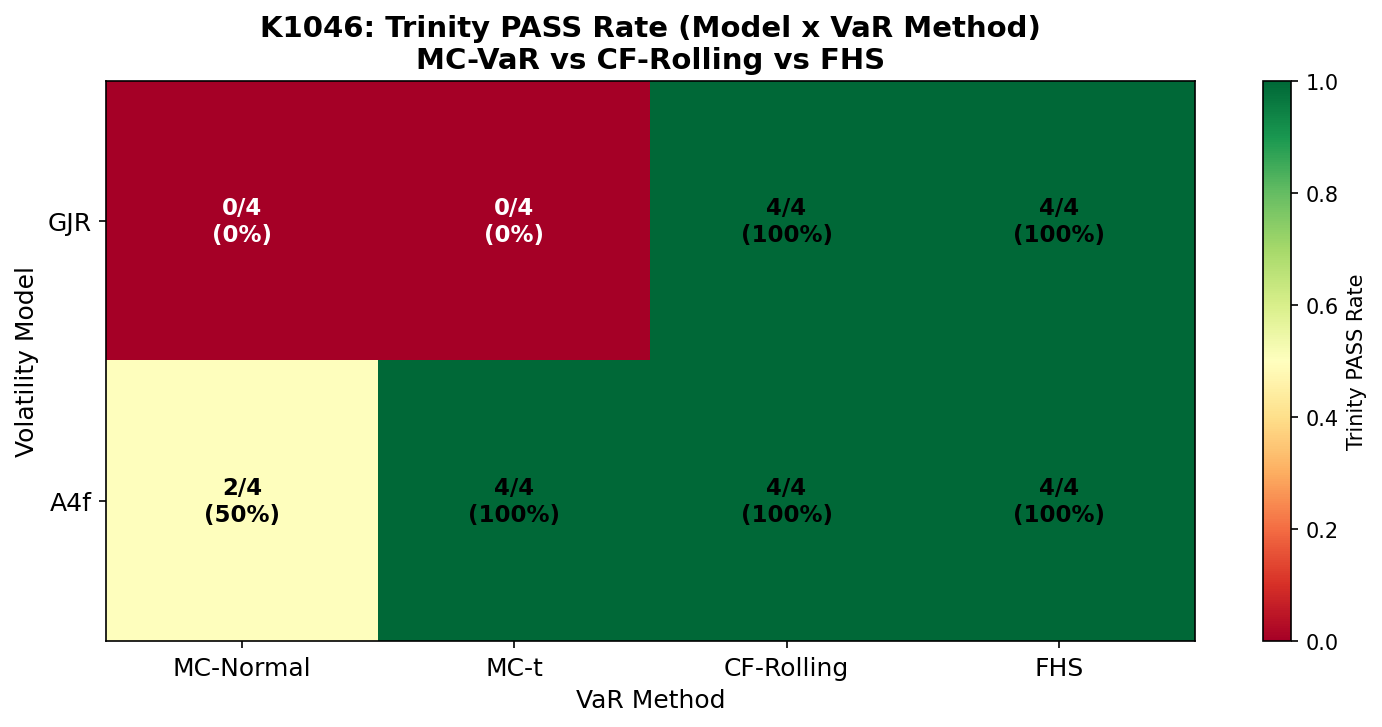
先看結果
這次拿 4 種風險估計方法做比較,搭配 2 種不同的市場風險讀法,標的是 SPY 和 QQQ,期間從 2019 年一路測到 2026 年。
整體結果很乾脆:
- 常態版模擬: 8 組只過 2 組
- 厚尾版模擬: 8 組過 4 組
- 另外兩個直接根據近一年市場痕跡估尾端的方法: 8 組全過
換句話說,問題從來不只是你跑了幾次,而是你對市場尾端長什麼樣,想像得對不對。
為什麼模擬很多次,還是可能輸?
因為模擬次數再多,也只是把你原本的假設放大很多遍。
如果你一開始就把市場想得太平靜、太規則、太像課本,那你跑一萬次、十萬次,本質上都還是在重複一個不夠貼近現實的故事。
這次最明顯的例子,就是用比較傳統的平滑假設去跑模擬。它在最極端的小機率風險區間,實際出錯率往往接近目標值的兩倍。也就是說,它口中的「很少發生」,現實裡根本沒有那麼少。
問題不只在尾巴,也在波動本身有沒有估準
這次也看到另一個更實用的差別。
同樣是模擬,如果方法只看價格自己的歷史,表現就不夠穩;但如果把像 VIX 這種市場緊張程度的線索一起納進來,表現就明顯改善。
意思很簡單:
你連今天市場有多緊張都沒先抓準,後面再怎麼精緻模擬,效果都有限。
所以很多時候,真正該先升級的不是模擬引擎,而是你對當下波動狀態的理解。
反而更穩的,是兩種比較「不搶戲」的方法
這次最穩的兩種方法有一個共同點:它們都比較少替市場預設形狀,而是更直接地去讀最近一年市場自己留下來的極端波動痕跡。
你可以把它理解成兩種不同版本的同一個態度:
- 少一點先入為主
- 多一點尊重最近真的發生過什麼
結果就是,這兩種方法在這輪測試裡全部過關,而且不太受模型選擇影響。
這是一個很好的提醒。風險管理很多時候不是比誰最炫,而是比誰比較不會先把市場想錯。
對一般投資人有什麼意思?
最實用的意思有三個。
第一,不要被「算很多次」這件事本身說服。
計算量大,不等於結果更可靠。真正要問的是:它到底是不是在重複一個不夠真的假設。
第二,比起一直追新方法,先看模型有沒有跟上市場狀態。
如果工具連最近風險升高這件事都反應得慢,再複雜的模擬也只是把慢反應包裝得更厲害。
第三,風險估計不是選最炫的武器,而是先排除那些會穩定低估風險的做法。
這次測試最有價值的地方,不是宣布哪個方法從此封王,而是告訴你:有些看起來比較高級的方法,在你真正需要它之前,未必值得你多付那麼多信任。
一句話結論
這次最值得記住的不是「模擬不好」,而是: 如果底層假設不夠真,跑再多次也不會讓風險估計變可靠。
資料來源
本文來自 VolPred 的一份風險模型測試,資料來源為 yfinance,標的為 SPY 與 QQQ,評估期間自 2019-01-02 起,各約 1,827 個交易日。