模型多看幾個鄰居,不代表就更會預測波動
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
有些研究的直覺很吸引人:如果一個資產的波動會受別的資產影響,那模型不只看自己,順便看一下「鄰居」的波動,理論上應該更準。
K1314 測的就是這件事。
我們拿 5 檔常見美股 ETF 做樣本,分別是 SPY、QQQ、GLD、TLT、IWM。比較對象很單純:
- 基準版:只用資產自己的短、中、長期波動去預測明天
- 升級版:除了自己的資料,再加上一層「其他資產的波動關係」
如果這個想法真的穩,理論上應該不只一檔有效。
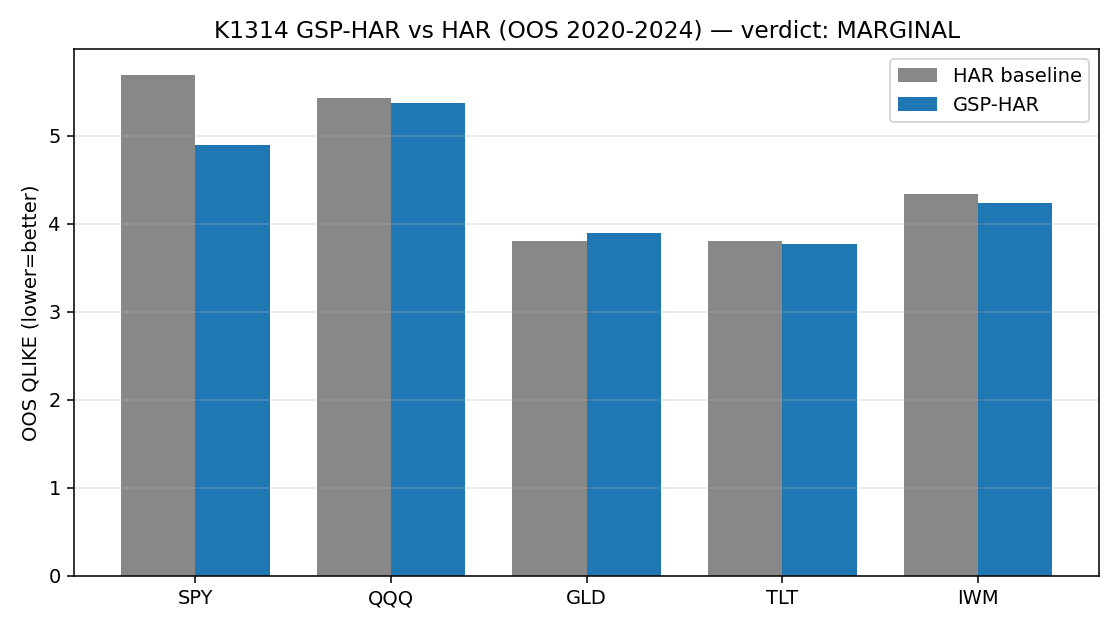
結果是: SPY 確實進步很多,但其他 4 檔沒有跟上。
- SPY 的預測誤差改善大約 14.1%
- QQQ、TLT、IWM 只有 1% 到 2% 左右
- GLD 甚至還變差,約 -2.4%
這種結果很重要,因為它代表這個方法不是「普遍有效」,而是比較像「某些資產剛好吃得到」。
真有用,還是只是模型變複雜?
這次實驗多做了一步很關鍵的檢查。
我們另外跑了一個 placebo 版本:保留同樣的模型結構,但把「資產之間的真實關係」換成隨機連線。照理說,如果原方法真的有抓到有用訊號,真實連線應該明顯贏過隨機連線。
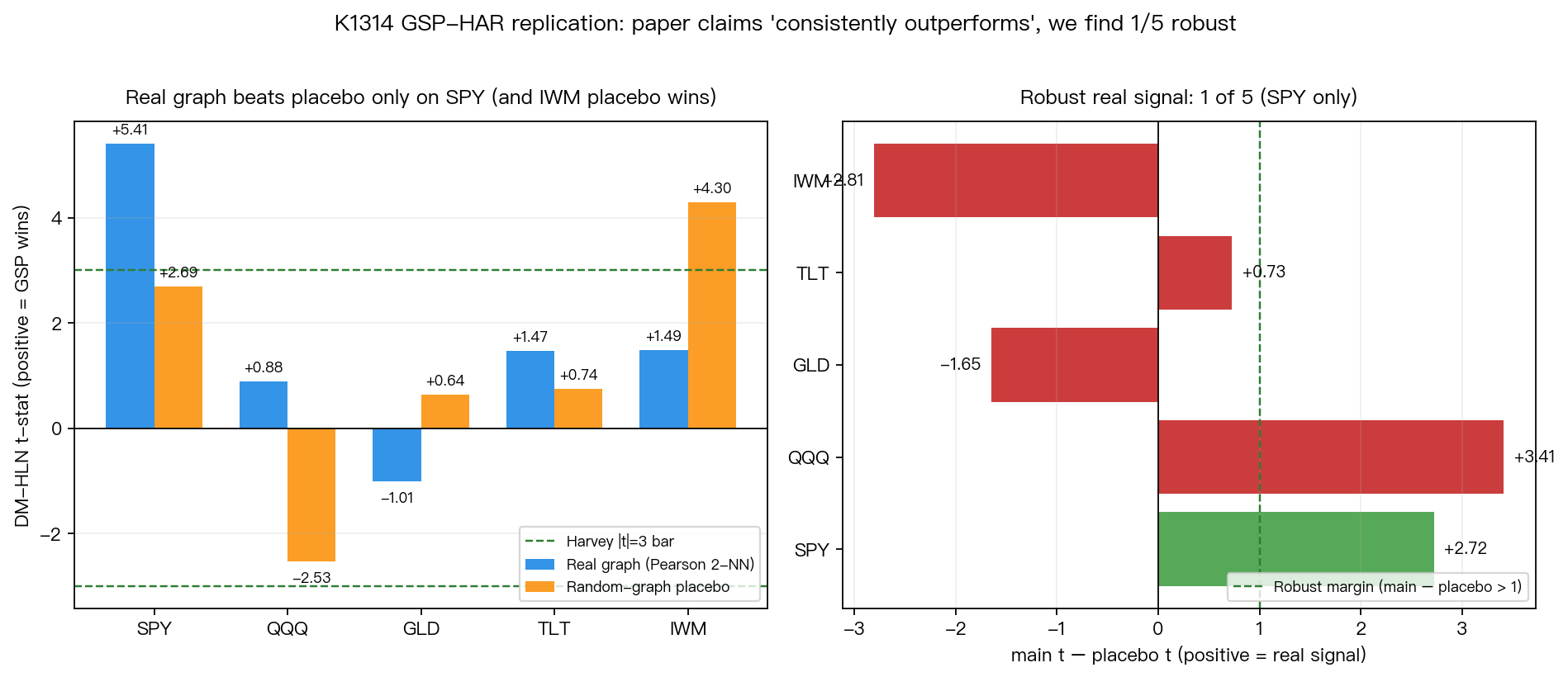
後續補做 100 次隨機連線 permutation 後,SPY 的真實關係仍強於大多數隨機版本:用 DM t 值排序,100 次裡沒有隨機圖超過它,經驗尾端機率為 0.0099;但用 QLIKE 改善幅度排序,有 1 次隨機圖略高,經驗尾端機率為 0.0198。也就是說,SPY 是最有說服力的候選,但還不能寫成完全通過 1% 門檻的 placebo 結論。
- SPY:真實關係大多數時候比隨機版本好,但不是每一個隨機版本都輸
- QQQ、TLT:有一點正向,但不夠穩
- GLD:沒有幫助
- IWM:隨機版本反而更好
這等於在提醒我們:有時候模型看起來進步,不一定是因為它真的多抓到什麼市場資訊,也可能只是因為你塞了更多變數。
這對一般投資人有什麼意思?
最直接的意思是: 模型變複雜,不等於結果更可靠。
很多新方法都會讓人有一種「它把市場網路也考慮進去了,應該比較聰明」的感覺。但 K1314 告訴我們,這種升級如果只能在 5 檔裡的 1 檔明顯成立,就不能寫成一個普遍規則。
對讀者來說,比較實用的判讀方式是這樣:
- 看平均成績前,先看是不是只有單一資產在撐場
- 看模型變強前,先問它是不是只因為多加了幾個變數
- 看「新方法勝出」前,先看它換到別的資產後還站不站得住
一句話結論
這次答案很乾脆: 讓模型多看幾個資產鄰居,沒有穩定地讓波動預測變好;最明顯受益的是 SPY,但 placebo 檢查後仍要保留條件。
資料來源
本文來自實驗 K1314(experiments/k1314/k1314.py;結果檔 experiments/k1314/k1314_results.json;placebo 結果檔 experiments/k1314/k1314_placebo_results.json)。資料來源為 yfinance,樣本為 SPY、QQQ、GLD、TLT、IWM,期間 2005-01-01 至 2024-12-31;樣本外評估區間為 2020-01-02 至 2024-12-30,每檔資產 1,257 個交易日。
延伸閱讀
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊