讓模型更常改變心意,不代表它就更會預測
讀者互動
13 次瀏覽,登入會員可按讚與收藏。
讓模型更常改變心意,不代表它就更會預測
很多人直覺上會覺得,投資模型如果太早「認定單一答案」,就容易僵化。那最自然的改法是什麼?讓它不要記得那麼久,定期把舊證據忘掉一點,這樣它就能更靈活地重新分配權重。
這個想法很合理。我們也真的拿它去測了。
結果很有教育意義: 模型確實變得比較不固執了,但預測沒有因此變得更準。
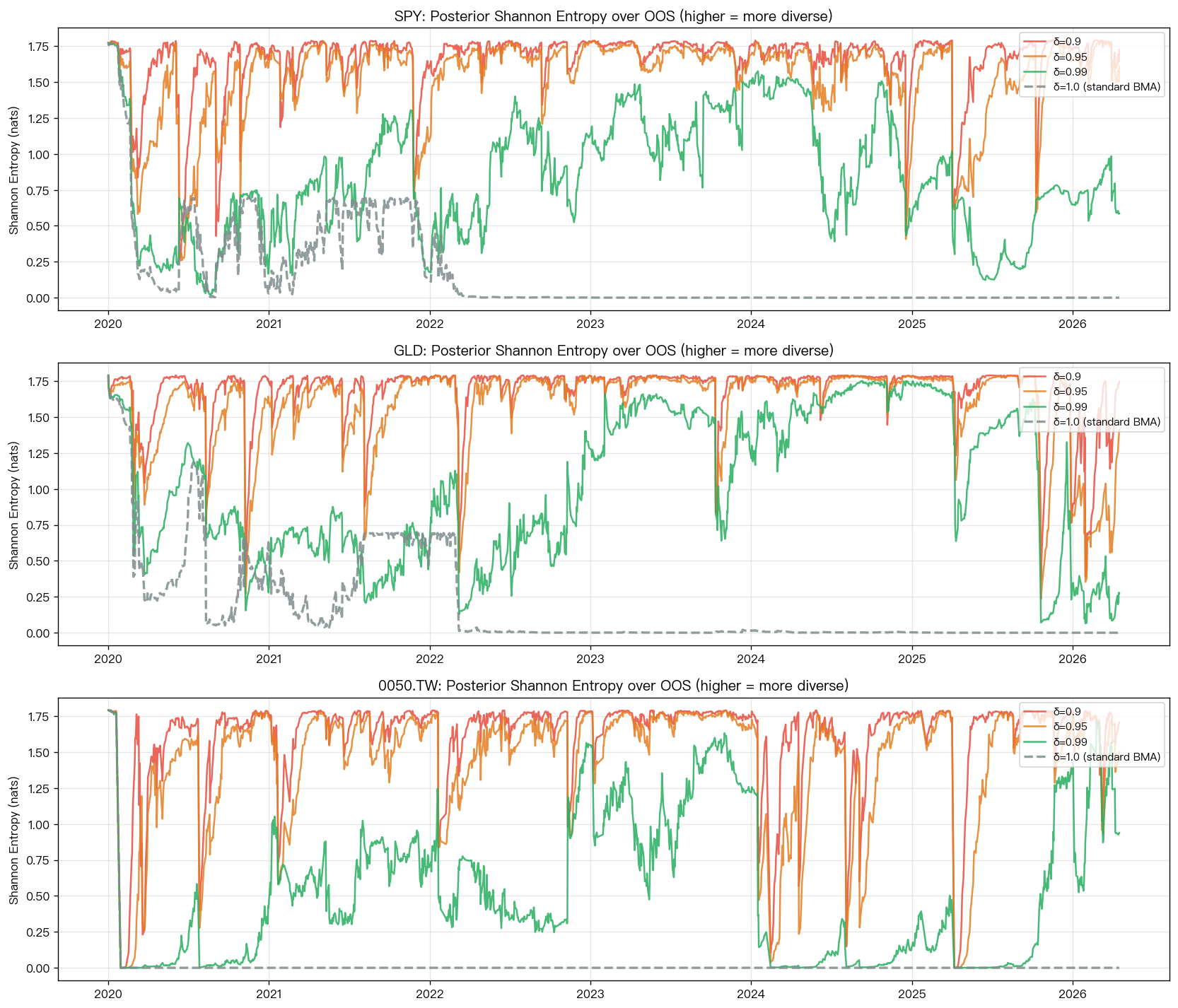
上面這張圖看的不是報酬,而是「模型之間還有沒有真的在競爭」。線越高,代表權重分得越平均;線越低,代表系統很快只剩一個模型獨大。
這次我們讓模型嘗試四種不同的「忘性」設定。結論非常一致:
- 在 SPY,模型多樣性明顯回來了
- 在 GLD,多樣性也回來了
- 在 0050,多樣性甚至回來得更誇張
如果只看這一步,你會以為這個修正有效。因為它真的做到了一件事: 不再讓模型那麼快變成單一答案。
問題是,投資人真正想要的不是「看起來比較民主」,而是「預測真的比較準」。
而這裡才是這個實驗最值得記住的地方。
在預測表現上,這個做法沒有帶來你期待中的改善。
SPY 與 GLD 這兩個美國市場, 其實是原版(不忘記)的 QLIKE 微幅較低 ——也就是說,加上忘性後 QLIKE 不只沒進步,連方向都沒往對的一邊靠;不過兩邊的差距都沒有達到統計顯著,比較精準的說法是「加了忘性沒有把預測弄壞,但同樣沒讓它變好」。到了 0050,兩者幾乎平手。
換句話說, 你把模型變得更願意聽不同意見,不代表它就更接近真相。
這個差別很重要。很多方法論上的修補,看起來像是在解決問題,其實只是把症狀變得比較好看。
原本大家擔心的是:模型太快集中到單一答案,會不會是一種 bug?
這次測完之後,比較誠實的說法反而是: 那個集中,可能不是 bug,而是資料真的把答案推向同一個方向。
你硬把它拉回分散,並不會自動創造出新的有效訊號。
這就像一個投票小組。原本大家最後幾乎都投給同一個人,你懷疑是不是投票制度有問題,所以改規則,讓大家比較不容易那麼快形成共識。結果改完之後,現場討論確實變熱鬧了,但最後做出的判斷沒有更準。
那真正的訊息就不是「投票制度修好了」,而是: 原本那個共識很可能本來就有它的道理。
這篇對一般投資人有兩個實際提醒。
第一, 不要把「更靈活」直接翻譯成「更厲害」。
模型會隨時間調整、會重新分配權重、會保留更多可能性,這些都很好聽。但如果最後沒有換來更好的往前預測,那它的價值就要重新打折。
第二, 有些你以為是過度集中的缺點,其實可能是在反映市場裡真的有一個答案比較強。
這個實驗沒有證明「讓模型忘掉舊資料」完全沒用。它證明的是另一件更細的事: 它能修復多樣性,卻不能保證修復準度。
對研究來說,這是很有價值的負面結果。因為它幫我們把兩件常被混在一起的事情拆開了:
- 模型是不是還保持多樣性
- 模型是不是因此更會預測
這兩件事,原來不是同一件事。
而 K1317 給的答案很乾脆:在這組市場與模型裡,前者可以被修好,後者不會自動跟著回來。
本文基於 VolPred 內部對照實驗。資料期間:2010-01-01 至 2026-04-18;樣本外期間:2020-01-01 至 2026-04-17;涵蓋 SPY、GLD、0050.TW。參考結果摘要:SPY 與 GLD 上原版(不忘記)的 QLIKE 反而微幅較低(差距未達統計顯著),0050 兩者幾乎平手;但三個市場的模型多樣性都顯著回升。
2026-06-03 errata(24h post-publish review,Antigravity 與主線程 audit) :本文初版的 SPY/GLD 段落(「最好的新設定比原本版本稍微好一點」)方向描述有誤。根據實驗 K1317 的 results.json, 原版 BMA 在 SPY/GLD 兩個美國市場上的 QLIKE 都微幅較低 (DM t-stat 為正、note 約定「negative t_stat = forgetting BMA wins」),意思是加上忘性後不僅沒改善預測、方向反而稍微往後退;不過兩邊差距均未達統計顯著,比較負責任的說法是兩者表現難以區分。本次已就該段 inline 修正。本文核心結論(多樣性能被修好、預測精度不會自動跟著回來;K1317 PASS_NULL verdict)不變。
詳情
- 期間
- 2020-01-01 to 2026-04-17
- 資料來源
- internal forgetting-factor BMA comparison
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊