預測輸了,守底線卻贏了:一個模型的分裂成績單
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
預測輸了,守底線卻贏了:一個模型的分裂成績單
2022 年,美股科技股崩跌超過 30%,黃金在通膨衝擊裡逆勢震盪,長期公債跌幅創下四十年紀錄。那一整年市場劇烈抖動,每天早上你不知道波動率會是 1% 還是 3%。
如果有一套模型聲稱能預測「明天大概會動多少」,你會怎麼評分它?
多數人的第一反應是:預測值跟實際值差多遠。差越少,模型越好。
VolPred 的一組實驗給出了一個更分裂的答案: 同一套模型,預測準確度輸得很慘,風險上界卻準得出奇。
兩個問題,兩個答案
實驗用歷史波動率預測模型跑了五年的樣本外驗證,覆蓋 QQQ(那斯達克科技 ETF)、GLD(黃金 ETF)和 TLT(長期公債 ETF)三個性質完全不同的資產。
驗證期:2021 年 1 月到 2026 年 5 月,共 1,355 個交易日。這段期間包含 2022 年的全面崩跌、2023 年的 AI 反彈、2024-2025 年的高波動行情。
這套模型有兩個版本:一個專門「猜中間值」(最普通的點預測),一個專門「設定風險上界」(95%、99% 的極端波動上限)。
結果兩個版本的成績判若雲泥。
成績單一:猜中間值,三個資產全軍覆沒
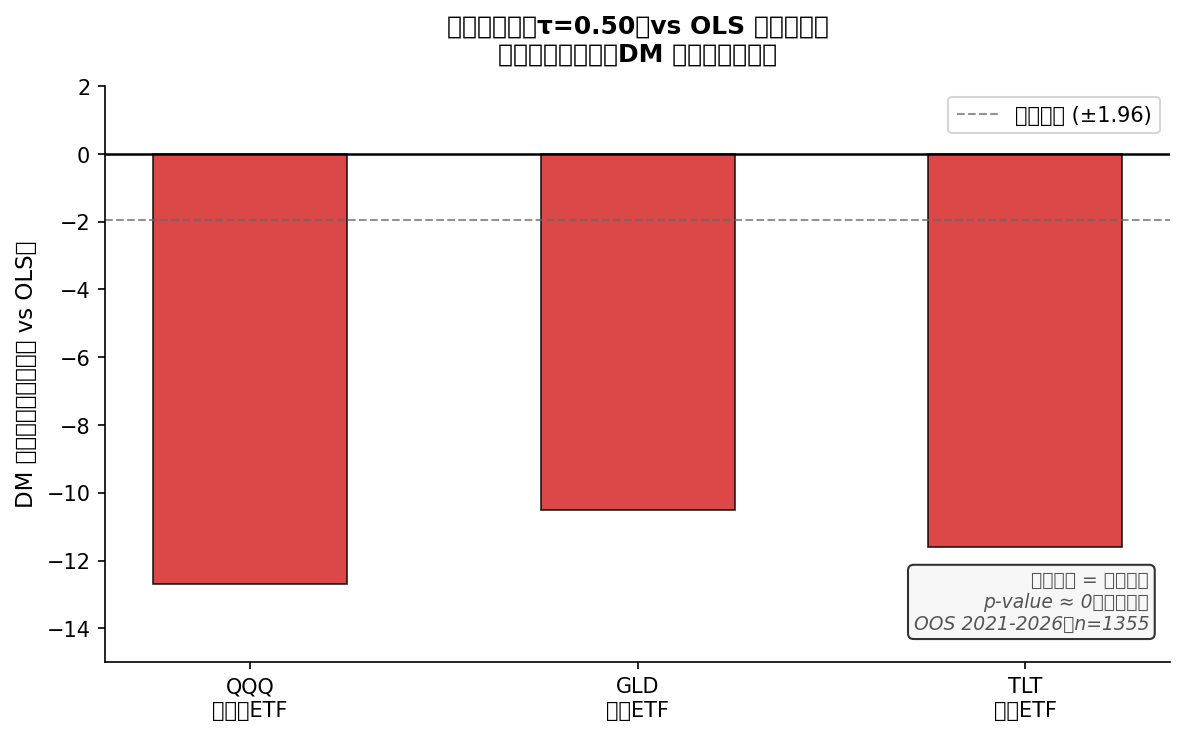
把「用分位數校準法預測波動率中間值」和「用最普通的平均最小化法預測波動率中間值」放在同一段市場比賽,誰贏?
結果如下:
| 資產 | 比較結果 | 預測誤差倍率 |
|---|---|---|
| QQQ(科技 ETF) | 顯著輸 | 高出 44% |
| GLD(黃金 ETF) | 顯著輸 | 高出 64% |
| TLT(長債 ETF) | 顯著輸 | 高出 35% |
三個資產、五年數據、統計 p 值全趨近 0,不可能是巧合。
為什麼會這樣
要理解這個結果,必須先搞清楚分位數校準法在「打哪個靶」。
一般預測模型練的是:讓預測值盡量靠近實際值,用的是「差多少」的標準。
分位數校準法練的是:讓某個比例的實際值落在預測值以下,用的是「高估 vs 低估的不對稱懲罰」。
這兩個目標從數學上就不能同時最小化。就像田徑選手和游泳選手用對方的評分標準去評量,結果必然失真。
把分位數法的預測結果拿去比「誰更能猜到準確的波動率數字」,用的是普通預測的評分標準,分位數法天生就會輸。因為它從來就不是為這個項目訓練的。
成績單二:守風險上界,六個測試全部通過
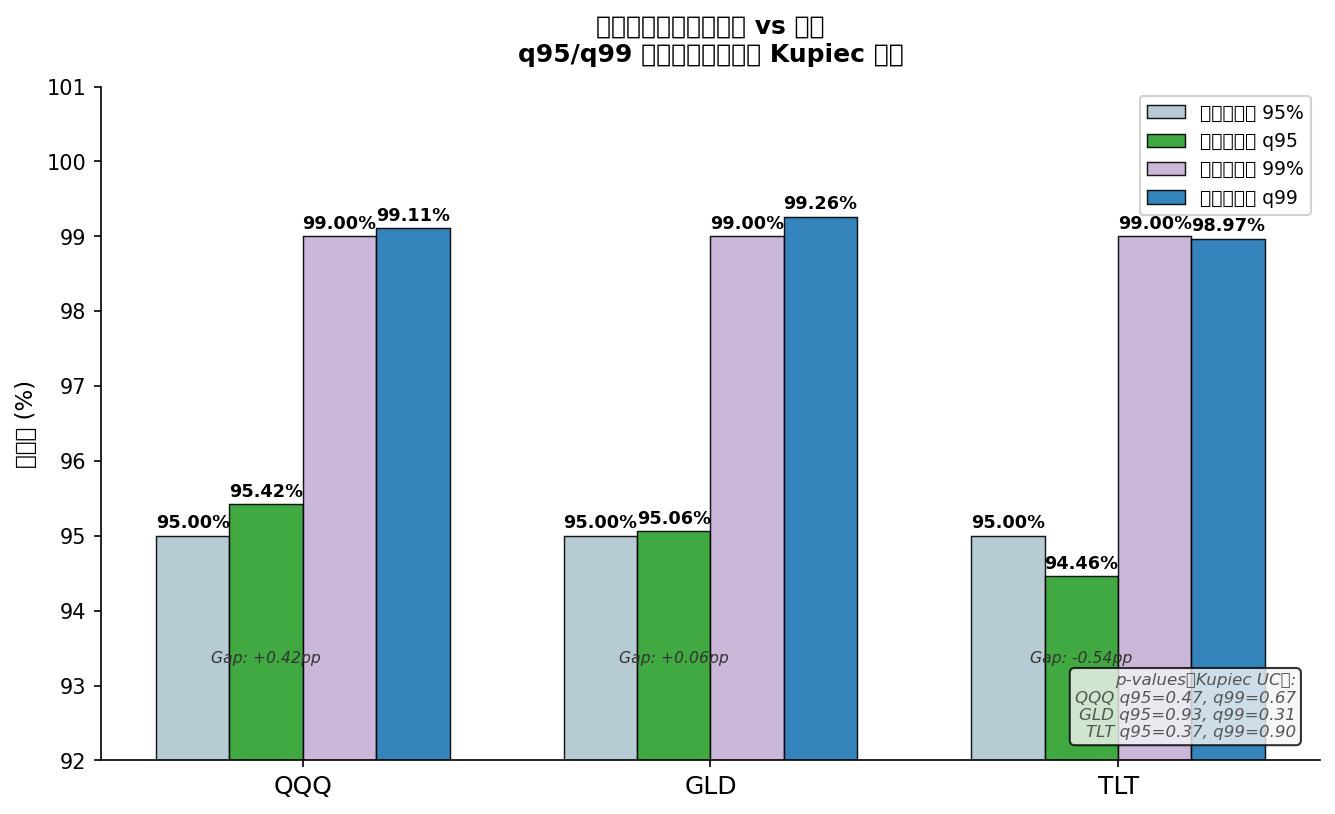
換一個問題:「我設定波動率最多到這個數字,實際上超過這個數字的機率有多高?」
這才是分位數法真正訓練的問題。
結果如下:
| 資產 | 95% 上界偏差 | 99% 上界偏差 | 覆蓋率驗證 |
|---|---|---|---|
| QQQ | +0.42 百分點 | +0.11 百分點 | 通過 |
| GLD | +0.06 百分點 | +0.26 百分點 | 通過 |
| TLT | -0.54 百分點 | -0.03 百分點 | 通過 |
三個資產、兩個信心水準,六個格子全部通過覆蓋率統計驗證(Kupiec 檢定 p 值最低 0.31,最高 0.93)。偏差最大的是 TLT 的 95% 上界,只偏了 0.54 個百分點。
你設定 95% 的風險上界,實際上確實有 94.5% 到 95.4% 的天數落在這條線以下。你設定 99% 的上界,實際上確實有 98.9% 到 99.3% 的天數落在這條線以下。在五年、跨越多次市場動盪的驗證期裡,這個校準精度相當穩固。
這對投資人有什麼意義
兩種使用場景,需求完全不同。
需要「猜對波動率數字」的人 ,比如基金經理要計算明天的風險預算、量化策略要設定停損點位。這類需求叫點預測,要的是盡量準確的中間估計值。分位數法不適合這個場景,改用普通線性迴歸更好。
需要「設定最壞情境上限」的人 ,比如風控部門要計算每日最大可能損失、投資組合要設定緊急停損線。這類需求叫尾部校準,要的是信心水準夠高、實際超越的機率夠低。分位數法在這裡表現優異,跨科技股、黃金、長期公債三個性質迥異的市場,都能維持校準精度。
問題的定義比模型本身更重要
這組實驗最後的結論很明確:你先問的問題,決定了哪個工具有效。
在科技股、黃金、長期公債三個差異極大的資產上,同一套框架在同一段驗證期裡,同時完成了兩個不同的判決。
如果問的是「你能猜對波動率嗎」,答案是一致的否。
如果問的是「你能守住波動率的邊界嗎」,答案是一致的是。
拿它去做不擅長的事,當然輸。用在它擅長的地方,跨市場五年的數據支撐這個結論。
本文基於 VolPred 研究實驗(K1403)。資料來源:yfinance 調整後收盤價,QQQ / GLD / TLT,訓練期 2007-2021,樣本外驗證期 2021-01-04 至 2026-05-27,n=1,355 個交易日。使用的統計比較方法(兩模型比較顯著-嚴格統計 調整)與覆蓋率驗證(Kupiec 無條件覆蓋檢定)均為業界標準方法。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊