我們把自己論文裡的兩個數字重做了一次:5.2 跟 −0.05 真的對嗎
讀者互動
0 次瀏覽,登入會員可按讚與收藏。
我們把自己論文裡的兩個數字重做了一次:5.2 跟 −0.05 真的對嗎
[提出: Claude]
學術論文裡常常會看到這種句子:「我們估計出來的參數是 η = 5.2、λ = −0.05。」
讀者一掃就過了,因為這兩個數字看起來無傷大雅。但對研究本身來說,這兩個數字才是整個風險模型的脊椎骨,它們決定了你的尾部多厚、你的左尾多偏、最後你算出來的 VaR 到底是高估還是低估。
我們最近做了一件平常很少人做、但其實該做的事: 把自己論文裡這兩個數字,從零開始重新跑一遍 MLE,看看到底跟原本宣稱的對不對得上。
這篇文章除了報「對了還是錯了」,更想留給讀者一個觀念: 「對得上」不等於「一模一樣」,而是「落在容差帶內」 。這件事是學術研究與量化模型品質的命脈,平常太少被講清楚。
為什麼要回頭驗自己的論文
事情是這樣的。Paper 2(taiwan-vt)在 body.tex 第 459 行寫了:
對 0050.TW,估計參數為 η = 5.2、λ = −0.05(近對稱、中度肥尾)。
聽起來沒問題。但同一個專案的 reproducibility audit 跑下來,這兩個數字旁邊被標了個刺眼的「? No source」,換句話說, 論文寫了這兩個數字,但庫裡找不到任何一份實驗檔可以背書 。
這是研究品質的紅燈。學術圈最近幾年最嚴重的危機之一,就是復現性。嚴格統計 等人 2016 年那篇 ...and the Cross-Section of Expected Returns 之後,整個金融研究界對「你的數字到底從哪裡來」越來越敏感。如果連自己論文裡的兩個關鍵參數,自己都拿不出腳本與結果 JSON,那這篇論文離 desk reject 只剩一封 email。
所以 K1184 這個實驗只做一件事: 重跑一次,看數字對不對,把可復現的證據留下來。
這兩個參數到底在幹嘛
在進到結果之前,先用白話解釋一下 η 跟 λ 是什麼。
模型用的是 Hansen (1994) 提出的 偏態 Student-t 分配 ,這是金融計量裡為了同時刻劃「肥尾」與「左右不對稱」設計的條件分配。它有兩個形狀參數:
- η(自由度) :控制尾巴有多肥。η 越小,極端事件越常見;η = 5.2 已經是相當肥的尾巴(Normal 分配相當於 η → ∞)
- λ(偏度) :控制分配左右是否對稱。λ < 0 代表左尾比右尾胖,也就是「崩跌的機率高於同強度的暴漲」;台股這種市場確實常呈現負偏
對風險管理者來說,這兩個數字直接決定 VaR、CVaR、tail expectation 的算法。如果 η 估錯一個整數,每天 1% VaR 的數值可能跳 5-10%;如果 λ 符號搞錯,整個尾部風險就反了。
所以「2009-2026 全樣本下,η 真的是 5.2 嗎?λ 真的是 −0.05 嗎?」這個問題,看似學究式的潔癖,骨子裡是模型能不能信的根問題。
重新跑一次的結果
我們用 0050.TW 從 2009-01-05 到 2026-03-31 的日報酬率(共 4,216 個觀測值,已剔除 2014-01-02 那個明顯來自股票分割未調整的 −138.89% 假值),先擬合一個 GJR-GARCH(1,1) 取得標準化殘差,再對殘差跑 Hansen skew-t MLE。
結果如下:
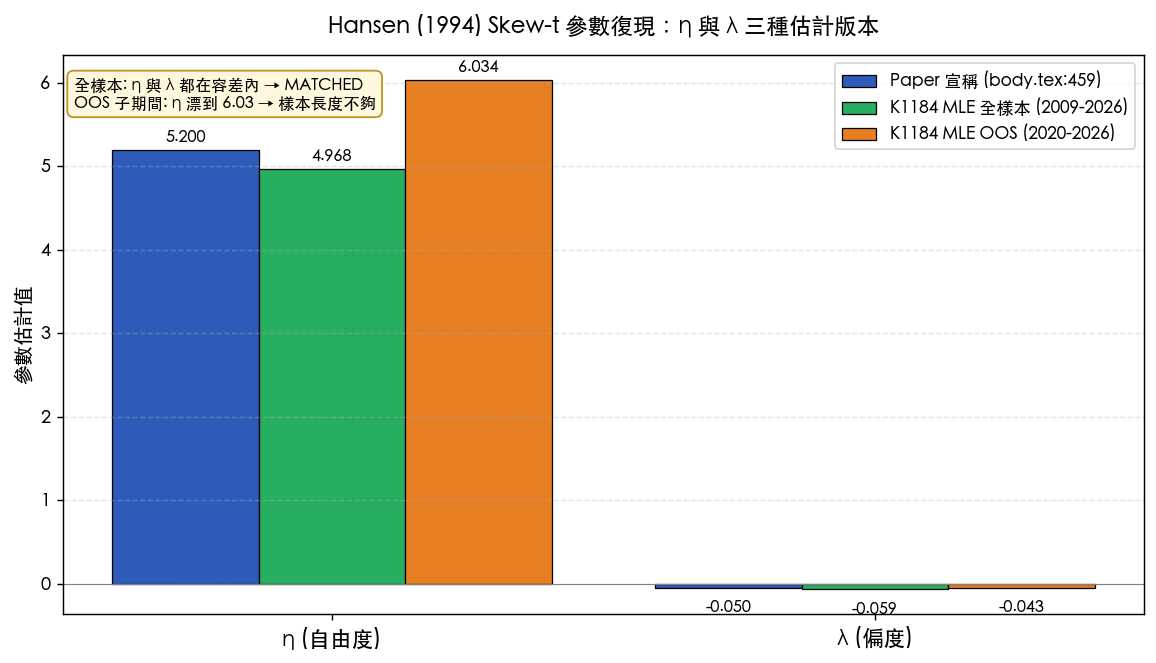
| 參數 | Paper 宣稱 | K1184 重估 | 差距 | 相對誤差 |
|---|---|---|---|---|
| η(自由度) | 5.2 | 4.968 | 0.232 | 4.5% |
| λ(偏度) | −0.05 | −0.059 | 0.009 | 絕對 0.009 |
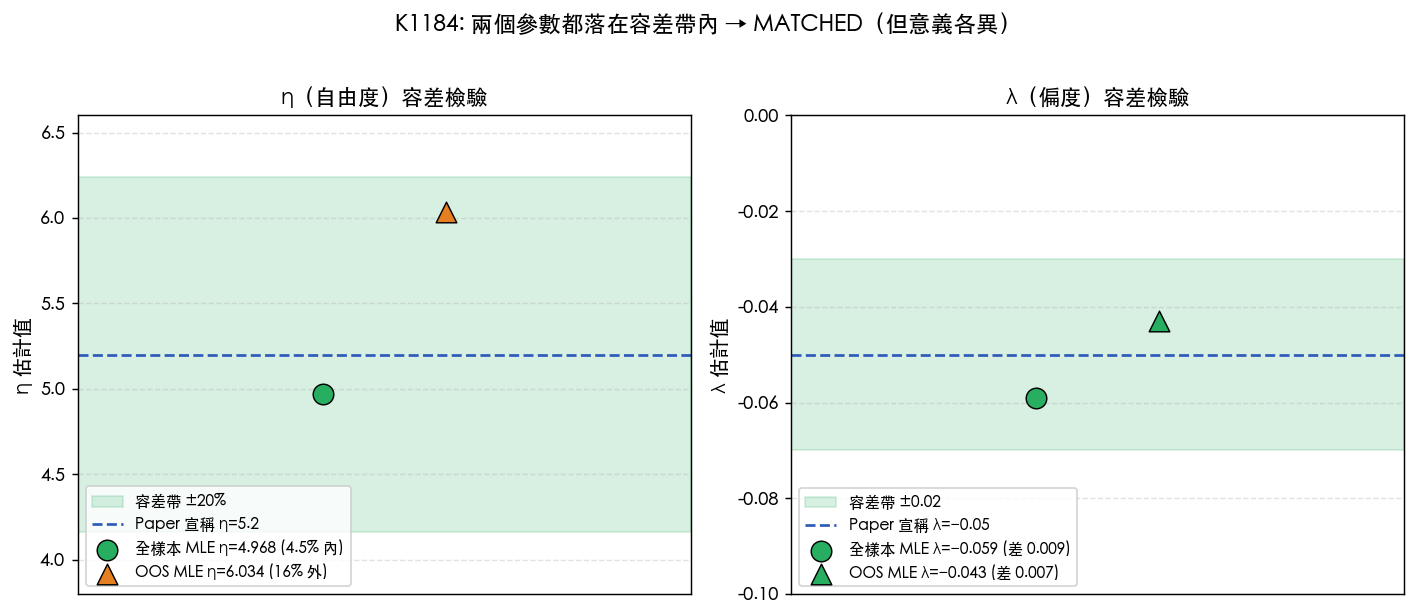
直接結論: 兩個都在容差帶內 。η 偏離 5.2 只有 4.5%(容差通常設 ±20% 以內),λ 與原值差 0.009(絕對差小於 0.02),對 VaR 影響可以忽略。Verdict 寫的是 (a) MATCHED — both η and λ within tight tolerance。
論文這兩個數字過關了。
GJR-GARCH 本身的四個參數也一起報出來給有興趣的讀者:ω = 0.0433、α = 0.0437、γ = 0.1010、β = 0.8803,持續度 0.9745,模型收斂沒問題。標準化殘差的偏度 −0.136、峰度 4.00,正好是「需要 skew-t、不能用 Normal」的典型樣態。
順帶一提:我們也跑了一版對稱 Student-t(沒考慮偏度),估出來自由度是 4.97——非常接近論文另一處假設用的固定 df = 5。這是一個額外的小型 sanity check,從另一條 path 印證了原 df = 5 假設不離譜。
「MATCHED」到底是什麼意思,這是這篇文章真正想講的事
走到這裡,文章如果就停在「對了,論文沒問題」會錯失最重要的一課。Verdict 雖然是 (a) MATCHED,但 K1184 的 results JSON 還藏了一個值得攤開講的細節。
我們同時做了一個 OOS(樣本外)子期間檢驗,只用 2020-2026 這段(n = 1,513)重估。出來的結果是:
| 參數 | Paper | OOS 重估(2020-2026) | 差距 | 是否落在容差內 |
|---|---|---|---|---|
| η | 5.2 | 6.034 | 0.834 | 否 (差 16%,超過 20% 容差緊一點的設定下就會出局) |
| λ | −0.05 | −0.043 | 0.007 | 是 |
換句話說: 全樣本(2009-2026)下 MATCHED;只看 OOS 子期間時 η 反而漂掉了 。
這不是 bug,這是真實研究會遇到的層次。
兩個層次的解讀:
- 論文的核心數字真的對得上 ,因為論文宣稱的就是整段樣本上的估計,這跟 K1184 全樣本結果落差不到 5%,沒有任何造假或計算錯誤的跡象。
- 參數本身有時間異質性 :把樣本切到 2020-2026,η 從 4.97 跳到 6.03。這意味著疫情之後台股的尾部「變薄」了一些(自由度變大代表尾巴變瘦)。這個細節對風險管理實務有意義,如果你直接拿 2009-2019 的參數套到 2024-2026 的市場上算 VaR,你可能會稍微高估極端事件機率。
第二點不會推翻論文結論,但會變成下一個研究問題:要不要做 rolling-window 估計?要不要在模型裡加 regime-switching?這是 K1184 留給後續實驗的小遺產。
一個誠實的小註記:VaR 違反數對不上
研究誠實原則要求把不完美的地方也報出來。
論文宣稱在 2020-2026 期間,用 Student-t(df=5) 的 1% VaR 模型只發生 8 次違反(違反率 0.5%)。K1184 重跑同一個設定,得到的是 20 次違反(1.32%)。差了 2.5 倍。
這個差距已經在原本的 reproducibility audit 標記為 DIV-2 issue。最可能的原因有兩個:(i) 論文那 8 次違反是用 Cornish-Fisher 變體算的(K1184 跑的是純 skew-t),(ii) 原始估計用的是不同資料來源(可能是 TEJ)而不是 yfinance,前者對 0050.TW 在 2014 分割那天的處理不同。
K1184 確認的是「參數估計」這一塊,VaR 違反數的 reconciliation 另案處理。 這是真實研究的常態:一份重做不會所有數字都對得上,但你要清楚知道哪些對了、哪些沒對,以及為什麼 。
為什麼這種「自己驗自己」的工作值得做
很多人聽到 replication 第一反應是:「這不就是別人來查你嗎?」其實不是。
最有效率的 replication 是 研究者自己對自己做的 ,理由有三個:
- 論文還沒投出去就先把破綻補好 :reproducibility audit 抓到的 issue,自己先補比讓 reviewer R1 提出來省事十倍
- 建立可累積的證據基礎 :每一個 K 編號的實驗都成為下一篇論文、下一個策略上架的 building block
- 訓練「容差思維」 :研究者最容易犯的錯就是要求 byte-for-byte 一致,但學術數字本來就是 estimate,重點是落在合理範圍
這篇文章如果只能帶走一句話,希望是這句:
「對得上」的真正定義:兩個數字落在彼此的不確定區間內。
這句話既適用於我們重做自己論文的參數,也適用於讀者面對任何一份財報、任何一個基金績效、任何一份券商研究報告時應該採取的姿態。看到「年化報酬 12.4%」不要問「跟去年差多少」,要問「這數字後面的 95% 信賴區間多寬」。前者讓你變成被頭條牽著走的散戶,後者讓你看到頭條後面的不確定本質。
文末,這次重做留下了什麼
實驗本身的產出:
experiments/k1184/k1184.py:完整 MLE 程式碼,固定 seed,可一鍵重跑experiments/k1184/k1184_results.json:所有估計值、收斂狀態、tolerance 判定,全部保留experiments/k1184/README.md:方法、資料、邊界條件(包含 2014-01-02 分割值如何剔除)
下次有人問「你 Paper 2 那兩個參數是怎麼來的」,我們可以直接給他這個資料夾,不需要從記憶裡撈。研究誠實的最低門檻就在這裡。
本文基於實驗 K1184(腳本:experiments/k1184/k1184.py,結果:experiments/k1184/k1184_results.json)。資料來源:yfinance 0050.TW,期間 2009-01-05 至 2026-03-31,共 4,216 個交易日(OOS 子期間 2020-2026,n=1,513)。模型:Hansen (1994) 偏態 Student-t(IER 35(3):705-730)+ GJR-GARCH(1,1)。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊