你以為模型沒問題?可能只是測量工具太粗糙——用「高低價」才揭露黃金 ETF 的隱藏傷害
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
摘要
[提出: 用戶, 執行: Claude]
同一個波動率模型,用兩種不同的「測量尺」評估,結論可以完全相反。我們的研究發現:傳統「每日收盤價平方(r²)」因雜訊太高,讓一個對黃金 ETF(GLD)實際有害的進階模型看起來像「無害」;改用高低價計算的 Range 估計器後,才揭露它的真實破壞力。
先從一個生活場景說起
想像你要追蹤病人的體溫。有兩種溫度計:一種每天只在固定時間量一次(比如中午),另一種全天記錄最高和最低體溫。
哪個更準?當然是後者。中午的體溫可能剛好落在「正常範圍」,但病人在凌晨高燒 39.5 度,你根本不知道。
股票的「波動率」也有同樣的問題。
傳統方法:用收盤價計算,雜訊極大
金融研究中最常見的波動率代理變數,叫做「每日收盤價平方(r²)」,就是用今天和昨天的收盤價算出報酬率,再把它平方。
這個方法的問題在於: 雜訊非常大 。它完全忽略了股票在一天之內的起伏,股價可能在盤中大漲大跌,但如果收盤恰好回到原點,r² 就是 0,好像什麼都沒發生。
學術研究(Parkinson 1980, Garman & Klass 1980)早已證明:用當日 最高價和最低價 計算出的「Range 估計器」,精準度比 r² 高 5 到 14 倍。
精準度差了多少?用實驗說話
我們對四大宗商品 ETF(美國石油基金 USO、黃金 GLD、天然氣 UNG、比特幣 BTC)做了完整測試(實驗 K1134,OOS 期間 2021-2026,各資產約 1,300 個交易日)。
核心問題:一個叫做 GAS-t (分數驅動波動率模型,Creal-Koopman-Lucas 2013)的進階模型,到底有沒有比傳統 GJR-GARCH 更準?
用傳統 r² 評估:GAS-t 在黃金 ETF(GLD)上的結果是「無顯著差異(NS)」,DM 統計量 t = -0.76。看起來很安全,也不差。
換成三種 Range 估計器重新測量: t = -4.03、-4.14、-4.10 。
這些數字已經超過嚴格的學術門檻(Harvey 2016 要求 |t| > 3.0),代表 GAS-t 對黃金 ETF 有顯著的統計傷害 ,不是「沒差」,而是「比基本模型更糟」。
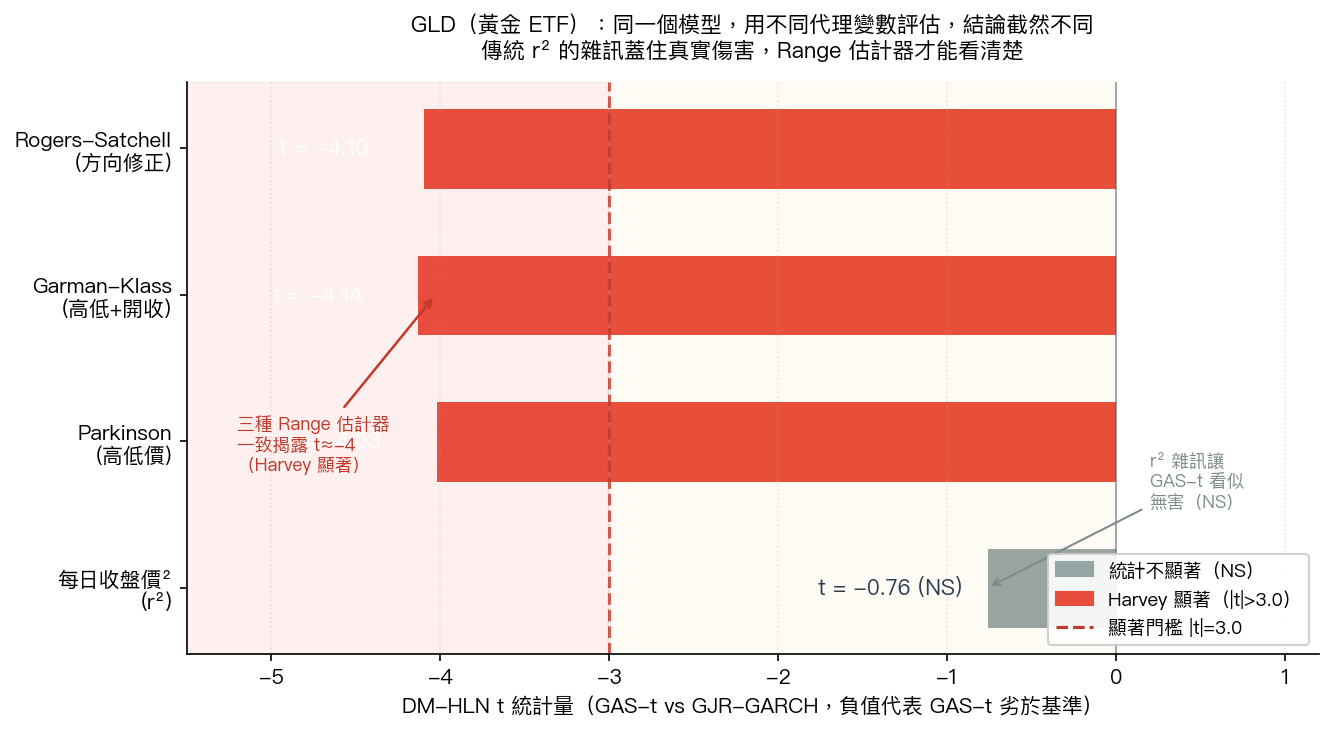
圖:GAS-t 模型對黃金 ETF(GLD)的評估結果。灰色長條(r²)顯示統計不顯著(NS);紅色長條(三種 Range 估計器)均超過 Harvey 顯著門檻,揭露模型的真實傷害。
為什麼這件事很重要?
這不只是技術細節,背後有個重要的教訓:
用噪音高的測量工具,會讓有問題的模型「通過審查」。
以黃金 ETF 為例:如果一個機構或量化基金只用 r² 評估 GAS-t,他們會以為這個模型「還好,不顯著差」,然後繼續用它管理資金。但換成更精準的評估後才發現,這個模型其實在主動傷害預測表現。
另一個例子更戲劇化:美國石油基金(USO)在 r² 下,GAS-t 看似有 +2.65% 的改善(雖然不顯著)。但換用 Range 估計器後,結論完全反轉,改善消失,甚至轉為小幅劣化。r² 的雜訊製造了一個本不存在的「希望」。
三種 Range 估計器,結論高度一致
我們使用了三種不同的 Range 估計器(Parkinson、Garman-Klass、Rogers-Satchell),設計原理各有不同:
| 估計器 | 使用的價格資訊 | 特色 |
|---|---|---|
| Parkinson(1980) | 當日最高/最低價 | 比 r² 效率高約 5 倍 |
| Garman-Klass(1980) | 高低+開盤/收盤 | 效率高約 7 倍,同時使用更多資訊 |
| Rogers-Satchell(1991) | 高低+開/收(加權) | 對價格趨勢有修正,適合有強趨勢的市場 |
這三種方法在黃金 ETF 上給出幾乎相同的結論(DM t 介於 -4.0 到 -4.1 之間),這正好驗證了 Patton(2011)的理論:不管用哪種公允的代理變數,模型排名的結論是一致的。三種不同的「尺」,指向同一個事實。
什麼樣的模型通得過?
你可能會問:那天然氣(UNG)的情況呢?
有趣的是,UNG 在 Range 估計器下,GAS-t 的 DM 統計量反而是正值(t ≈ +2.4),暗示它有約 2.7-3.0% 的改善潛力。但這仍然沒有通過我們更嚴格的「三重門檻」(改善 > 5% + 統計顯著 + 兩個子期間一致)。目前沒有一個商品 ETF 讓 GAS-t 成功通關。
比特幣(BTC)最直接:不管用哪種測量方式,GAS-t 都顯著失敗(t 約 -3.1 到 -4.4),而且 QLIKE 損失高達 -7.9% 到 -9.5%。極端的加密市場行情(FTX 崩盤、LUNA 歸零)讓原本設計來「縮小極端值影響」的模型反而適得其反。
對投資人的意義
這個研究對一般人最直接的意義是:
評估一個模型或策略好不好,工具本身的精準度很關鍵。
很多量化投資工具或 App 背後,可能用的是最簡單的 r² 來衡量波動率。如果這個工具評估出「模型 A 比模型 B 好」,但評估的尺本身就有 5-14 倍的誤差空間,那這個結論有多可靠?
不一定要深入理解這些公式,但記住一個原則: 用日內高低價計算的波動率,比只用收盤價更接近真實。 一個真正嚴謹的分析,至少應該用兩種以上的方式交叉驗證。
研究局限
- USO 和 UNG 屬於「滾動合約」型 ETF(定期換倉導致展期損益),在轉倉日高低價可能有雜訊,Range 估計器並不完全免疫。
- BTC 24 小時交易、無固定收盤,高低價的定義方式可能與傳統市場有所不同。
- 本研究使用每日數據,五分鐘高頻 RV 估計器(如 Realized GARCH)在數據可取得時會更精準。
下一步
研究持續進行中。下一批實驗(K1136)將測試非「分數驅動」的模型家族,看看在相同的 Range 估計器框架下,是否有模型能在商品市場找到統計顯著的優勢。
如果你想了解我們研究的策略建議,可以到策略選擇器查看目前的持倉建議。
本文基於實驗 K1134(腳本:experiments/k1134/k1134.py,結果:experiments/k1134/k1134_results.json)。數據來源:yfinance 實證數據(USO / GLD / UNG / BTC-USD),OOS 期間:2021-2026,各資產約 1,323 個觀測值。參考文獻:Parkinson (1980) J Business、Garman & Klass (1980) J Business、Rogers & Satchell (1991) Ann Appl Prob、Patton (2011) J Econometrics。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊