少做一點假設,反而更接近真實風險
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
很多風險模型都有同一個毛病:先假設市場大致長什麼樣,再去算你可能會賠多少。
問題是,市場最麻煩的時候,往往就是它最不像教科書假設的時候。
這次測試想回答的問題很直接。如果我們少做一點「市場平常應該長怎樣」的假設,只根據最近一段時間市場自己留下來的波動痕跡來估計風險,結果會不會更可靠?
答案是: 會,而且差距不小。
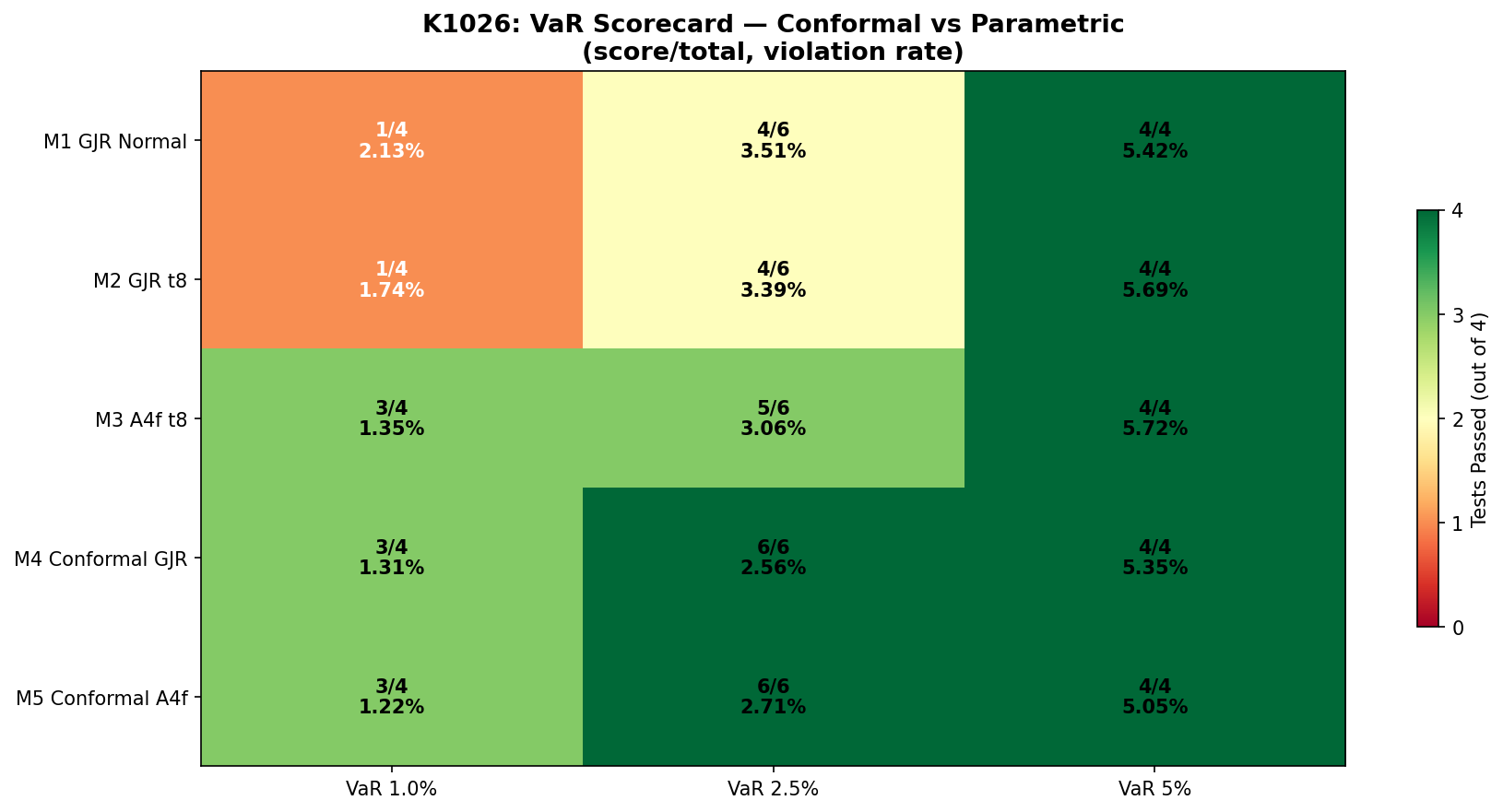
先說結果
這次比較了 5 種風險估計方式,測試標的是 SPY,樣本外期間從 2013 年一路拉到 2026 年。
如果只看整體檢查通過率:
- 傳統常態假設: 58%
- 傳統厚尾分配假設: 58%
- 加入外部風險因子的厚尾版本: 83%
- 不預設固定形狀、直接用近一年市場痕跡調整的兩個版本: 92%
最有代表性的 2.5% 風險門檻上,後兩者是 6/6 全通過 。前面幾個方法則比較常出現同一個問題:它以為自己抓到了極端下跌的邊界,實際上還是抓得不夠準。
它到底少假設了什麼?
一般做法會先選一個分配形狀。最常見的是常態,進階一點會改成厚尾版本。這些方法的共同點是:你先決定世界應該長什麼樣,再讓資料去配合它。
這次表現最好的做法,反過來處理。它先看最近一段時間市場真正留下了多大的意外波動,再直接用這些歷史痕跡去決定今天的風險邊界。
翻成白話就是:
不先猜尾巴應該多厚,而是直接問市場最近自己長出了多厚的尾巴。
為什麼會比較準?
因為市場在平靜時期和恐慌時期,尾端風險長得根本不像同一種東西。
如果你把形狀先寫死,市場一變臉,模型通常就會慢半拍。這也是為什麼傳統方法在高 VIX 環境下,實際出錯率常常明顯比低 VIX 環境高很多。
這次結果裡,少假設固定形狀的做法把這種落差縮小了。
- 傳統常態版本,高波動和低波動環境的出錯率差距超過 5 個百分點
- 表現最好的版本,差距縮到大約 2.6 到 2.9 個百分點
這代表它不是完美,但至少比較能跟上市場狀態真的在變。
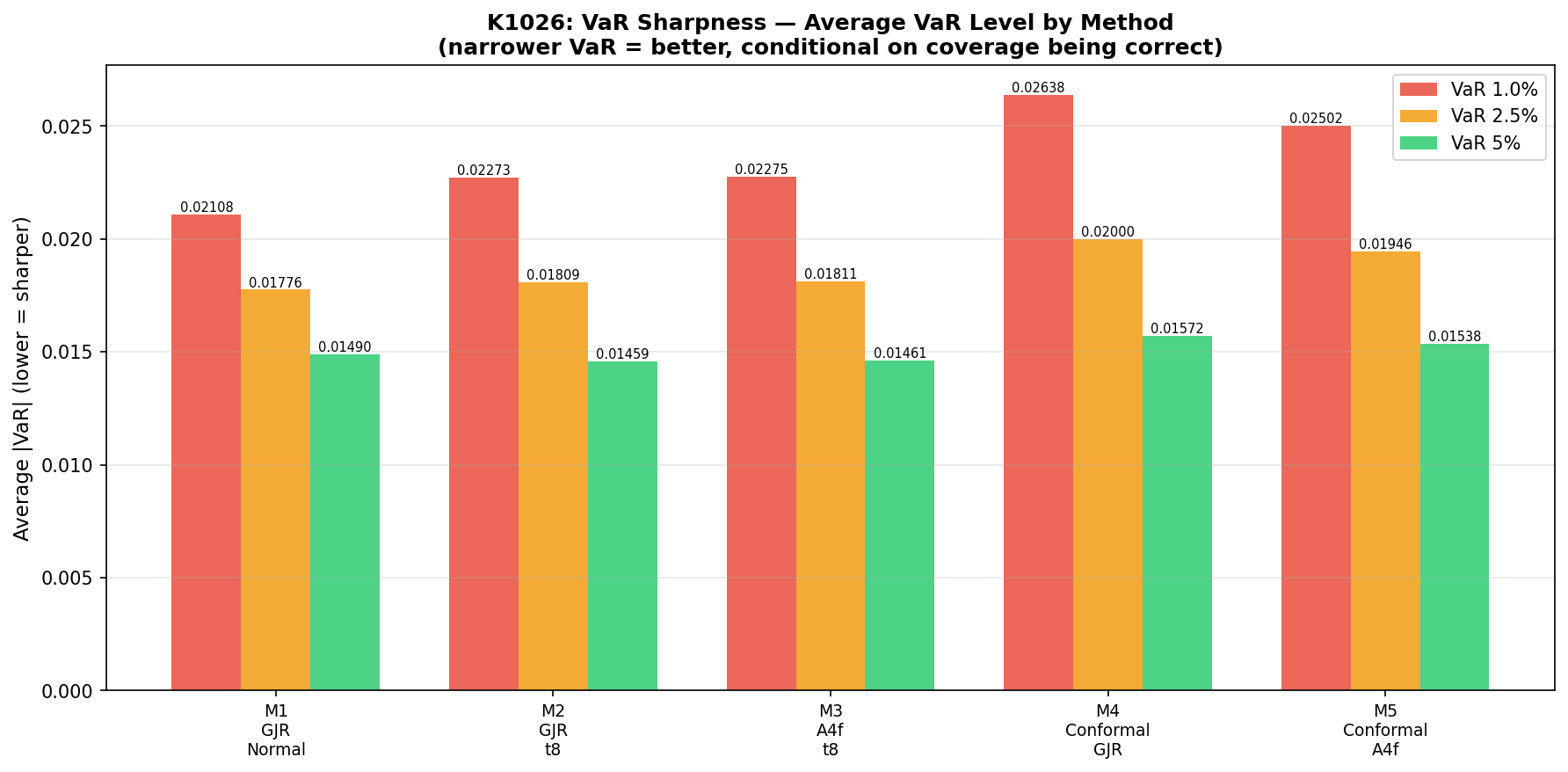
代價也很明顯:它會讓你看起來比較危險
這件事不能只講優點。
表現最好的兩個方法,雖然命中得比較準,但算出來的風險邊界也更寬。以 2.5% 風險門檻來看,新的做法大約比傳統方法寬 7% 到 10% 。
意思是什麼?
意思是如果你真的照它來做風控,你會更常得到一個比較難看的答案:今天最好保守一點。
這也是它比較誠實的地方。不是因為世界變安全了,就把數字壓小;而是因為它承認,最近市場留下來的痕跡本來就比較醜。
對一般投資人有什麼用?
最實用的提醒不是叫你自己去建模,而是提醒你不要太相信那些看起來很精準、其實靠很多固定假設撐起來的風險數字。
如果一個工具總是告訴你「最大可能損失差不多就這樣」,你該問的是:
- 它是不是假設市場一直長得差不多?
- 它有沒有隨著最近一年的市場變化調整?
- 它給的安全感,是因為真的比較穩,還是因為它把尾巴想得太薄?
風險管理真正難的地方,不是把數字算得漂亮,而是承認有時候比較醜的答案,反而比較接近現實。
一句話結論
這次測試的重點很簡單: 少做一點分配假設,會讓風險估計更接近真實;代價是你得接受,真實風險通常比傳統模型看起來更大。
資料來源
本文來自 VolPred 的一份風險模型測試,資料來源為 yfinance,標的為 SPY;評估期間自 2013-01-02 起至 2026-04-09,共 3,287 至 3,337 個交易日,依方法不同略有差異。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊