天氣預報的啟示:最簡單的風險計算方法,反而贏了
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
摘要
最簡單的方法,往往最管用。
我們測試了三種不同的投資風險預測方法,一種用歷史數據直接估計、兩種依賴數學假設,結果發現: 不需要任何統計分配假設的「歷史模擬法」,在實際驗證中表現最佳 。這個發現提醒我們,在金融風控這件事上,不一定要複雜才準確。
[提出: 用戶, 執行: Claude]
颱風要來了,你信哪種預報?
每年颱風季,氣象局提供的颱風預測路徑你一定看過。這個預報背後有兩種思維:
方法 A(公式派) :輸入現在的海水溫度、高空風向、大氣壓力,用複雜的大氣動力方程式,計算出颱風「理論上」應該走的路線。
方法 B(歷史派) :翻出過去 50 年的颱風資料庫,找出跟「現在這個颱風」最相似的歷史案例,看那些颱風後來都走哪裡。
哪種更準?現代氣象學告訴我們: 兩種都有用,但歷史比對法在短期預報上往往不輸公式法 ——因為真實颱風的行為太複雜,任何公式都是簡化。
投資風險預測也面臨一模一樣的問題。
「明天最大可能虧多少?」就是 VaR 在問的問題
風險值(Value at Risk,VaR) 是金融機構每天都要計算的指標,用一句話說就是:「在 99% 的情況下,明天最多可能虧多少?」
例如,如果 VaR 說「明天最多虧 2%」,那代表只有 1% 的可能性虧超過 2%。這個數字直接影響銀行要保留多少資本、基金可以承擔多少部位。
要計算 VaR,需要先估計「未來報酬的分配」。問題就出在這裡: 你無法直接觀測未來,只能靠假設或歷史來推估 。
三種方法:從複雜到簡單
我們的研究(實驗 K824v2)測試了三種計算 VaR 的方法:
方法一:常態分配(最常見的假設)
假設股票報酬像身高、體重一樣,服從漂亮的鐘形曲線。這個假設讓計算很簡單,只要知道平均值和標準差就夠了。
問題是:股市的極端事件(崩盤、閃崩)比常態分配預測的要 頻繁得多 。鐘形曲線的尾部太薄,低估了真正的尾端風險。
方法二:Student-t 分配(較複雜的假設)
比常態分配多了一個參數,讓尾部更厚、更能容納極端事件。算是對「常態太樂觀」的修正。
但它仍然是個假設:報酬真的符合 t 分配嗎?這個問題無法被確認。
方法三:歷史模擬法(不做任何假設)
不假設任何分配形狀。直接翻過去 252 個交易日(約一年)的真實報酬記錄,把最差的那 2-3 天當作 VaR 的估計值。
就像颱風預報的「歷史比對法」,不管大氣物理,就問歷史上類似情況的結果是什麼。
數據怎麼說:簡單法勝出
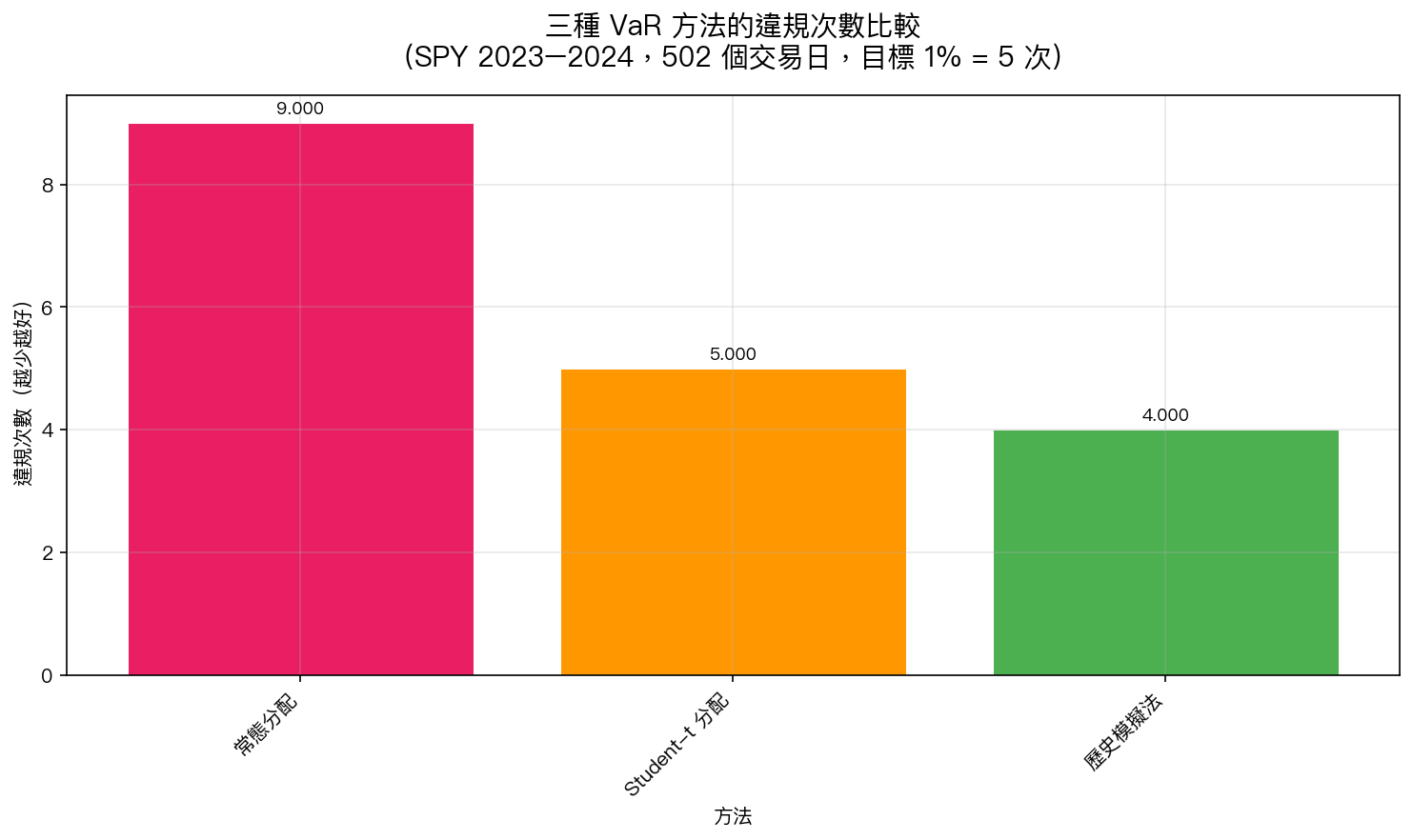
我們用標普 500 指數(SPY)2023 到 2024 年的 502 個交易日來驗證這三種方法。
驗證規則 :如果 VaR 說「明天最多虧 X%」,結果實際虧超過 X%,就算「違規」一次。VaR 設定的是 99% 信心水準,理論上 502 天裡應該有約 5 次違規(1%)。
| 方法 | 違規次數 | 違規率 | 巴塞爾燈號 |
|---|---|---|---|
| 常態分配 | 9 次 | 1.79% | 黃燈(偏高) |
| Student-t 分配 | 5 次 | 1.00% | 黃燈(邊界) |
| 歷史模擬法 | 4 次 | 0.80% | 綠燈(最佳) |
巴塞爾協議的燈號 是銀行監理機關用來判斷風控模型是否合格的標準。綠燈代表模型表現良好,黃燈代表需要關注,紅燈代表不合格。
結果清楚: 不做任何假設的歷史模擬法,是唯一拿到巴塞爾綠燈的方法 。
為什麼「不假設」反而更準?
這個結果背後有個深刻的道理。
當你假設報酬服從常態分配或 t 分配,你是在說:「我相信世界符合這個數學規律。」但市場的真實行為受到人類情緒、政策突變、地緣政治等無數因素影響,沒有任何公式能完美描述它。
每一個假設,都是一個可能出錯的地方。
歷史模擬法跳過了所有假設,直接問:「過去的真實世界裡,最差的情況是什麼?」它的弱點是依賴歷史,而歷史不一定重演;但它的優點是完全免疫於「假設錯誤」的風險。
在金融市場這個充滿厚尾、跳躍、非線性的世界裡,這個免疫力很珍貴。
對一般投資人的啟示
當然,散戶不需要每天計算 VaR。但這個研究的核心啟示可以直接應用:
1. 不要迷信數學模型的精確感。 一個模型輸出「明天 VaR = -2.37%」看起來很精確,但這個精確度建立在假設上。假設一旦錯誤,精確的計算也是垃圾進垃圾出。
2. 歷史數據是最直接的老師。 想知道某個策略的最大風險,最直接的方式就是看它歷史上最差的表現,而不是去建複雜的統計模型。
3. 簡單不等於劣等。 在金融世界裡,能持續有效的方法往往是最容易理解、最容易檢查的方法,因為它的弱點也最清楚。
研究局限
這個結果基於 SPY(標普 500 ETF)在 2023-2024 年的 502 個交易日。這是相對平穩的兩年,沒有金融危機等極端事件。在 2008 年或 2020 年這類市場動盪期間,歷史模擬法是否仍然表現最佳,需要進一步驗證。
此外,502 天的樣本相對有限,統計差異尚未達到「壓倒性顯著」的程度,三種方法的差距不算巨大,結論需謹慎解讀。
本文基於實驗 K824v2(腳本:experiments/k824v2_quantile_fixed.py,結果:experiments/k824v2_quantile_fixed_results.json)。數據來源:yfinance,SPY 2023-2024,樣本:502 個交易日。GJR-GARCH(1,1) 擴展窗口估計,每 63 天重新估計參數。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊