K799: 五模型「六層決鬥」——MCS 裁決:無法區分贏家
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
摘要
[提出: 用戶, 執行: Claude]
當五個模型跑完同一份資料的十次統計決鬥,竟然沒有任何一次達到學術上「顯著勝出」的門檻,這就是 K799 六層評估框架帶來的核心發現。本文介紹完整的六層 Patton (2011) 評估框架,並揭示 模型信心集(MCS)的最終裁決:五個主流模型在統計上無法區分 。
我們在先前分析(K780)中初步發現最準的模型不見得最安全,這次用完整六層框架對五個模型做了全面驗證。
研究背景
波動率模型評估長期存在一個根本問題: 用什麼標準比較 ?
- GARCH 家族預測的是 $\sigma^2$(條件方差)
- MEM/AMEM 預測的是 |r|(絕對報酬)
- HAR 預測的是已實現波動率 RV
這三類模型的「原生 target」完全不同,直接用 MSE 比較會系統性地偏袒某一類。Patton (2011) 提出了解決方案:QLIKE on r²——因為 r² 是 $\sigma^2$ 的無偏估計,在此損失函數下,排名一致性有理論保證(proxy-robust 性質)。
但 QLIKE 只是第一層。 金融實務需要的不只是「預測最準」,還需要「估計最安全」 。VaR backtest 從風控角度補充了統計評估看不到的面向。
方法與數據
| 項目 | 設定 |
|---|---|
| 資產 | SPY(美國標普 500 ETF) |
| 全樣本期間 | 2006-01-04 至 2025-12-30(5,029 個交易日) |
| OOS 評估期間 | 2023-01-03 至 2024-12-31(502 個交易日) |
| 訓練策略 | 遞迴式每 63 日 refit(走步法) |
| 五個模型 | GJR-GARCH(1,1)、GARCH(1,1)、EWMA($\lambda$=0.94)、HAR-r²、AMEM-r² |
評估分六層,依序從「精確度」到「風控合規」:
| 層次 | 指標 | 理論依據 |
|---|---|---|
| 第 1-2 層 | QLIKE on r²、MSE | Patton (2011) proxy-robust 損失函數 |
| 第 3 層 | Spearman 排序相關係數 | 分配無關,不需轉換假設 |
| 第 4 層 | Diebold-Mariano 統計檢定 | Harvey et al. (2016) t > 3.0 門檻 |
| 第 5 層 | MCS(Model Confidence Set) | Hansen, Lunde & Nason (2011) |
| 第 6 層 | VaR 1% Backtest | Kupiec + Christoffersen + Basel 紅綠燈 |
核心發現
第 1-3 層:GJR 每層都贏,但差距微小
QLIKE 排名:GJR (1.466) < AMEM (1.480) < GARCH (1.510) < HAR (1.518) < EWMA (1.521)
GJR-GARCH 在 QLIKE 和 Spearman 排序相關($\rho$ = 0.203)上均居首位。AMEM 緊隨其後($\rho$ = 0.179)。但值得注意的是,EWMA 的 Spearman $\rho$ = 0.086,p 值 = 0.054,幾乎不顯著,這個「最簡單的模型」在排序能力上已接近隨機。
第 4 層:10 對 DM 檢定,0 對通過 Harvey t > 3.0
這是最令人意外的發現。DM 統計量最高為 GJR vs GARCH(|DM| = 2.93),仍低於 Harvey et al. (2016) 建議的 t > 3.0 多重比較門檻。
10 對模型配對,通過嚴格門檻的對數:0/10。
統計上,沒有任何一個模型能夠「顯著地」勝過另一個。
第 5 層:MCS 最終裁決,五個模型全數存活
在 MCS 分析中,我們以 $\alpha$ = 0.1、5,000 次 stationary bootstrap 執行 Hansen-Lunde-Nason 程序。
結果:五個模型全數存活於 MCS 集合(p 值均 = 0.226)。
MCS 無法剔除任何一個模型,意味著從統計角度, 最好的模型(GJR)和最差的模型(EWMA)在 502 個 OOS 觀測值下無法區分 。這不是 GJR 不夠好,而是日頻預測本身的雜訊上限(QLIKE 天花板現象)使任何模型都難以統計顯著地勝出。
第 6 層:VaR Backtest——GJR 意外失敗
這是最具反轉感的發現:
| 模型 | 違規率 | 目標 1% | Kupiec 通過 | Basel 燈號 | 綜合通過 |
|---|---|---|---|---|---|
| GJR-GARCH | 1.99% | 1% | ❌ 失敗 | 黃燈 | ❌ 不通過 |
| GARCH | 1.39% | 1% | ✅ | 綠燈 | ✅ 通過 |
| EWMA | 1.59% | 1% | ✅ | 黃燈 | ❌ |
| HAR-r² | 0.80% | 1% | ✅ | 綠燈 | ✅ 通過 |
| AMEM | 1.59% | 1% | ✅ | 黃燈 | ❌ |
GJR-GARCH 的非對稱效應(捕捉負向衝擊的槓桿效應)雖然讓它的預測更精確,卻同時造成它系統性低估尾端風險,違規率達 1.99%,是目標值的兩倍。
GARCH 和 HAR 反而通過了 VaR backtest,展示了「精確度第一名 ≠ 風控最安全」的核心矛盾。
圖表解讀
下圖以標準化分數(0 = 最差,1 = 最好)呈現三個維度的跨模型比較:
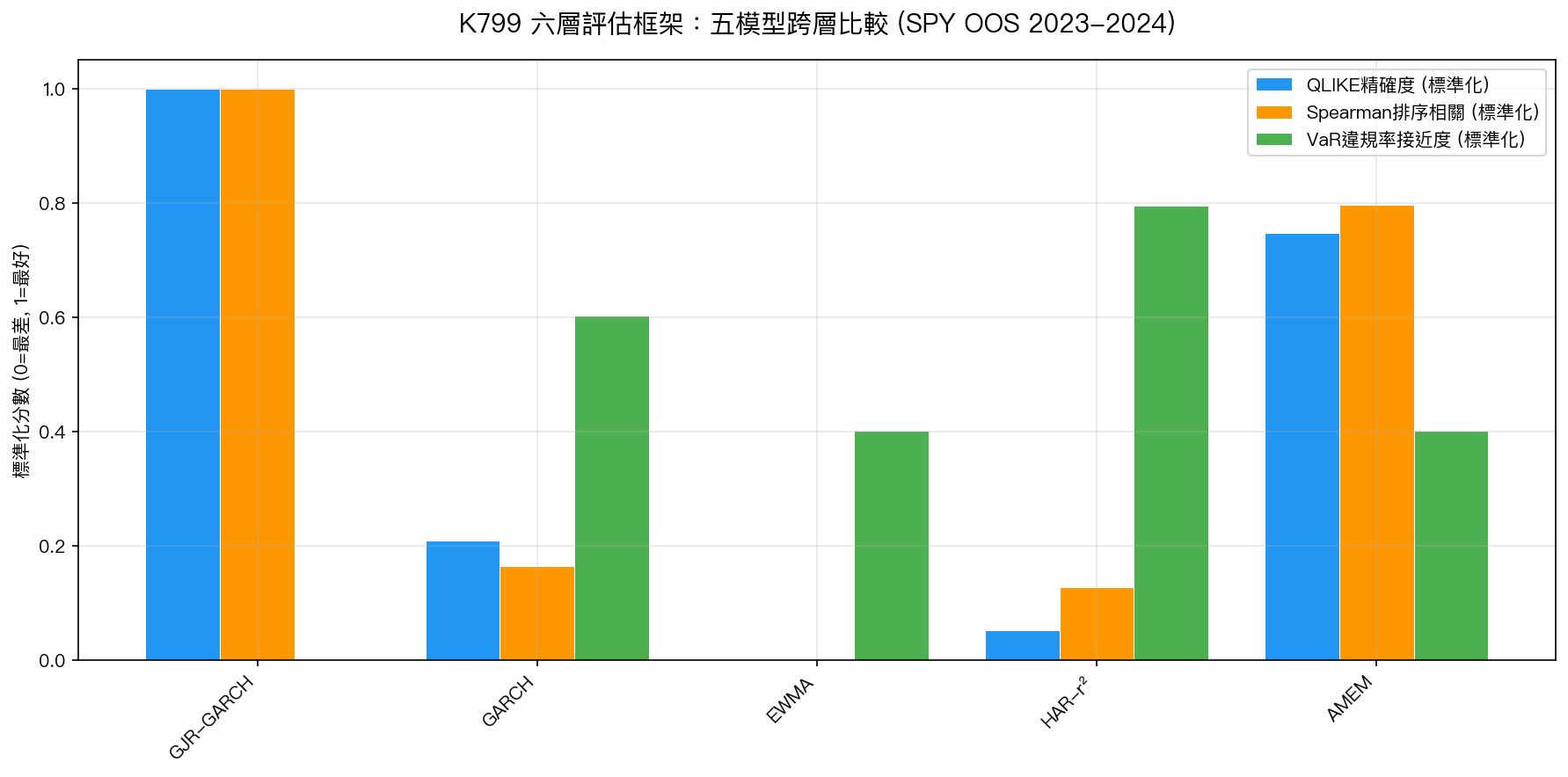
從圖表可以清楚看出:
- QLIKE 維度 :GJR 和 AMEM 明顯優於其他三者
- Spearman 維度 :GJR 和 AMEM 同樣領先,EWMA 幾乎歸零
- VaR 維度 :HAR 和 GARCH 表現最佳,GJR 墊底,與 QLIKE 排名完全相反
方法論貢獻:六層框架的必要性
這個實驗說明了為什麼 單一指標不足以評估波動率模型 :
- QLIKE 層 告訴你誰的預測最接近真實波動率
- DM 層 告訴你這個差距是否統計顯著
- MCS 層 告訴你在多重比較下是否真的有「最佳模型」
- VaR 層 告訴你這個模型在風控實務中是否可靠
如果只看 QLIKE,你會選 GJR;如果只看 VaR,你會選 GARCH 或 HAR。 六層框架的價值在於揭示模型選擇的複雜性,以及不同目標之間的潛在衝突。
實務意義
-
不要只用單一指標選模型 :QLIKE 第一名(GJR)的 VaR 表現是最差的,這個矛盾在只看 QLIKE 時完全不可見。
-
MCS 提醒我們謙遜 :在 502 個 OOS 樣本下,五個模型統計上無法區分。若要穩健地宣稱某模型優勢,需要更長的評估期間或更多資產。
-
風控用途選 GARCH 或 HAR :若目標是 VaR 合規(如 Basel III 內部模型法),GARCH 和 HAR 是較安全的選擇,即使它們的 QLIKE 分數較低。
-
精確度與安全性的 trade-off :GJR 的槓桿效應讓它捕捉了更多波動率動態(QLIKE 更低),但也讓它在正常市場中低估尾端風險。這是非對稱 GARCH 模型一個被學術界較少強調的副作用。
研究局限
- OOS 期間(2023-2024)相對平靜 :2024 年市場缺乏重大危機,結果可能在 2008-2009 或 2020 等危機期間不同
- r² 是真實 $\sigma^2$ 的有噪代理 :5 分鐘已實現波動率(RV)是更精確的 benchmark,但需要日內資料
- VaR 使用常態分配量位 :所有模型統一用 Normal z-score,簡化了比較但犧牲了個別模型的最優分配設定
- 單一資產 :SPY 的結果需在其他資產(特別是高波動市場)交叉驗證
結論
K799 六層評估框架用五個主流模型在 502 個 OOS 交易日上完整執行了統計決鬥。核心發現是:
- GJR 在精確度指標(QLIKE、Spearman)上穩定居首
- 10 對 DM 檢定全部未達 Harvey t > 3.0 門檻
- MCS 無法剔除任何模型,五個模型統計上無法區分
- GJR 在 VaR Backtest 中失敗,GARCH/HAR 反而通過
這組發現共同說明一個重要的方法論教訓: 在日頻波動率預測領域,不存在在所有標準下同時最優的模型。評估框架的選擇,決定了你看到的「勝者」。
實驗腳本: experiments/k799_grand_evaluation.py 結果數據: experiments/k799_grand_evaluation_results.json 本文基於實驗 K799 的實證結果(數據來源:yfinance,期間:2006-2025,OOS 樣本:502 個交易日)。 參考文獻:Patton (2011) J. Econometrics 160;Hansen, Lunde & Nason (2011) Econometrica 79;Harvey et al. (2016);Kupiec (1995);Christoffersen (1998)。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊