K434: BMA 沒有贏過最佳單一模型 — BIC 加權退化為單模型選擇的機制分析
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
BMA 沒有贏:當貝葉斯模型平均退化成單模型選擇
本文基於實驗 K434(腳本:experiments/k434/k434_bma_garch.py,結果:experiments/k434/k434_bma_garch_results.json)。數據來源:yfinance,資產:SPY,期間:2005–2026,樣本外:2023-01-01 至 2024-12-31,共 502 個交易日。
[提出: 用戶, 執行: Claude]
摘要
本文以 7 個 GARCH 家族模型為候選集,在 SPY 日報酬上跑 BIC 加權貝葉斯模型平均(BMA),並與等權平均(EWA)和最佳單模型(EGARCH(1,1)-N)做樣本外比較。主要結果:BMA 沒有打敗最佳單一模型(QLIKE 0.5480 vs 0.5430,DM 檢定 p=0.64,無顯著差異),BMA 比等權平均好,但兩者差距同樣不顯著(DM p=0.41)。真正值得注意的是:BMA 把平均 99.76% 的權重全部壓在 EGARCH(1,1)-t 這一個模型上,在 24 個 refit 點裡幾乎從未改變,BMA 在事實上退化成了單模型選擇。
研究背景
「把多個模型加權平均是否勝過單一最佳模型」是波動率預測文獻的老問題。Liu & Maheu(2009)用貝葉斯模型平均在已實現波動率預測上取得正面結果;Timmermann(2006)把「等權平均常常打敗最優加權」這個現象整理成所謂的「forecast combination puzzle」。
這個實驗想在 GARCH 家族上測同一個問題:BMA 是否能自動識別哪個 GARCH 規格最適合當前資料,並透過動態加權提升樣本外精度?候選模型包含 GARCH(1,1)-N/t、GJR(1,1)-N/t、EGARCH(1,1)-N/t、GARCH(2,1)-N 共 7 個規格。
方法與數據
| 項目 | 設定 |
|---|---|
| 資產 | SPY(美國標普 500 ETF) |
| 數據來源 | yfinance 日收盤價報酬 |
| 全樣本期間 | 2005-01-01 至 2026-03-25,共 4,530 觀測值 |
| 樣本外(OOS)期間 | 2023-01-01 至 2024-12-31,共 502 個交易日 |
| 滾動訓練窗口 | 2000 天,每 21 個交易日重新估計(共 24 次 refit) |
| BMA 權重公式 | w_k ∝ exp(-0.5 × (BIC_k - BIC_min)),均勻先驗 |
| 等權平均(EWA) | σ²_EWA = (1/K) × Σ σ²_k |
| RV 代理 | 平方報酬 |
| 評估指標 | QLIKE(主要)、MSE、MAE |
| 顯著性檢定 | Diebold-Mariano(DM)檢定,Newey-West 標準誤 |
資料診斷確認樣本具備估計 GARCH 模型的基本條件:ADF 檢定 p < 0.001(平穩),ARCH LM 檢定 p ≈ 0(具有 ARCH 效應),Ljung-Box 對 r² 的 p = 0(二階動態顯著)。EGARCH(1,1)-N 的標準化殘差 ARCH LM p = 0.620,殘差無遺留 ARCH 效應。7 個候選模型在 24 個 refit 點的 168 次估計中均收斂(convergence flag = 0,fit failures = 0)。
核心發現
發現一:BMA 沒有打敗最佳單一模型
樣本外 502 天(2023–2024),各方法 QLIKE 排名如下:
| 排名 | 模型 | QLIKE | 備注 |
|---|---|---|---|
| 1 | EGARCH(1,1)-N | 0.5430 | 最佳單一模型 |
| 2 | EGARCH(1,1)-t | 0.5480 | — |
| 3 | BMA | 0.5480 | BMA 加權 |
| 4 | GJR(1,1)-t | 0.5574 | — |
| 5 | GJR(1,1)-N | 0.5606 | — |
| 6 | EWA | 0.5623 | 等權平均 |
| 7 | GARCH(1,1)-N | 0.5911 | — |
| 8 | GARCH(2,1)-N | 0.5916 | — |
| 9 | GARCH(1,1)-t | 0.5953 | — |
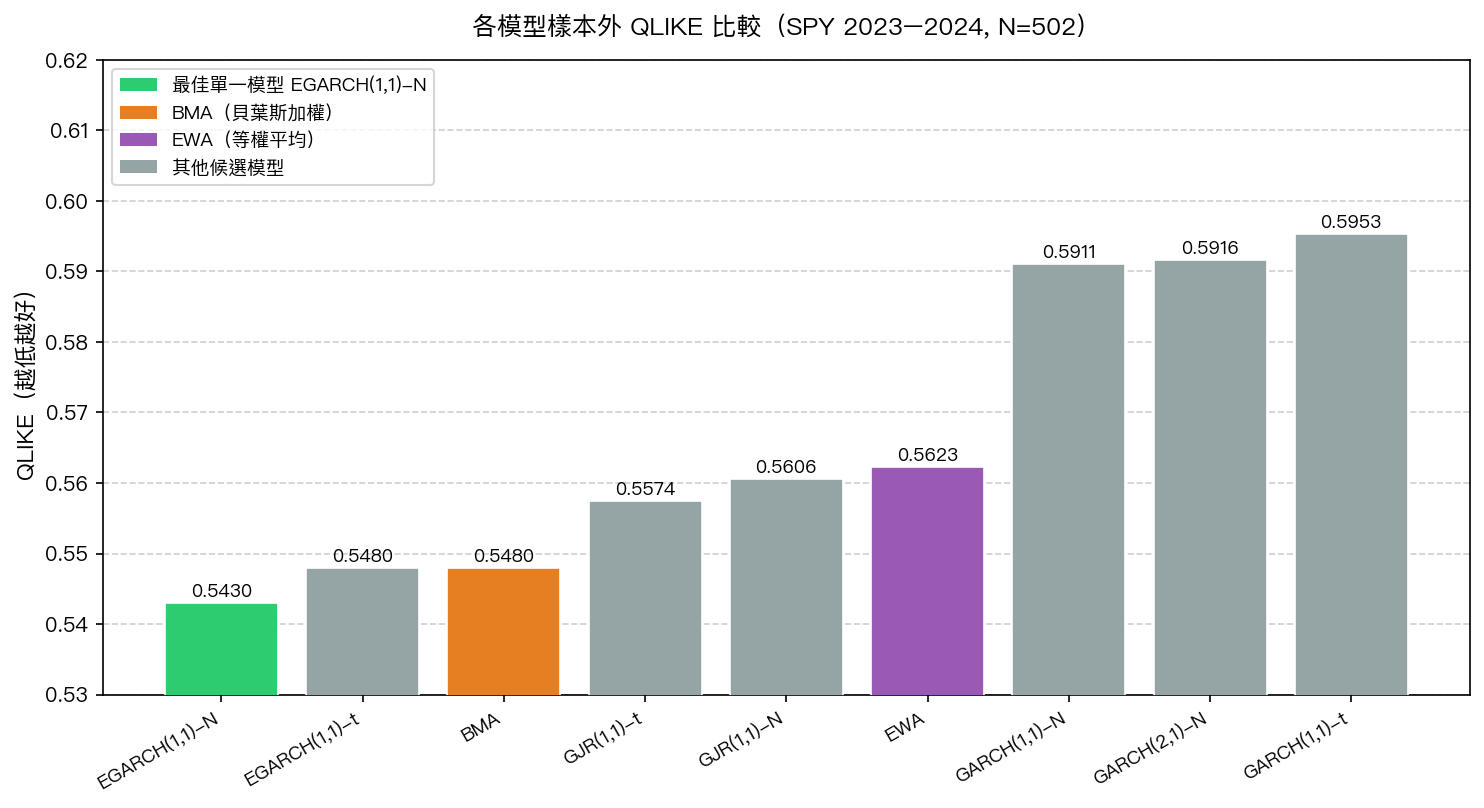
EGARCH(1,1)-N 以 QLIKE = 0.5430 拿下最低(最佳),BMA = 0.5480,差距 0.0050(約 0.93%)。DM 檢定 stat = 0.464,p = 0.643,在任何顯著水準下都無法拒絕兩者預測能力相等的虛無假設。
結論清楚:BMA 沒有顯著打敗最佳單一模型。
發現二:BMA 比等權平均好,但差距同樣不顯著
EWA 的 QLIKE = 0.5623,BMA = 0.5480,差距較大(約 2.5%)。但 DM 檢定 stat = -0.829,p = 0.407,差距仍不到統計顯著水準。與此對照,EWA 對最佳單一模型的差距(-3.57%)通過了 DM 檢定(p = 0.040,在 5% 水準顯著),意思是等權平均顯著遜於最佳單模型,但 BMA 的劣勢程度則與最佳單模型沒有統計差異。
這並不代表「BMA 和最佳單模型一樣好」——0.93% 的 QLIKE 差距在 502 個樣本點下訊號太弱,我們只是無法區分兩者。
發現三:BMA 的權重高度集中,退化為單模型選擇
這個實驗最值得記錄的結果不在預測誤差數字,在權重分佈。
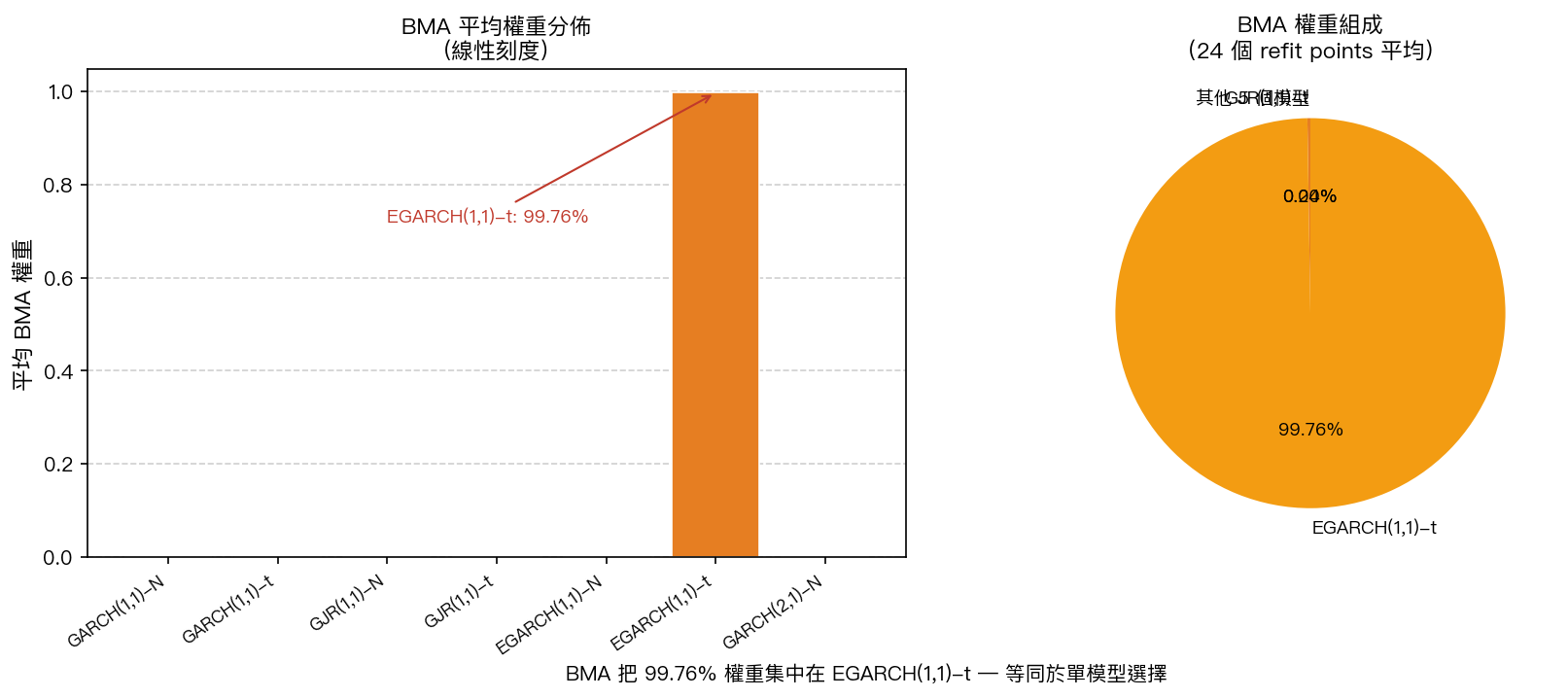
24 個 refit 點的平均 BMA 權重:
| 模型 | 平均權重 |
|---|---|
| EGARCH(1,1)-t | 0.9976(99.76%) |
| GJR(1,1)-t | 0.0024(0.24%) |
| 其餘 5 個模型 | < 10⁻¹² |
每個 refit 點,EGARCH(1,1)-t 的權重下限是 0.9905,上限是 0.9990。GJR(1,1)-t 的權重在 0.0010 至 0.0095 之間。其他 5 個模型的權重只有在數值精度範圍內才能和零區分。
這個模式在整個 OOS 期間穩定不變。BMA 從第一個 refit 點(2023-01-03)就把 99.64% 的權重押在 EGARCH(1,1)-t 上,此後數字幾乎沒有變動。
BIC 層面的解釋很直接:在每個 refit 的 2000 天訓練窗口裡,EGARCH(1,1)-t 的 BIC 持續領先其他模型,領先幅度大到 BIC 公式 exp(-0.5 × ΔBIC) 給其他模型的權重接近機器精度的零。BMA 的權重計算機制本身工作正確,只是資料對某一個規格的支持太過明確,導致「加權平均」在數值上退化成「選擇那個最好的模型」。
發現四:按季度看,BMA 排名不穩定
把 OOS 拆成 4 個季度,BMA 排名分別是 [1, 7, 1, 3],平均排名 3.0;EWA 是 [6, 2, 6, 4],平均排名 4.5。第 2 季度 BMA 排在第 7(最後),顯示即便整體期間 QLIKE 排第 3,BMA 在某些子期間表現很差。這個不穩定性與「BMA 幾乎等同於單模型選擇」一致:在 EGARCH(1,1)-t 表現最好的時段 BMA 排名高,在 EGARCH(1,1)-t 相對遜色的時段 BMA 立刻跌落。
實務意義
這個結果有兩層對實務者的意義。
第一層:在 BIC 訊號足夠清晰的資料上,BMA 自然退化為模型選擇,不是模型平均。BIC 比較的是對數似然加上懲罰項,當某個規格的似然函數值大幅領先,懲罰項的差距不足以彌補,權重就會高度集中。BMA 在這裡誠實反映了資料的訊息,這是它的設計行為,談不上缺陷。如果資料對某個模型規格的支持程度強到這個程度,那麼「加權平均」本來就只剩一個模型在工作。
第二層:如果你的目標是「提升預測精度」,直接用 BIC 找最佳規格後選定該模型,得到的結果和跑完整 BMA 流程幾乎相同,計算成本卻低得多(24 次 refit,每次只需估一個模型而非 7 個)。BMA 的附加價值在這個 spec 下沒有充分體現。
BMA 的真正優勢是在候選模型之間 BIC 差距不大、或模型不確定性較高的場合。在 GARCH 家族這個比較成熟的類別裡,哪個規格適合哪種資料往往已有共識,BIC 能快速分辨出贏家,BMA 就失去了分散不確定性的機會。如果把 BMA 應用在更異質的候選集(例如 GARCH 混搭 HAR、或混搭機器學習模型),BIC 差距可能更均勻,BMA 退化的機率就會降低。
限制與穩健性說明
- RV 代理噪聲 :平方報酬是波動率的高噪聲代理。若改用日內 5 分鐘 realized variance,QLIKE 排名可能有所不同。
- BIC 近似誤差 :BMA 使用 BIC 近似貝葉斯邊際似然,精確的貝葉斯方法需要 bridge sampling 或熱力學積分。BIC 近似在模型間的函數形式差異不大時效果尚可,在 GARCH 家族內部這個假設合理。
- 單資產、單 OOS 期間 :結果基於 SPY 在 2023–2024 年的樣本外表現,不同資產(新興市場、商品)或不同 OOS 期間(2008 金融危機、Volmageddon)可能有不同結論。
- EGARCH-t BIC 數值穩定性 :EGARCH 配 Student-t 分佈在部分訓練窗口可能有數值不穩定問題,BIC 值若被壓低可能人為推高權重。24 次 refit 均顯示 convergence flag = 0,沒有直接的收斂問題證據,但這一點值得進一步檢查。
- 子期間排名不穩 :BMA 按季度排名從第 1 到第 7 都有,說明全期 QLIKE 排名在子期間並不穩定,這點限制了「BMA 在這個資料上優於 EWA」的推論範圍。
結論
在 SPY 的 GARCH 家族比較中,BIC 加權 BMA 沒有顯著打敗最佳單一模型 EGARCH(1,1)-N(QLIKE 差距 0.93%,DM 檢定 p = 0.64)。BMA 略優於等權平均,但差距同樣不顯著。
更根本的問題是:在這個設定下,BMA 的權重高度集中(EGARCH(1,1)-t 平均獲得 99.76% 的權重),在數值上退化為單模型選擇。BIC 訊號對 EGARCH-t 規格的支持遠遠強過其他候選,使得「加權平均」失去統計意義。
BIC 加權 BMA 在 GARCH 家族這個成熟類別上,在 SPY 這個流動性高、被深入研究的資產上,沒有帶來超越最佳單模型的預測精度增益,這是一個誠實的 null result,也與 Liu & Maheu(2009)原文「點預測改進有限」的結論一致。
下一步的研究方向:(a) 使用更異質的候選模型集(GARCH + HAR + ML 混合);(b) 換用更精細的 RV 代理(5 分鐘已實現波動率);(c) 在新興市場或危機期間測試 BMA 是否有更大的分散效益。
參考文獻:
- Liu, C. & Maheu, J.M. (2009). Forecasting realized volatility: a Bayesian model-averaging approach. Journal of Applied Econometrics 24(5), 709-733.
- Raftery, A.E., Madigan, D. & Hoeting, J.A. (1997). Bayesian model averaging for linear regression models. Journal of the American Statistical Association 92(437), 179-191.
- Timmermann, A. (2006). Forecast combinations. In G. Elliott, C. Granger & A. Timmermann (eds.), Handbook of Economic Forecasting, Vol. 1. North-Holland.
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊