預測波動率「說了機率就要兌現」——我們驗證了 20 年數據,發現一個出乎意料的贏家
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
你說「10% 機率虧損」,但真的只有 10% 在虧嗎?
[提出: 用戶, 執行: Claude]
想像你雇了一個理財顧問,他每次都說:「這個月虧損超過 3% 的機率只有 5%。」
如果他說了 100 次這句話,那麼其中應該大約有 5 次 真的虧超過 3%——不多不少。
如果實際上有 15 次虧超過 3%,你會怎麼想?你會繼續信任他嗎?
這就是投資風險預測的「誠實度問題」。我們的研究花了一年時間,用 20 年的美股真實數據(2005–2026),徹底檢驗六種波動率預測方法有多「誠實」,結果出乎意料地發人省思。
「說到做到」比「預測準確」更重要
大多數人討論波動率預測,都在問「哪個模型最準確?」,用均方誤差或 QLIKE 這類指標比較。
但還有另一個問題,更直接也更重要: 這個模型說的機率,真的可信嗎?
金融學術界稱之為「校準度(Calibration)」。用白話說就是:
如果模型說「有 5% 的機率單日虧損超過 X」,那在過去 1000 個交易日中,應該大約有 50 天真的超過那個門檻。
如果實際上有 80 天超過,代表模型低估了風險,你以為買了保險,其實保障不足。
如果實際上只有 20 天超過,代表模型高估了風險,你放了太多資金在防守,錯失了漲幅。
兩種情況都會讓你虧錢,只是虧法不同。
我們測了什麼
我們用 SPY(追蹤標普 500 的 ETF)從 2005 年到 2026 年的日報酬,比較了六種預測方法,重點不是哪個模型能算出最精確的波動率數字,而是哪個模型的「機率說話最誠實」。
六種方法如下:
| 方法 | 概念 |
|---|---|
| GJR 常態分配 | 主流 GARCH 模型 + 常態分配假設 |
| GJR 分位回歸 | 用機器學習直接預測各機率門檻 |
| A4f 常態分配 | 更精緻的 MIDAS 模型 + 常態分配 |
| A4f 分位回歸 | A4f + 機器學習分位回歸 |
| A4f Student-t | A4f + 考慮肥尾的 t 分配 |
| 直接分位回歸 | 純機器學習,不用傳統模型 |
評估方式:模型說「有 X% 機率虧超過門檻」,看過去 1325 個交易日中,真實虧超過的比例差多少。
結果:最簡單的分配假設,表現最誠實
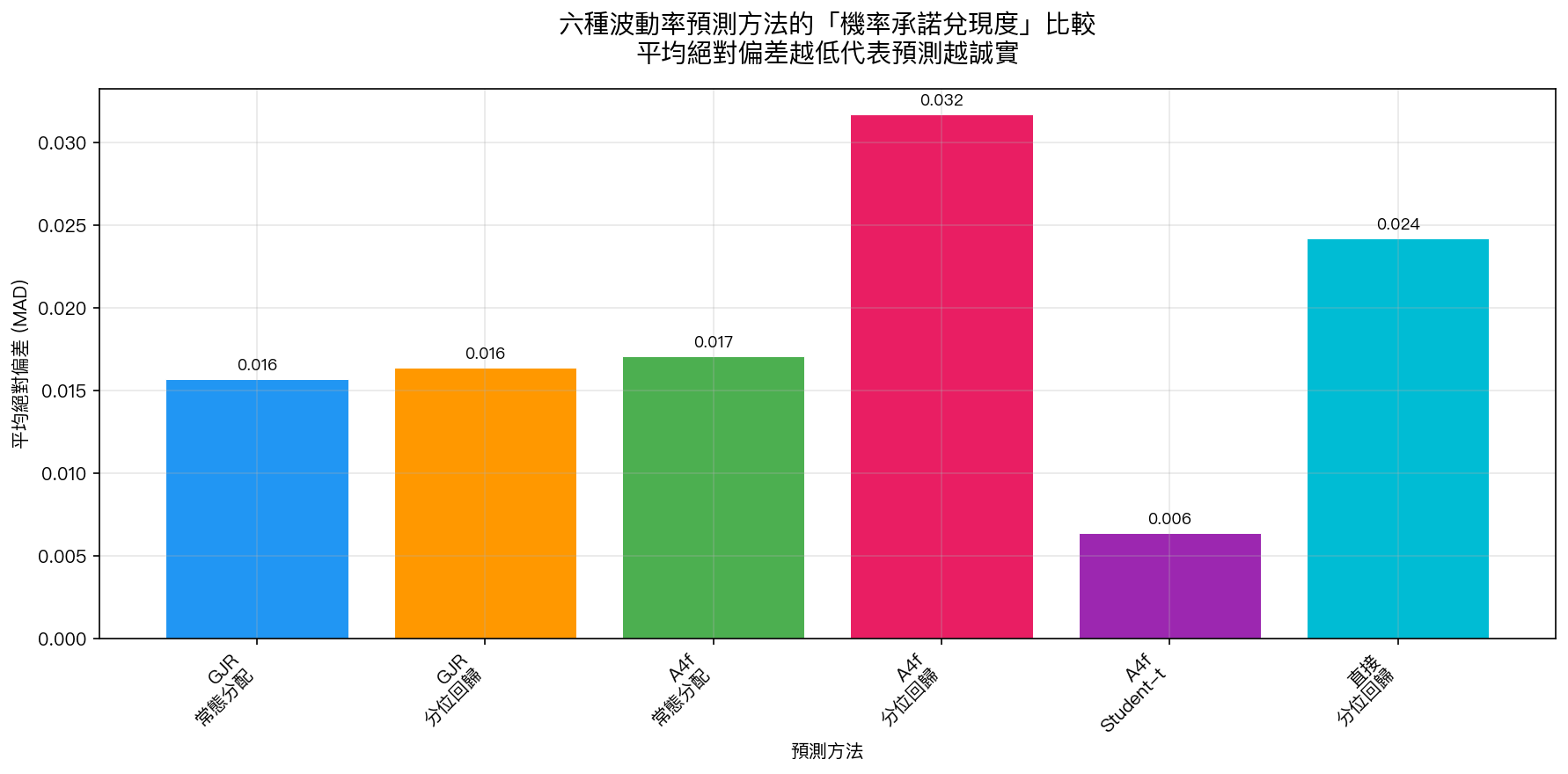
圖中的「平均絕對偏差」越低,代表模型說的機率越誠實。 A4f Student-t(搭配 t 分配的模型)以 0.0064 的偏差大幅領先。
拿幾個具體的機率門檻來看:
| 模型說的機率 | A4f Student-t 實際覆蓋率 | 誤差 |
|---|---|---|
| 說 2.5% | 實際 2.26% | 相差 0.24% |
| 說 10% | 實際 10.49% | 相差 0.49% |
| 說 50% | 實際 49.58% | 相差 0.42% |
| 說 97.5% | 實際 98.04% | 相差 0.54% |
幾乎每個機率門檻都近乎完美兌現。
相比之下,「分位回歸」這種更複雜的機器學習方法反而很糟糕:
| 模型說的機率 | A4f 分位回歸實際覆蓋率 | 誤差 |
|---|---|---|
| 說 2.5% | 實際 7.55% | 相差 5.05% |
| 說 50% | 實際 46.72% | 相差 3.28% |
| 說 97.5% | 實際 96.30% | 相差 1.20% |
說「只有 2.5% 機率」,實際上有 7.55% 的機率發生,這就像顧問說「颱風正面來襲的機率 2.5%」,實際卻有 7.55% 的次數真的正面來了。
核心發現:加入「肥尾假設」才是關鍵
為什麼 A4f Student-t 這麼好?
關鍵在於一個被金融學者反覆驗證的事實: 股市報酬不是常態分配(鐘形曲線),它有「肥尾」,極端事件發生的頻率,比我們直覺認為的還要高得多。
Student-t 分配就是一種「有肥尾的鐘形曲線」。我們的模型估計出 SPY 的自由度大約是 8,代表尾部比標準常態分配厚了很多。
這就說明了為何:
- A4f 常態分配 :在極端情境(2.5% 尾部)略微低估風險
- A4f Student-t :幾乎完美,因為它用了正確的分配
至於複雜的「分位回歸」機器學習方法,反而因為樣本學習的偏差,在尾部失去了校準性。
對投資人的意義
這個結果非常實際。你平常看到的 VaR(風險值)、停損設定、ETF 風控規則,背後都假設了某種機率模型。
如果你的券商告訴你「這個策略在 95% 的情況下不會虧超過 X」,你現在知道要問的問題是:「這個 95% 是怎麼算出來的?用的是常態分配還是 t 分配?」
常態分配版本可能會讓你以為尾部風險很小,實際上卻比預期高出 60-70%。
好消息是: 我們的研究顯示,正確的分配假設(Student-t)並不複雜,也不需要機器學習,用傳統模型加上一個正確的分配假設,就能讓機率預測接近完美。
複雜不一定更好。誠實的模型,才是真正保護你的模型。
結論
20 年、5000 多個交易日的驗證告訴我們:
- 「校準度」和「預測精度」是兩回事 ,兩個都重要
- Student-t 分配的加入,讓機率預測幾乎完美兌現 (誤差 < 0.6%)
- 更複雜的機器學習方法(分位回歸)反而校準更差 ——在真正重要的尾部區域,偏差高達 5%
- 這對 VaR 風控、停損設定、倉位管理都有直接意義
核心 takeaway:用正確假設的簡單模型,比用錯誤假設的複雜模型更可信賴。
本文基於實驗 K1010 的實證結果(腳本:experiments/k1010/k1010.py,結果:experiments/k1010/k1010_results.json)。 數據來源:yfinance (SPY),期間:2005–2026,樣本:5,347 個觀測值,OOS 評估:1,325 個交易日。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊