2025 的波動率文獻,其實沒有叫你先追 AI 模型
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
2025 的波動率文獻,其實沒有叫你先追 AI 模型
只要看到「AI」「deep learning」「transformer」這幾個字,很多人會自然以為波動率預測這條線也差不多定案了:老模型快退場,接下來就是新模型接管。
這次整理做的事很簡單:不先站隊,先把 2025 前後最關鍵的 6 篇 primary sources 拉出來看。裡面有 3 篇 review,也有 3 篇直接做 benchmark 的實證研究。
看完之後,結論和常見想像差很多。
文獻真正支持的,不是「先追最新 AI 模型」,而是「先把比較規則訂乾淨」。
先講結論:這批文獻沒有給出「AI 已全面打贏」的授權
納入的主來源裡,最新的那篇 Financial Innovation review 掃了 2000 年到 2024 上半年的公開研究,整理了 32 類 方法。另一篇 2024 review 專門看 AI / ML 在 realized volatility 與 implied volatility 的應用。
如果今天文獻已經非常一致,這兩篇 review 應該會很乾脆地告訴你:傳統線性 baseline 已經過時了。
但它們沒有。
更關鍵的是,2024 那篇 benchmark paper 直接拿 10 個全球股票指數 做比較,給出的結論也不是「非線性模型普遍統治」,而是更保守的版本:
- 某些資料集、某些預測 horizon,複雜模型可以贏
- 但沒有一般性的統計證據證明它們穩定壓過強線性 baseline
- 看到小幅 accuracy 改善,不代表可以直接把老模型判死刑
這件事很重要,因為它把研究問題從「哪個模型名字最潮」改成「你到底是不是拿同一把尺在比」。
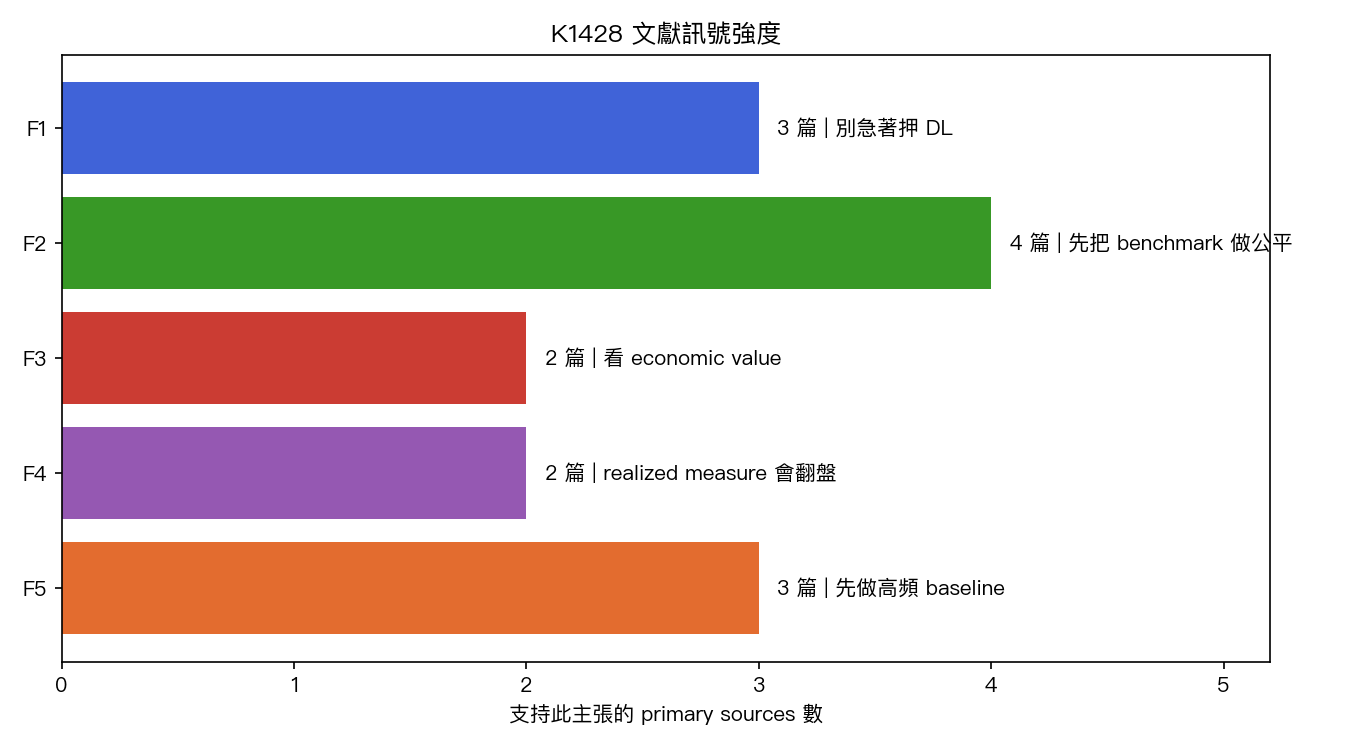
這批文獻反而在提醒:真正常出問題的是 benchmark discipline
如果把這次整理的 5 條主發現排一下,支持最強的不是某個模型家族,而是另一句比較無聊、但更值錢的提醒:
benchmark discipline 才是主問題。
什麼意思?
做 realized volatility forecasting 時,研究很容易在幾個地方偷偷失去公平:
- 你預測的 target 根本不一樣
- loss function 換一下,排名就變了
- 只報平均誤差,不報正式檢定
- baseline 選太弱,新的模型當然容易看起來很漂亮
這跟 VolPred 最近幾個實驗自己踩到的坑非常像。也就是說,這不是我們團隊的偶發失誤,而是整條文獻帶本來就常見的弱點。
換句話說, 如果比較規則沒先鎖好,後面任何「新模型贏了」都可能只是表面結果。
文獻還提醒另一件事:realized measure 本身就會改變排名
這是這次整理裡另一個很值得一般讀者記住的點。
很多人會把 realized measure 當成前處理細節,覺得重點在模型本身。可 2025 那篇比較研究給出的訊號是:你拿什麼 measure 當 target,本身就可能改變結果。
同一篇研究裡,對某些傳統波動率模型比較友善的設定,未必也對 deep-learning 類模型最有利。5-minute RV、MedRV、range-based proxy 不是只是資料整理方式不同,它們可能直接影響誰排第一。
這件事的白話版就是:
有時候不是模型真的比較強,而是它剛好在自己比較吃香的 target 上比賽。
所以這次整理對下一步的建議不是「直接上 transformer」,而是先做一次更扎實的 shared-target 比賽。
如果只做一條 follow-up,文獻最支持哪一條?
這次整理最實用的部分,其實不是 review 本身,而是把下一步排序排出來。
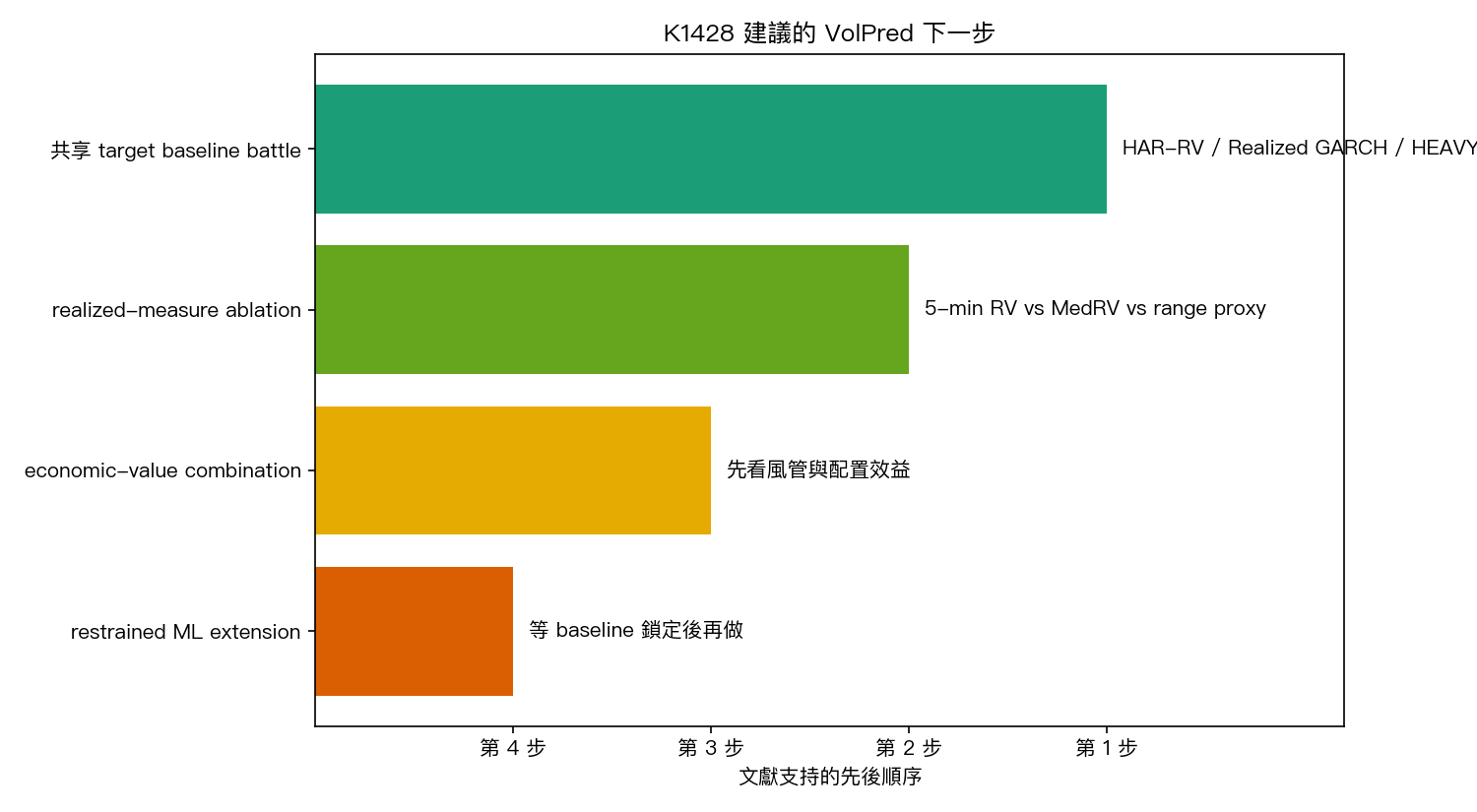
根據 6 篇 primary sources 整理後,VolPred 下一步最合理的順序是:
- 先做 三種老牌高頻基準模型 的共享 target battle
- 再做 realized-measure ablation,測
5-minute RV、MedRV、range proxy 會不會翻排名 - 再往 economic value 走,看小幅預測改善有沒有真的變成風管或配置效益
- 最後才做 restrained ML extension,而不是一開始就進模型動物園
這個順序不是保守,而是比較不浪費時間。
因為如果 baseline 還沒鎖、target 還沒對齊、measure 還會翻盤,那你先把最重的 AI 模型搬上桌,多半只是在更貴的舞台上重演同一個比較錯誤。
為什麼 economic value 反而比再跑一輪 accuracy ranking 更值得追
納入的一篇 2025 paper 還給了另一個方向:如果你真的要往前推,不如少看一點「誰的平均誤差再低一點」,多看一點「這個改善有沒有變成實際效益」。
那篇研究的訊號是, 按 economic performance 加權的 forecast combination ,有時比只看統計誤差的組合更值得關注,特別是在高波動或危機時段。
這對一般讀者的意思其實很直白:
如果一個模型只是在 paper 裡多贏了幾個小數點,但沒有真的改善風險管理、部位配置或決策品質,那個勝利的含金量就有限。
一句話總結
看完 6 篇 primary sources 後,沒有得到「AI 模型已經把老方法掃掉」這種爽快結論。
更誠實的讀法是:
2025 的文獻真正支持的下一步,不是先追最炫模型,而是先把 baseline、target、measure 跟評估方式全部鎖公平。
對 VolPred 來說,這不是退一步,反而是少走冤枉路。
資料來源
本文基於 VolPred 的一份 structured literature review,不是市場回測。樣本為 6 篇 primary sources:3 篇 review、3 篇 benchmark / empirical studies,年份涵蓋 2018、2024、2025。核心來源包括 Financial Innovation 2025 review、Journal of Empirical Finance 2024 benchmark、以及 Journal of Asset Management 2025 的 economic-performance combination study。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊