同一個波動率模型,換個計算方式還能贏嗎?五個市場階段的穩定性測試
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
同一個波動率模型,換個計算方式還能贏嗎?五個市場階段的穩定性測試
學術研究中的波動率模型,常被質疑一件事:「這個模型是不是只在特定設定下才贏?稍微換個條件就垮了?」
這篇文章要說的,是我們對一個已有正面結論的模型(A4f)做的一次壓力測試。
背景:A4f 模型是什麼
A4f 是我們在進行中的論文研究中提出的波動率預測框架。核心想法很直接:預測明天股市的波動率時,把當前的市場恐慌程度(用 VIX² 代表)乘進模型,作為時變的「背景波動水位」。
先前的研究已經驗證:A4f 比標準的基準波動率模型更準,差距顯著。用兩模型比較的統計檢定(DM 檢定)來看,t 值達 4.48,大幅超過學術界的顯著門檻(|t| > 3.0)。
這個結果是在「收盤到隔天收盤」的日報酬設定下得到的。
新問題:改用「開盤到收盤」的報酬,模型還贏嗎?
相比完整的一天(收盤到收盤),「開盤到收盤」只涵蓋交易時段這一段。理論上,白天的股價波動和 VIX 的關係可能和整日不同。
這次測試就是要問:把 A4f 的訓練和預測目標都換成「開盤到收盤報酬」(A4f_oc),跟同樣設定下的基準模型(GJR_oc)比,還能顯著贏嗎?
這不是小改動。換掉 return 定義,意味著模型接收到的訓練訊號完全不同,參數需要重新估計,原先在「全日報酬」上學到的規律,不一定能平移過來。
怎麼測的
使用 SPY 從 2005 年到 2026 年 4 月的資料(n=5,350 個交易日),OOS(樣本外測試)從 2019 年起,共 1,828 個交易日。
模型每隔 63 個交易日(約一季)重新估計一次,共估了 30 次。這比「一次性估計完」更貼近真實,因為它不會把未來資料泄漏進去。
測試問了三個問題(H1/H2/H3):
- H1 :A4f_oc 有沒有顯著勝過 GJR_oc?
- H2 :A4f_oc 勝 GJR_oc 的幅度,有沒有超過原始 A4f_close 勝 GJR_close 的幅度(4.48)?
- H3 :把 OOS 拆成 5 個子期間,A4f_oc 每段都贏嗎?
結果:兩個通過,一個沒有
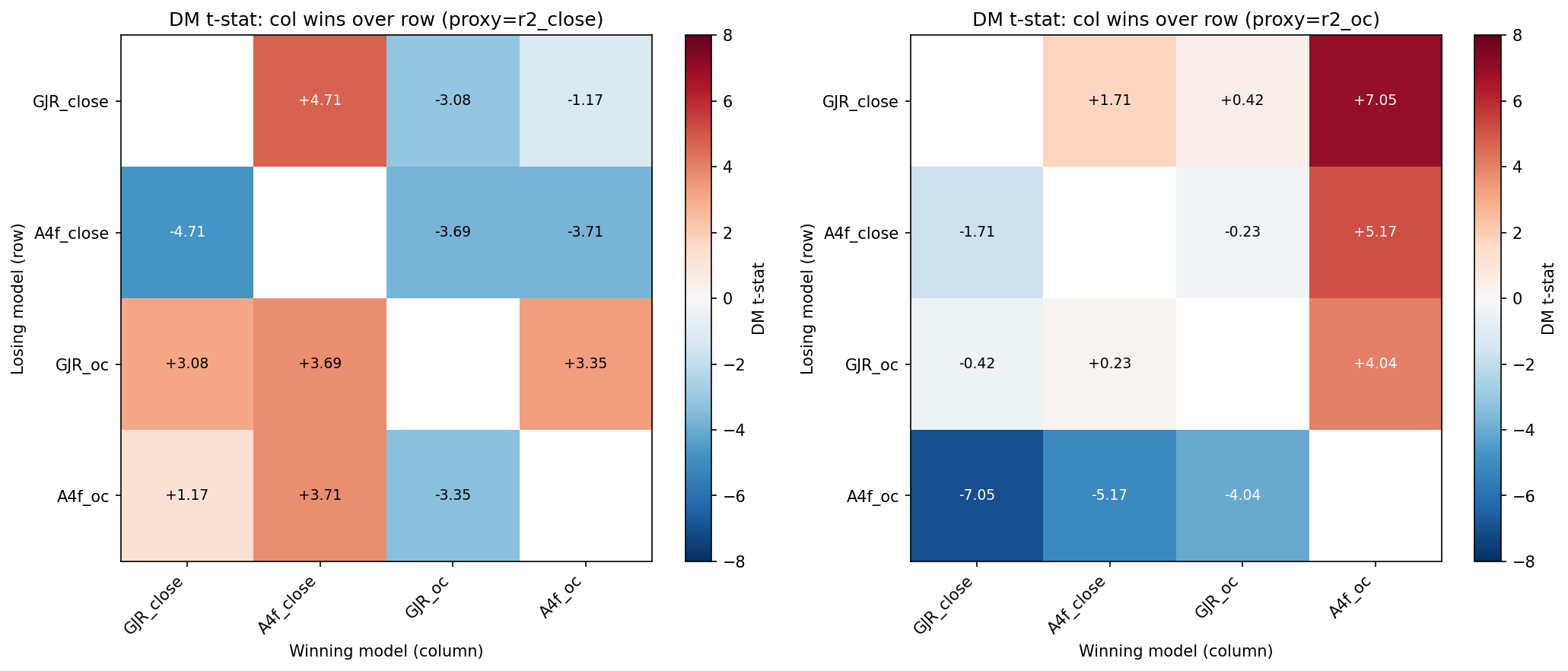
H1:通過 。DM t 值 = 4.04,超過 3.0 的門檻。A4f_oc 在開盤到收盤的設定下,仍然顯著勝過基準模型。這表示「把 VIX 乘進模型」這個核心機制,換了 return 定義還是有效。
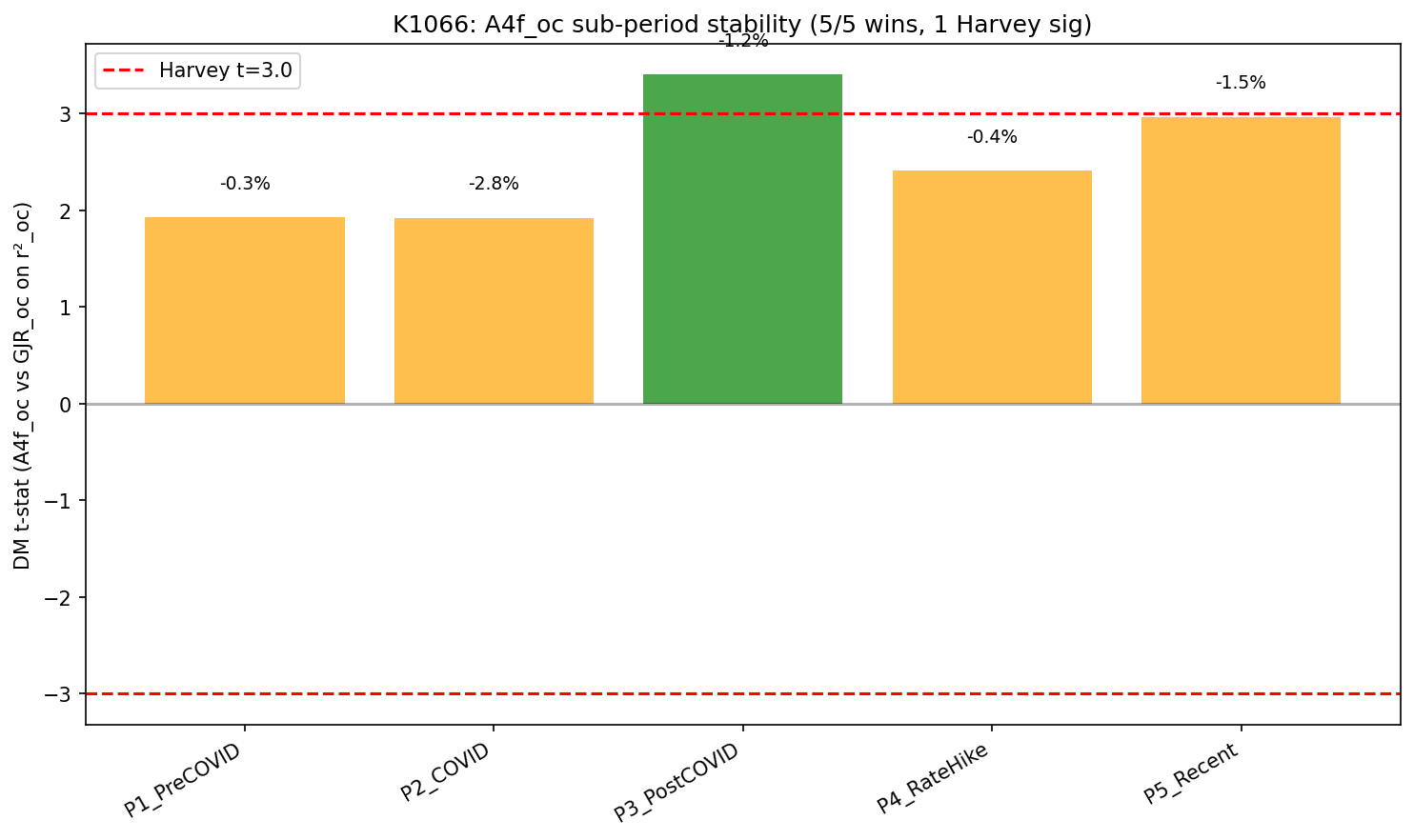
H3:通過 。五個子期間全部 A4f_oc 勝出(5/5)。如果只看勝負方向,五段全勝在簡單二項檢定下的機率是 3.1%;但五段裡只有一段達到嚴格的單段顯著門檻,所以這裡應解讀成「方向一致」,不是「每一段都強顯著」。這五段涵蓋了很不一樣的市場狀態:
| 子期間 | 市場特徵 | A4f_oc 結果 |
|---|---|---|
| COVID 前 (2019) | 相對平靜 | 勝 |
| COVID (2020-2021 上) | 極端波動 | 勝 |
| COVID 後 (2021 下-2022) | 通膨升溫 | 勝(最顯著) |
| 升息期 (2023-2024 上) | 利率高點 | 勝 |
| 近期 (2024 下-2026) | 科技強勢 | 勝 |
五段全勝支持這個框架不是只在某個特殊市場環境下才有效,但證據重點在方向穩定,不是每個子期間都單獨過關。
H2:沒通過 。DM t 值 = 4.04,沒有超過原始全日設定的 4.48。比較嚴格的說法是:A4f_oc 雖然顯著勝過自己的基準模型,但沒有超過事先設定的 4.48 高標;這裡沒有另外檢定「4.04 和 4.48 兩個統計量的差」。
H2 沒通過,代表什麼?
並不代表 A4f_oc 不好。比較穩健的解讀是:在這組相對基準下,完整的 close-to-close 設定仍略強,open-to-close 版本則提供了一個通過壓力測試的補充視角。
這有直覺意義。VIX 本身衡量的是未來 30 天的整體波動風險(含夜盤、隔夜風險、全日資訊),它對完整的 close-to-close 報酬的解釋力,自然可能比只看開盤到收盤那一段更強。
A4f_oc 的 DM t 值 = 4.04 已是「顯著」,只是沒超過全日設定下的 4.48 這個高標。
對一般投資人的意義
這個研究直接意義不大,絕大多數散戶不需要選「用哪種 return 算波動率」。
但有一件事是具體的: 同一個框架在五個相差很大的市場階段都贏 ,包括 COVID 的極端波動期、升息後的高利率期、近期的科技股強勢期。這種跨 regime 的一致性,比單一市場環境下的勝出更有說服力;但五段裡只有一段過嚴格單段顯著門檻,所以證據強度應該放在「方向一致」而不是「每段都強顯著」。
對波動率模型或量化策略有興趣的人,這種「換個計算方式還能贏」的壓力測試,是一個評估模型是否真的有效的標準做法,而不只是在某一組設定下硬調出最好結果。
A4f 框架通過了這個測試的兩個方向(H1 + H3),只在「勝幅要超過原始結果」這個額外挑戰上沒過(H2)。這個結果讓 A4f 論文的結論更可信,而不是更弱。
資料來源 :SPY OHLC 日線資料(yfinance)、CBOE VIX,資料期間 2005-01-04 至 2026-04-10(n=5,350 日);樣本外測試期間 2019-01 起,n=1,828 日。A4f 模型 rolling refit 視窗 2000 日、重估頻率每 63 日(共 30 次),seed=42。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊