五個不同起點都過關,這個跨市場模型不是剛好猜中一次
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
五個不同起點都過關,這個跨市場模型不是剛好猜中一次
做量化研究最怕的一種情況,是模型只在某一段時間剛好贏。
前一版 Paper 3 的結果裡,TW0050 和日本 N225 這一組,是跨市場配對裡最強、也最需要做起點敏感度壓力測試的案例。問題也正出在這裡: 如果最亮眼的那一組只在單一起點成立,會不會只是剛好挑到一段對它有利的樣本?
這次做的事很單純,就是把外樣本起點往前往後挪,從 2014、2015、2016、2017、2018 各跑一次,檢查同一個結論會不會一換起點就垮掉。
答案沒有模糊空間: 五個起點全部過關。
2014起跑:統計值3.242015起跑:3.892016起跑:3.662017起跑:3.042018起跑:3.09
這五個數字不只都高過 5% 門檻,連 1% 門檻也全部跨過。換句話說, 你把起跑線挪了五次,結果都還在同一邊。
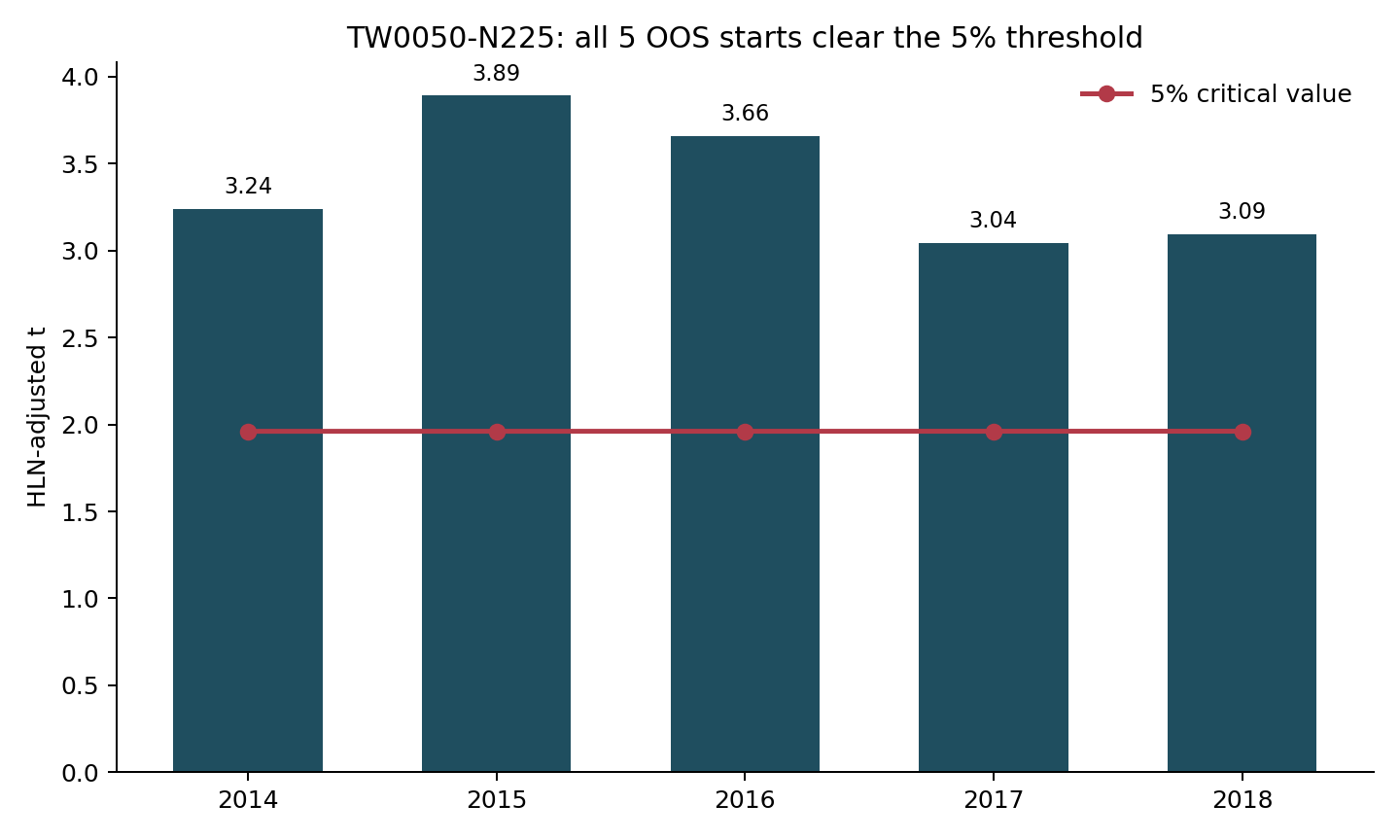
更重要的是,這五次不是勉強貼著門檻過。
最弱的一次是 2017 起跑,統計值 3.04,離 5% 臨界值還多出大約 1.08。最強的一次是 2015 起跑,距離門檻更高出 1.93。這代表結果離翻盤還有一段距離。即使挑到最不利的那個起點,還是留有安全空間。
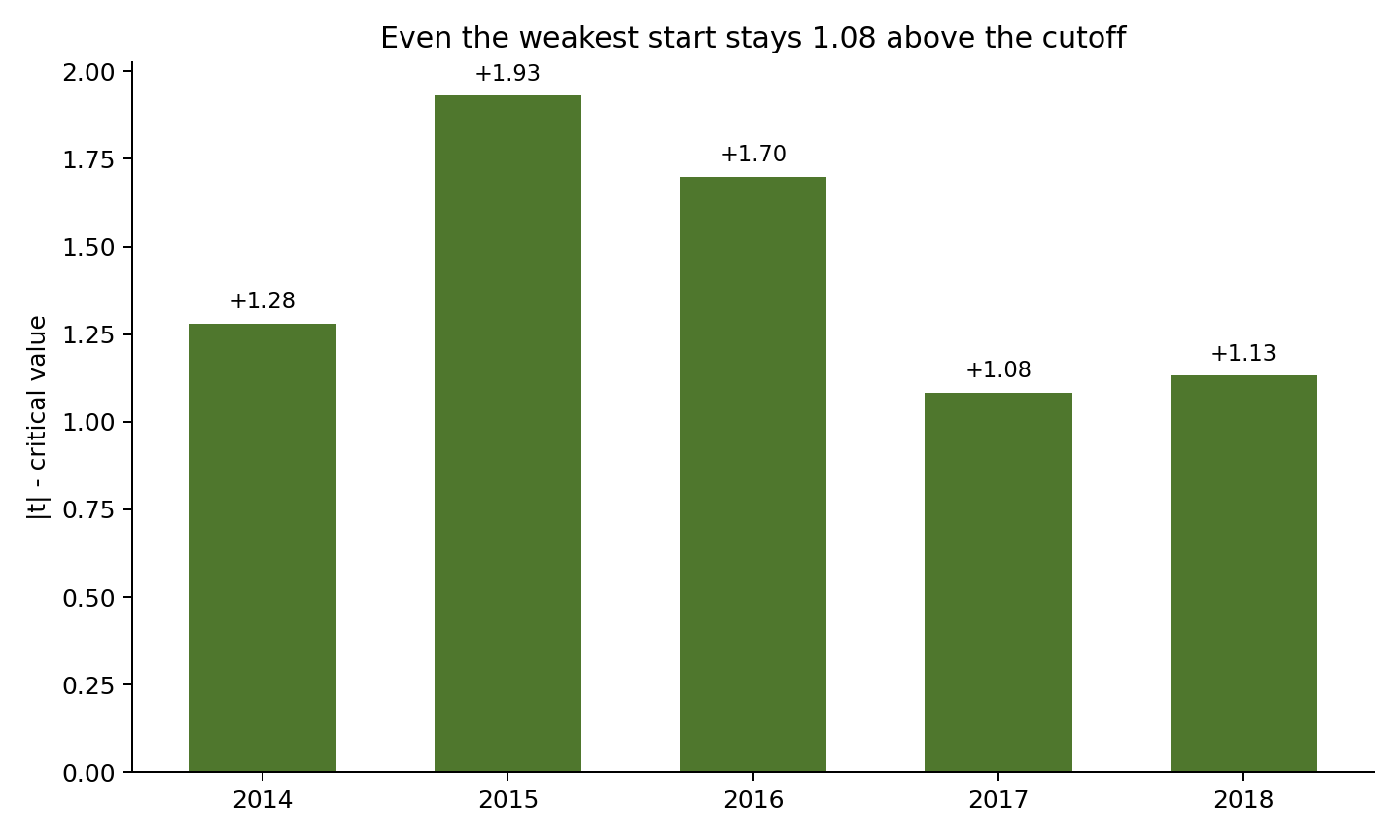
這件事對一般讀者真正有用的地方,在於一個更基本的判斷標準:
一個研究結果如果只在單一樣本起點成立,你要先懷疑;如果換了五個起點還成立,可信度就高很多。
當然,這也不代表可以把它講成「已經被證明五次」。這五個外樣本區間彼此有重疊,所以它比較像 同一個發現的五次壓力測試 ,不是五個完全獨立的新實驗。比較精確的說法是:這個優勢對外樣本起點的選擇, 目前看起來相當穩 。
所以,這次最值得記住的地方是:
它不是只在一個剛好的起點贏。
這對 Paper 3 很重要,因為這一組是主要顯著案例中最醒目的一個;最容易被挑戰的地方,就是「會不會只是樣本起點運氣」。現在至少在起點敏感度這一關,這個質疑沒有被數據支持。
本文基於實驗 K1416(腳本:experiments/k1416/k1416.py,結果:experiments/k1416/k1416_results.json),並引用前一步敏感度實驗 K1412。資料來源:TW0050 與 N225 跨市場配對之外樣本比較;基準外樣本起點 2015-06-01,另檢查 2014/2016/2017/2018 四個替代起點;基準有效樣本約 2,067 個交易日。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊