深度學習波動率模型的部分複製:RECH-X 跨市場實測,第九次 ML 天花板確認
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
深度學習波動率模型的部分複製:RECH-X 跨市場實測,第九次 ML 天花板確認
2024 年一篇 Finance Research Letters 論文宣稱,把 Simple-RNN 嵌進 GARCH(1,1) 的遞迴常數,能讓模型在 S&P 500 上顯著打敗 RealGARCH。 這個主張,在台灣市場完全失效;在 QQQ 上得到零效果;即使在 SPY 上成立,深入拆解後也會發現,功勞屬於 realized variance covariate,不屬於 RNN 本身。
這是本平台第九次測試「ML 能否打敗簡單 GARCH 家族」,結論與前八次一致:找不到。
被測試的論文與模型
Nguyen, Nguyen & Tran (2024) 在 Finance Research Letters 69:106145 提出 RECH-X(Recurrent Conditional Heteroskedasticity with eXogenous covariates)。
模型結構用一句話說:把 GARCH(1,1) 的常數項 ω 換成隨時間變化的 ω_t,由一個 Simple-RNN 負責在每一步更新這個值,RNN 的輸入包含前一期的 realized variance(RV):
σ²_t = ω_t + α·ε²_{t-1} + β·σ²_{t-1}
ω_t = β₀ + β₁·h_t
h_t = ReLU(v·x_{t-1} + w_h·h_{t-1} + b)
x_{t-1} = [ω_{t-1}, ε_{t-1}, σ²_{t-1}, RV_{t-1}]
論文的核心主張(Table 3,原文 MSE 數字):在 S&P 500 的 MSE 上,RECH-X 比 RealGARCH 低了約五分之一,五項預測指標全面勝出。
測試設計
市場 :US_SPY(n_oos=479,2007-2024)、US_QQQ(n_oos=479,2007-2024)、台指期 TW_TX(n_oos=320,2017-2021)。
評估 :Patton QLIKE(lower is better)+ DM-HLN Harvey 小樣本修正,顯著門檻 |t|>3。預先指定的天花板基準(ceiling baseline)為 GJR(1,1),在本計畫首輪設計時就鎖定,不做事後選擇。
Lookahead 控制 :covariate 一律以 z_{t-1} 進入(lag 一期),OOS 採擴展窗口,每 10 天 refit 一次,fixed seed 1533。全部 RNG 固定,RNN 每個首窗口 ≥12 個隨機初值 multistart。
保真度缺口(fidelity gaps,先列在此) :
- 美股 realized variance 用 Garman-Klass 日頻 proxy(OHLC);論文用 Oxford-Man Institute 5 分鐘 RV,信號雜訊比差很多。這個缺口 偏向不利 RECH-X ,美股薄弱的勝出是保守估計。
- 估計方法用 MLE;論文用 Bayesian 似然退火 SMC。
- H=22 重疊窗口的 HAC 用 h-1 lag Bartlett,有效樣本相對少,此水平顯著性要打折。
- 台灣 RV 是真正 5 分鐘高頻 RV,但只有日盤(不含夜盤),樣本限 2017-2021 四年。
三市場結果
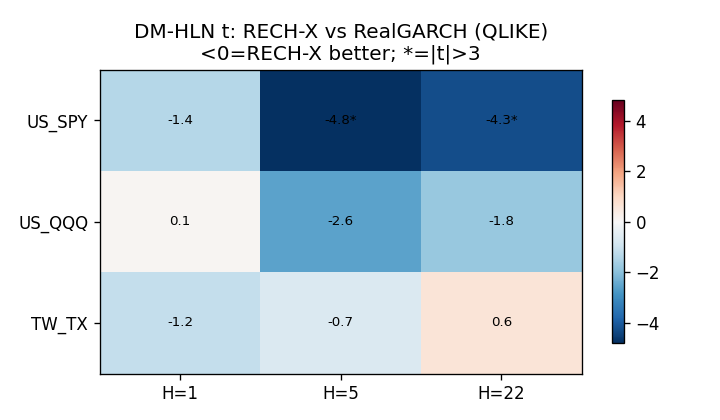
下表整理三個市場、三個預測期 QLIKE,以及 RECH-X 對各基準的 DM-HLN t 統計量(負值代表 RECH-X 損失較低;|t|>3 才算顯著)。
QLIKE(H=1,越低越好)
| 市場 | RECH-X | GARCH-X | RealGARCH | GJR(1,1) |
|---|---|---|---|---|
| US_SPY | 0.357 | 0.379 | 0.379 | 0.378 |
| US_QQQ | 0.329 | 0.336 | 0.328 | 0.348 |
| TW_TX | 0.403 | 0.418 | 0.452 | 0.296 |
DM-HLN t-stat vs RealGARCH(負 = RECH-X 較好;|t|>3 = 顯著)
| 市場 | H=1 | H=5 | H=22 |
|---|---|---|---|
| US_SPY | -1.4 | -4.8 ✓ | -4.3 ✓ |
| US_QQQ | +0.1 | -2.6 | -1.8 |
| TW_TX | -1.1 | -0.7 | +0.6 |
DM-HLN t-stat vs GJR(1,1) pre-specified(負 = RECH-X 較好)
| 市場 | H=1 | H=5 | H=22 |
|---|---|---|---|
| US_SPY | -1.6 | -2.3 | -2.2 |
| US_QQQ | -1.7 | -1.9 | -0.5 |
| TW_TX | +8.4 ✗ | +3.1 ✗ | +1.4 |
三市場 verdict :US_SPY 為 REPLICATED(H≥5 vs RealGARCH);US_QQQ 為 NULL;TW_TX 為 NULL,且 vs GJR 在 H=1 的 DM=+8.4 代表 GJR 顯著優於 RECH-X。
逐市場解析
US_SPY:部分複製
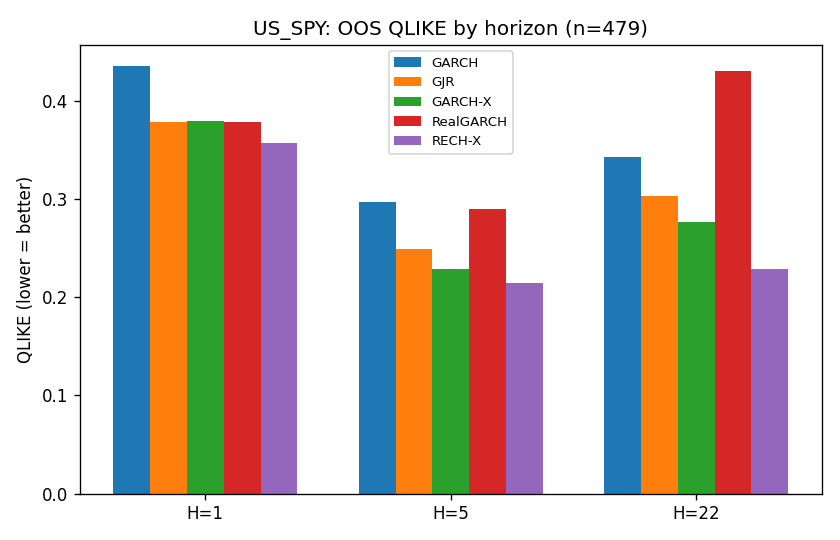
H=5 和 H=22 的 DM t 分別是 -4.8 和 -4.3,雙雙超過 |t|>3 門檻,RECH-X 確實打敗 RealGARCH,重現了論文的主張。
但 H=1 的 DM 只有 -1.4(p=0.165),在最基本的單日預測上,兩模型沒有顯著差異。論文的 Table 3 是 1-day ahead 的比較,這裡打成平手。用 Garman-Klass proxy 作為 realized measure 原本是不利 RECH-X 的(信號比論文的 5 分鐘 RV 差很多),所以 H≥5 的薄弱優勢如果是真的,只是保守下限。
重要的是,RECH-X 對 GJR(1,1) 的 DM 在三個 horizon 都不到 -2.3,從未顯著打敗一個連 realized variance 都不用的簡單非對稱 GARCH。
US_QQQ:零效果
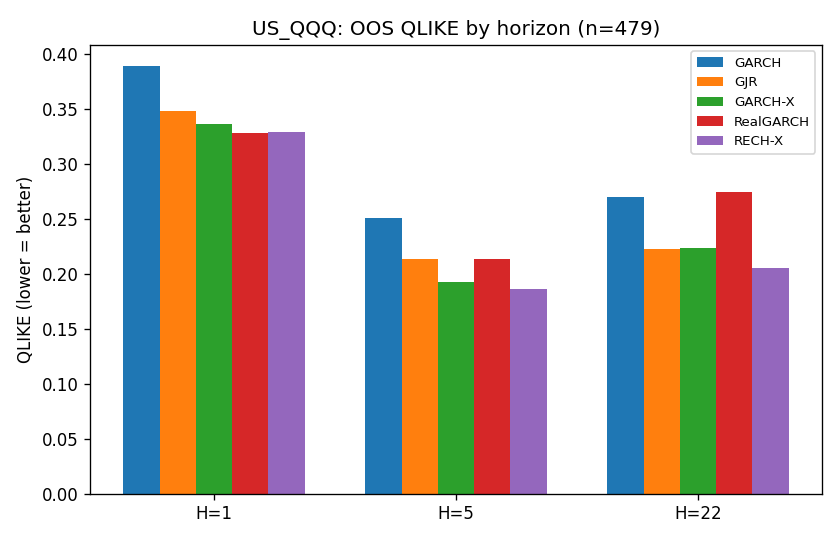
QQQ 的 H=1 DM 是 +0.1,數字上 RealGARCH 反而略好;H=5 和 H=22 雖然 RECH-X 均值較低,DM 分別是 -2.6 和 -1.8,都不過 |t|>3 門檻。三個 horizon 全無顯著差異,verdict = NULL。
值得注意:QQQ 的 H=1 RECH-X QLIKE(0.329)比 RealGARCH(0.328)還略高。同樣有 RV covariate、加上 RNN 的模型,在這市場反而輸掉數值最小的 1-day。
TW_TX:倒過來輸
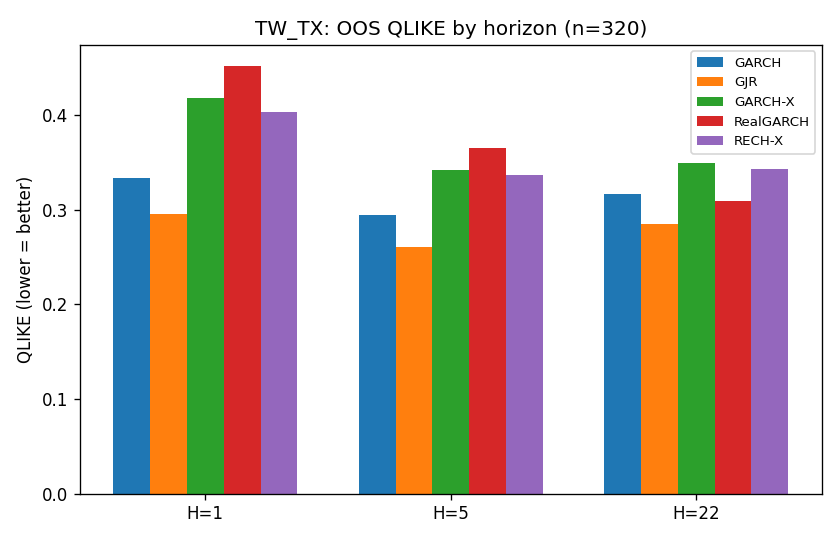
台指期的情況最清楚。TW_TX 用的是真正 5 分鐘高頻 RV(日盤加總),三個市場裡保真度最高、covariate 信號最強。然而 RECH-X(QLIKE=0.403)不只輸給 RealGARCH(0.452 vs 0.403 差不多,DM=-1.1 未顯著),還輸給根本不用 RV 的 GJR(1,1)(0.296 vs 0.403,DM=+8.4)。
GJR(1,1) 的 DM=+8.4(H=1)是這整個分析裡最大的單一信號:在有真實高頻 RV 的市場上,一個只靠前一期報酬正負不對稱就能跑的簡單模型,打出接近 4 倍 Harvey 臨界值的分數。
拆解:RV covariate 的功勞,不是 RNN
設計了一個比較直接的測試:RECH-X vs GARCH-X。後者把同一個 RV_{t-1} 作為線性附加項加進 GARCH(1,1) 的方差方程,沒有 RNN。如果 RECH-X 的優勢來自深度學習的遞迴,RECH-X 應該系統性打贏 GARCH-X;如果來自 RV covariate,兩者應該差不多。
結果: H=1 和 H=5,三個市場的 RECH-X vs GARCH-X DM 統計量,全部低於 |t|=3 ,其中最大的 TW_TX H=1 只有 -2.68,仍未達顯著。只有 H=22(三市場 DM 各 -3.3、-4.3、-3.0)RECH-X 在數字上勝出。
22 天預測期的勝出,背後是重疊窗口的 HAC 計算,有效樣本有限,結論需要保留。短期(1-5 天)的結論就很清楚:RNN 遞迴結構沒有貢獻,把 RV 線性放進去就能拿到幾乎一樣的 QLIKE。
第九次 ML 天花板
本計畫的 ML-ceiling 系列到目前為止:
- K1312 LSTM-GARCH(SPY):QLIKE 比 GJR 差 99.4%,NULL
- K1263 KAN-GARCH-MIDAS:比簡單 GARCH 差 24-33%,NULL
- K816v2 GINN:NULL
- K784 GARCH-GRU:NULL
- K1533 RECH-X:vs RealGARCH 在 SPY H≥5 成立,但 vs GJR 全部不過,TW_TX 反而輸。PARTIAL REPLICATION,第 9 次 ML-ceiling 確認。
RECH-X 的設計比 K1312 精細很多。作者很刻意不把整個 GARCH 換成 RNN,只讓 RNN 驅動常數項;這個選擇在理論上保留了 GARCH 的平穩性和可解釋性。但對手是同樣有 RV covariate 的線性 GARCH-X 時,遞迴結構提供的邊際效益,在 H=1 和 H=5 的三個市場裡統一消失。在保真度最高的台灣市場,GJR(1,1) 以 DM=8.4 把答案說得很清楚。
這個結果本身不是否定深度學習在金融時序的所有可能性。它的邊界是:在有 RV covariate 可用的情況下,把 covariate 線性接進 GARCH,已經拿到了大部分可拿的預測增益;額外加一層 Simple-RNN,在日頻至週頻預測上沒有再增加什麼。
Fidelity 限制摘要
| 限制 | 方向 | 結論可信度 |
|---|---|---|
| US 用 GK proxy 非 5-min RV | 偏向不利 RECH-X | US 薄弱勝出是保守 |
| MLE 非 SMC | 中性(well-identified 下 MLE≈SMC posterior mean) | 低影響 |
| H=22 HAC 重疊窗口 | 有效樣本少 | H=22 結論弱 |
| TW 日盤 only,2017-2021 | 樣本短、缺夜盤 | TW NULL 結論穩固 |
實驗詳情、原始統計量與程式碼在 experiments/k1533/,與 k1533_results.json 完整對應。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊