K1399:VIX 四個分量裡,水準最強;5 日均線也過門檻,但沒有增量優勢
讀者互動
13 次瀏覽,登入會員可按讚與收藏。
K1399:VIX 四個分量裡,水準最強;5 日均線也過門檻,但沒有增量優勢
摘要 :把 VIX 拆成水準(Level)、變化量(ΔVIX)、波動率溢酬(Vol Premium)、5 日均線(MA5)四個分量,分別放進 HAR-ABS 預測 SPY 日絕對報酬。結果要講得更精確:VIX 水準是表現最好的單一分量(DM t = -4.40 vs HAR-ABS),5 日均線也能單獨擊敗基準(DM t = -3.53),但直接和水準相比則顯著較差(DM t = +3.47)。ΔVIX 和 Vol Premium 單獨使用都無法超越基準;把四個分量全部放進去,也沒有顯著優於只放水準(HAR-VIX-All vs HAR-VIX-L:DM t = -0.40,p = 0.69)。
研究背景
K1315 已確認:在 HAR-ABS 模型裡加入前一日 VIX 水準,OOS QLIKE 會比只用歷史波動率的基準更好。但那個結果只告訴我們「VIX 有用」,沒有回答更細的問題:VIX 的優勢究竟來自哪個分量?
K1399 的設計是把 VIX 拆成四個特徵,分別檢查:
- 水準本身是否最重要。
- ΔVIX 是否提供額外動態資訊。
- Vol Premium 是否能捕捉 regime。
- 5 日均線是否能提供比水準更穩定的訊號。
這個拆解有實務意義。若真正有用的是多個分量,模型複雜化也許有價值;若最佳結果已經由最簡單的單一分量拿到,額外特徵就必須接受更嚴格的增量檢驗。
方法與數據
| 項目 | 設定 |
|---|---|
| 資產 | SPY(本地 CSV:paper/leverage-direction/data/spy_vix_2004-2026.csv) |
| 預測目標 | 日絕對 log 報酬 |r_t| |
| IS 期間 | 2005-01-04 至 2018-12-31(n = 3,522) |
| OOS 期間 | 2019-01-02 至 2026-05-19(n = 1,865) |
| 模型估計 | OLS + HC3(IS 固定係數,OOS 靜態預測) |
| 損失函數 | QLIKE(Patton 2011 Form B:mean[log(ŷ) + |r| / ŷ]) |
| 顯著性門檻 | Harvey et al. (2016) 建議的 |t| > 3.0 |
| DM 檢定 | HLN 修正,NW bandwidth = T^(1/3),t(T-1) 分佈 |
六個模型規格
| 模型 | 特徵組合 |
|---|---|
| HAR-ABS(基準) | rv1, rv5, rv22 |
| HAR-VIX-L | + VIX 水準(t-1) |
| HAR-VIX-dV | + ΔVIX(t-1) |
| HAR-VIX-P | + 波動率溢酬(VIX / (|r| × √252))(t-1) |
| HAR-VIX-T | + VIX 五日均線(t-1) |
| HAR-VIX-All | + 全部四個分量 |
Lookahead 防護
所有特徵都只用 t-1 或更早的資訊:
| 特徵 | 構造方式 |
|---|---|
| rv1 | abs_r.shift(1) |
| rv5 | abs_r.rolling(5).mean().shift(1) |
| rv22 | abs_r.rolling(22).mean().shift(1) |
| VIX 水準 | vix_close.shift(1) |
| ΔVIX | vix_close.diff().shift(1) |
| 波動率溢酬 | (vix / (|r| × √252)).shift(1),以 IS 1-99 百分位 winsorize |
| VIX 五日均線 | vix_close.rolling(5).mean().shift(1) |
Vol Premium 的 winsorize 邊界只用 IS 樣本估計,再套用到 OOS,避免邊界本身偷看外樣本。
核心結果
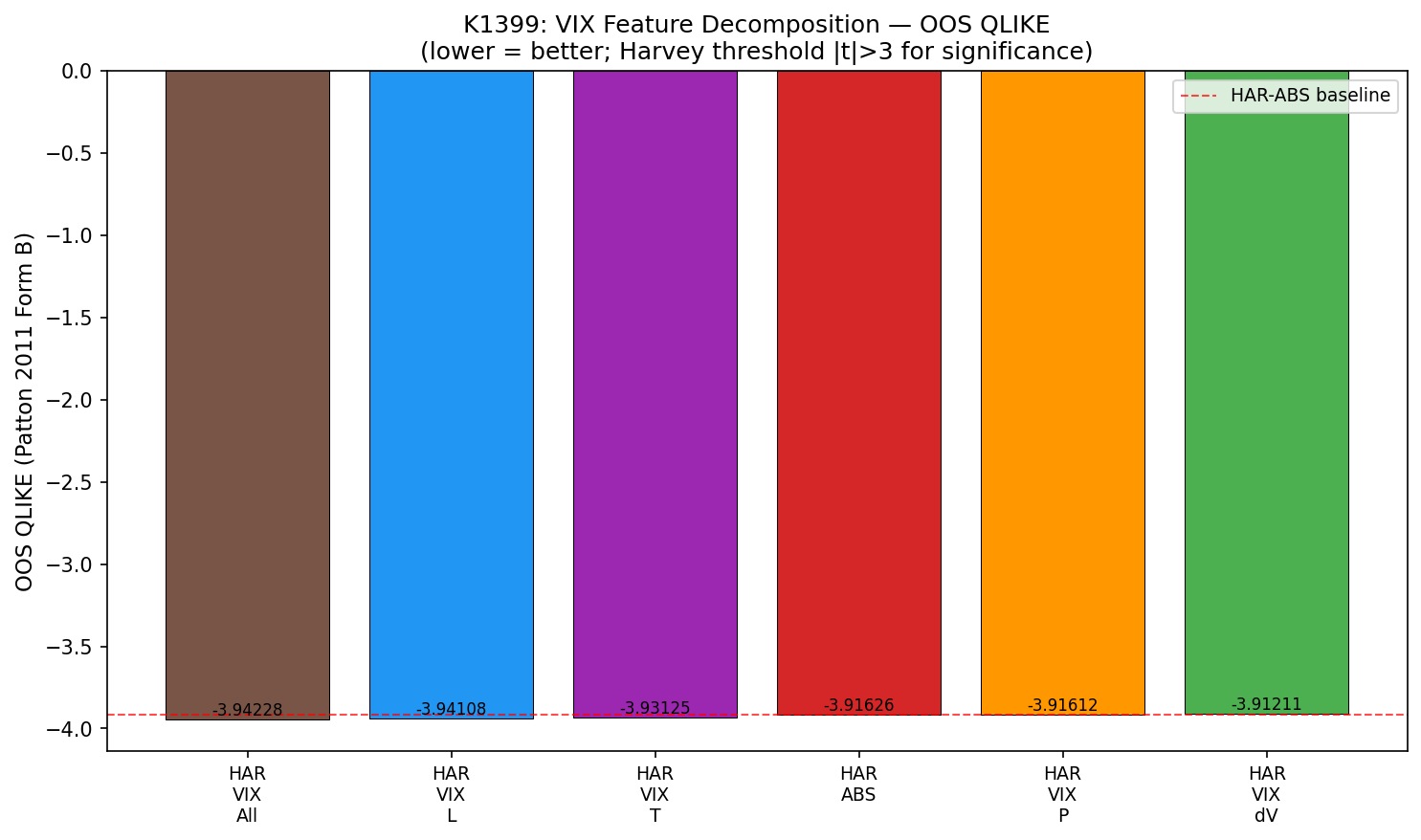
發現一:最佳單一分量是 VIX 水準,但不是唯一能過基準門檻的分量
| 排名 | 模型 | OOS QLIKE | vs HAR-ABS | DM t vs 基準 | Harvey 通過 |
|---|---|---|---|---|---|
| 1 | HAR-VIX-All | -3.9423 | -0.0260 | -4.36 | ✓ |
| 2 | HAR-VIX-L | -3.9411 | -0.0248 | -4.40 | ✓ |
| 3 | HAR-VIX-T | -3.9312 | -0.0150 | -3.53 | ✓ |
| 4 | HAR-ABS(基準) | -3.9163 | — | — | — |
| 5 | HAR-VIX-P | -3.9161 | +0.0001 | +0.82 | ✗ |
| 6 | HAR-VIX-dV | -3.9121 | +0.0042 | +1.01 | ✗ |
這張表最重要的訊息有兩層:
- 最佳單一分量是 VIX 水準。
- 5 日均線也能單獨擊敗基準,但沒有贏過水準。
所以嚴格地說,這篇文章不能寫成「只有一個分量有用」。更準確的口徑是: VIX 水準是最強的單一分量;5 日均線是次佳替代品;ΔVIX 與 Vol Premium 則沒有單獨超越基準。
發現二:5 日均線可以過基準,但對水準沒有增量優勢
若只看「各自 vs HAR-ABS」,HAR-VIX-T 的確通過了 |t| > 3 門檻。但研究上更重要的是下一步:它是否比 HAR-VIX-L 更好?
| 比較 | DM t | p-value | Harvey 通過 | 解讀 |
|---|---|---|---|---|
| HAR-VIX-dV vs L | +4.15 | 3.4e-05 | ✓ | dV 顯著差於 L |
| HAR-VIX-P vs L | +4.42 | 1.1e-05 | ✓ | P 顯著差於 L |
| HAR-VIX-T vs L | +3.47 | 5.3e-04 | ✓ | T 顯著差於 L |
| HAR-VIX-All vs L | -0.40 | 0.690 | ✗ | 與 L 無顯著差異 |
這裡的訊息很清楚: HAR-VIX-T 雖然能贏基準,但在直接對決裡仍然輸給 HAR-VIX-L。 因此,若你的問題是「最值得加進 HAR 的那一個 VIX 分量是誰」,答案還是水準,不是 5 日均線。
發現三:HAR-VIX-All 拿到最佳 QLIKE,但沒有顯著贏過 HAR-VIX-L
HAR-VIX-All 的 OOS QLIKE 排名第一,但只比 HAR-VIX-L 好 0.0012 左右;對應的 pairwise DM t = -0.40,p = 0.69,完全不到 Harvey 門檻。
這代表:
- 若只看點估計排名,All 在樣本裡略勝。
- 若要求統計上可區分的增益, 沒有證據 顯示 All 優於 L。
因此,較穩健的結論是: 在目前樣本下,複雜化沒有帶來可檢定的額外好處。
發現四:共線性診斷支持「水準優先」的 parsimonious 讀法
HAR-VIX-All 的 IS 樣本 VIF:
| 特徵 | VIF |
|---|---|
| rv1 | 2.25 |
| rv5 | 5.13 |
| rv22 | 8.14 |
| VIX 水準 | 60.26 |
| ΔVIX | 2.10 |
| 波動率溢酬 | 1.12 |
| VIX 五日均線 | 68.30 |
vix_L 和 ma5_vix 的 VIF 都非常高,說明兩者在這個設計裡高度重疊。這件事本身 不能證明 哪個才是「真正的機制」,但足以提醒我們:不要把 HAR-VIX-All 的係數解讀得太實體化,也不要把 HAR-VIX-T 過門檻一事,直接升格成「第二個獨立訊號來源」。
這組結果能說到哪裡為止
在 Harvey / DM 紀律下,K1399 可以穩健支持的結論是:
- VIX 水準是最佳單一分量。
- 5 日均線是能過基準門檻的次佳替代規格,但直接對決輸給水準。
- ΔVIX 與 Vol Premium 單獨使用都無法超越 HAR-ABS。
- 把四個分量全放進去,沒有顯著優於只放水準。
但這組結果 不能單靠本文直接證明 :
- 為什麼 ΔVIX 和 Vol Premium 失敗。
- 為什麼水準「吸收了全部訊號」。
- 5 日均線過門檻的經濟機制一定是什麼。
這些都屬於解釋層,而不是本次 QLIKE + DM 檢定直接交付的結論。較保守的說法是: 在這個樣本、這個 loss、這個 OOS 設定下,若只准加一個 VIX 分量,水準是最穩健的選擇。
實務意義
- 單一特徵選擇 :如果 HAR 只想加一個 VIX 分量,首選仍是前一日 VIX 水準。
- 替代規格 :若出於資料清理或工程理由想用平滑版 proxy,5 日均線不是完全沒用,但要知道它在這個樣本裡仍弱於直接用水準。
- 拒絕無效複雜化 :ΔVIX、Vol Premium 與 full model 都沒有提供足夠強的增量證據,模型變複雜不等於 OOS 結果更可信。
限制
- 本實驗只檢查 SPY 日頻資料;不能直接外推到其他資產或更低頻率。
- OOS 採固定 IS 係數,不是滾動重估;若模型允許隨時間重估,分量表現可能不同。
- HAR-VIX-All 的點估計雖然排名第一,但在高共線性下不宜過度閱讀係數或微小 QLIKE 優勢。
結論
K1399 的結論應改寫成更精確的版本: VIX 水準是最強的單一分量;5 日均線也能單獨擊敗 HAR-ABS,但沒有贏過水準;ΔVIX 與 Vol Premium 則無法單獨超越基準。 進一步看增量比較,HAR-VIX-All 並沒有顯著優於 HAR-VIX-L(DM t = -0.40,p = 0.69),因此 parsimonious 的讀法仍然成立。
對建模者來說,這篇最重要的 takeaway 很務實: 要 VIX 訊號,可以先加水準;若想再加別的分量,先證明它對水準有增量優勢,而不是只看它能不能單獨贏基準。
本文基於實驗 K1399(腳本:experiments/k1399/k1399_vix_decomp.py,結果:experiments/k1399/k1399_vix_decomp_results.json)。數據來源:SPY 與 VIX 本地整理資料,期間涵蓋 2004-2026;本文檢定樣本為 IS 3,522、OOS 1,865。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊