風險模型不是愈高級愈安全:最土的方法反而最少踩線
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
風險模型不是愈高級愈安全:最土的方法反而最少踩線
做風控的人很容易有一個直覺:模型愈進階,尾巴抓得愈胖,應該就愈安全。
這次實驗給了一個不太討喜但很實用的答案。拿同一套底層波動模型,去配四種不同的尾端估法後,真正最不容易踩到 1% 風險線的,不是看起來比較高級的 Student-t,而是最樸素的 Historical Simulation(簡稱 HistSim),以及和它打平的「直接估分位」。
這次測的是 SPY,樣本外期間是 2023-01-01 到 2024-12-31,共 502 個交易日。你可以把它想成一個簡單問題:
如果市場最糟的那 1% 日子真的來了,哪個方法最不容易把風險估太淺?
先看最重要的一張圖
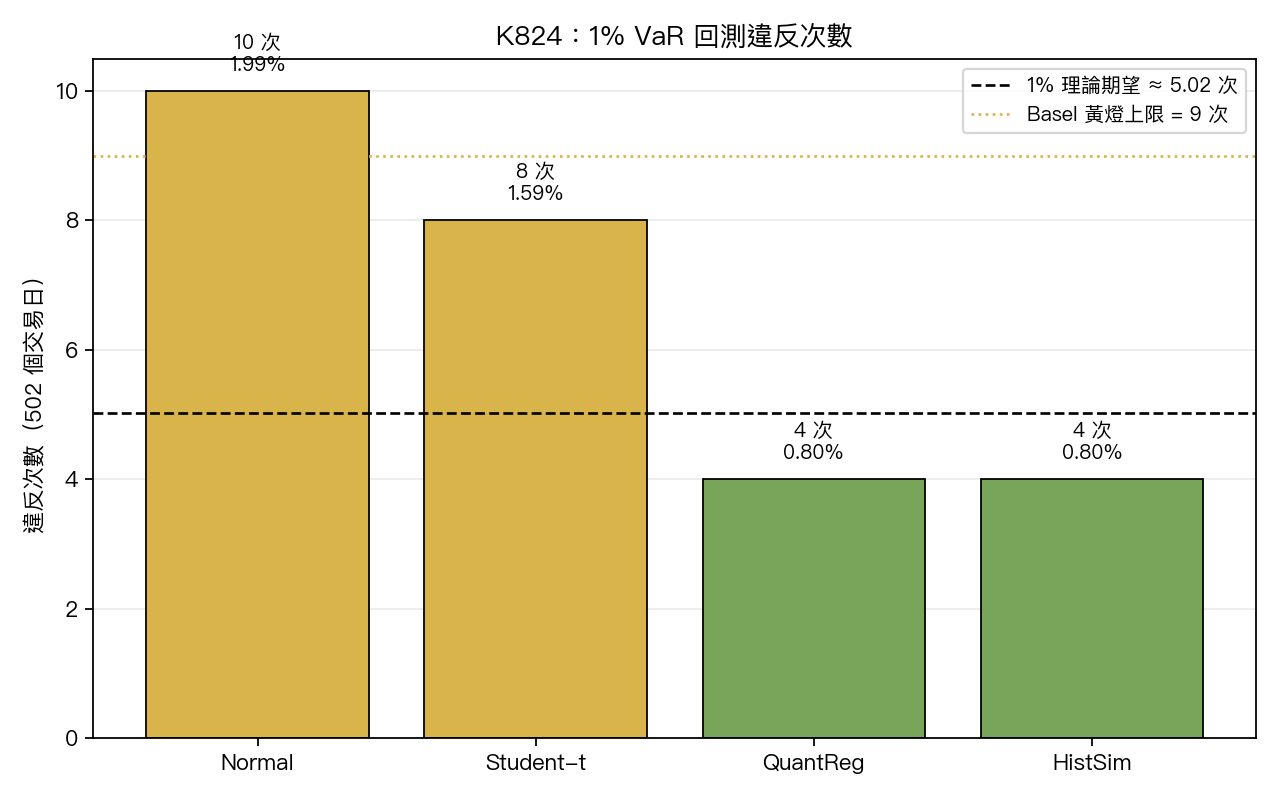
理論上,502 個交易日裡,這條 1% 風險線大概該被擊穿 5 次左右。
實際結果是:
| 方法 | 違反次數 | 違反率 |
|---|---|---|
| Normal | 10 | 1.99% |
| Student-t | 8 | 1.59% |
| 直接估分位 | 4 | 0.80% |
| HistSim | 4 | 0.80% |
這張表的重點在順序,不在小數點。
Normal 最差,Student-t 有進步,但還是偏多。真正把違反次數壓到最穩的是「直接估分位」和 HistSim,兩者 並列贏家 ,違反次數都只有 4 次。
奇怪的是,精度分數幾乎沒差
更反直覺的地方在這裡。
同樣四個方法去比平均表現分數,幾乎打成平手。
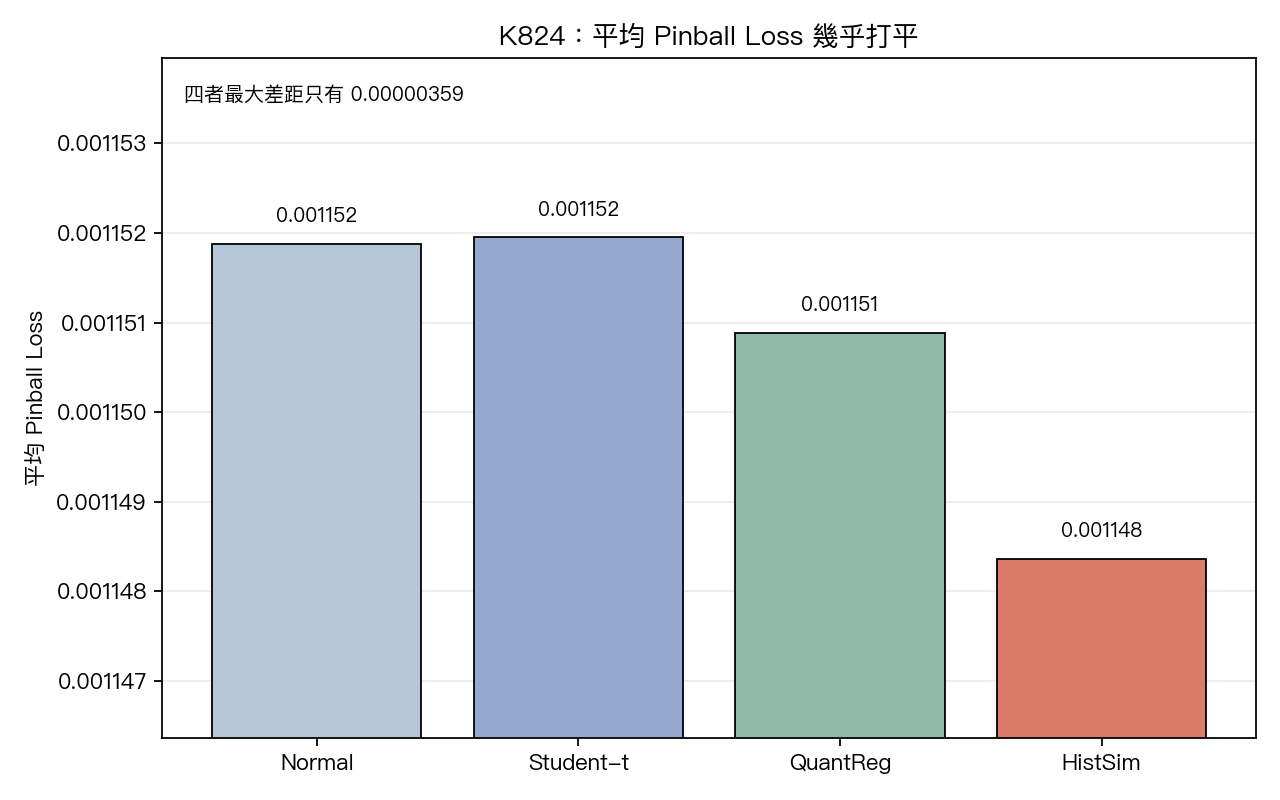
四者最大差距只有 0.00000359。換句話說:
- 你若只看平均分數,會覺得四種方法差不多
- 但你一旦看
1%尾端回測,差別立刻拉開
這正是這篇最值得記的一句話:
尾端怎麼估,不太改變平均分數,卻會直接改變你在最壞日子的失手次數。
順帶一提,這次跑了正式的 Diebold-Mariano 檢定比較四個方法的平均分數,所有兩兩差距的 p 值都不到顯著。換成白話: 就「平均分數」這個指標而言,四個方法統計上分不出勝負 。真正分勝負的,是「最壞那幾天」的尾端違反次數。
為什麼會這樣
因為這四個方法吃的是同一個波動率底盤。前面的模型已經先把「明天大概有多晃」估出來了,後面真正分勝負的,是你怎麼把這個波動率轉成最壞情況的保守邊界。
Normal 的問題是尾巴太薄,市場真的摔深一點時,它容易低估風險。
Student-t 確實比 Normal 厚尾,所以從 10 次違反降到 8 次,這步方向是對的。但它還是在用一個固定分配去描述尾巴,彈性有限。
HistSim 則是乾脆不先假設分配長什麼樣,而是直接拿歷史殘差的經驗分位數來估。市場尾巴如果本來就歪、就厚,它比較容易原樣保留下來。
所以這篇不是在說 Student-t 沒用,而是在說:
當你真的在乎「最壞那幾天會不會估太淺」,分配假設本身比平均精度更重要。
對一般讀者最實用的翻譯
如果你把風險模型當成煞車系統,平均手感分數比較像平常開車時的順不順;1% 風險線的違反次數,比較像真正急煞那幾次有沒有煞住。
平常手感差不多,不代表急煞表現也差不多。
這次的結果就是:
- 平均手感四台車差不多
- 真正急煞時,
HistSim和「直接估分位」並列最穩 Normal最容易煞不住
如果你真的要選一個做法
這份實驗給的實務排序很直白。
第一線並列的是 HistSim 和「直接估分位」。兩者在 1% 風險線都只違反 4 次,尾端回測一樣乾淨。如果你只能挑一個無假設、容易解釋的做法,HistSim 是直覺首選。
第二層是 Student-t。它比 Normal 好,但還不夠好到讓你放心。
最不該偷懶的,是直接用 Normal。在這組 SPY 樣本裡,它把最糟情況低估得最明顯。
給技術讀者的兩個揭露
第一,HistSim 在這次實驗裡是 每天 用最新的歷史殘差重算一次經驗分位數;Student-t 的自由度和迴歸式的分位數模型則是 每 63 個交易日 才重估一次。沒有看到未來的資料(time-of-day 對齊都是 t-1 為止),但 HistSim 等於享有比較頻繁的局部更新節奏,這個操作差異會給它一些優勢。比較公平的進階測法是讓所有方法用一樣的更新頻率,這留給後續實驗。
第二,這次用的「綠黃紅」燈號是依違反率簡單切的內部規則,跟 Basel 250 天計次規則不完全相同。若要做監管合規報告,建議改用官方計次門檻而非本文的簡化版。
這篇結論只有一句
風險管理裡,真正讓你出事的是最壞那幾天低估太多,平均分數輸一點反而其次。這次實驗告訴我們,這件事上最土的 HistSim 反而和「直接估分位」並列贏家,比看起來更高級的 Student-t 更耐尾端。
本文基於站內 SPY 風險估計實驗(K824)。數據來源:yfinance SPY,樣本外期間 2023-01-01 至 2024-12-31,共 502 個交易日。經 Codex source-code review,CONDITIONAL_PASS。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊