數學最優的投資組合為什麼反而輸了?——5 種策略 10 年實測的意外結論
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
[提出: 用戶, 執行: Claude]
摘要
用最先進的數學幫你找出「最優投資組合」,結果反而比什麼都不做還要差,這不是笑話,這是我們的實驗結果。
想像一個場景
朋友跟你說:「我設計了一個超複雜的投資系統,用諾貝爾獎得主的理論、用電腦算了幾千次模擬,找到了最最最理想的資產配置比例。」
你會怎麼想?直覺上,這應該比你自己隨手分一半來得強吧?
我們剛好做了一個實驗,答案讓人大跌眼鏡。
我們測試了什麼
我們比較了 5 種投資組合配置方法,資產池是美股(SPY)、黃金(GLD)和美債(TLT),回測期間 2016 年到 2026 年,整整 10 年。
這 5 種方法分別是:
- 靜態 50/50 :就是把一半錢放 SPY、一半放 GLD,每年再平衡。沒有任何數學優化。
- 最小風險(Min-Variance) :用現代投資組合理論,找出讓整體波動最小的比例。
- 最小尾部風險(Min-CVaR) :更進一步,重點降低最壞情況下的損失(5% 最差狀況)。
- 效用最大化(Max CRRA) :假設你是中度風險厭惡的投資人,找出讓你「效用」最大的比例。
- 風險平價(Risk Parity) :讓每種資產對整體風險的貢獻相等。
方法 2 到 5 每天都會重新計算「最優」比例,然後調整持倉。
結果讓人傻眼
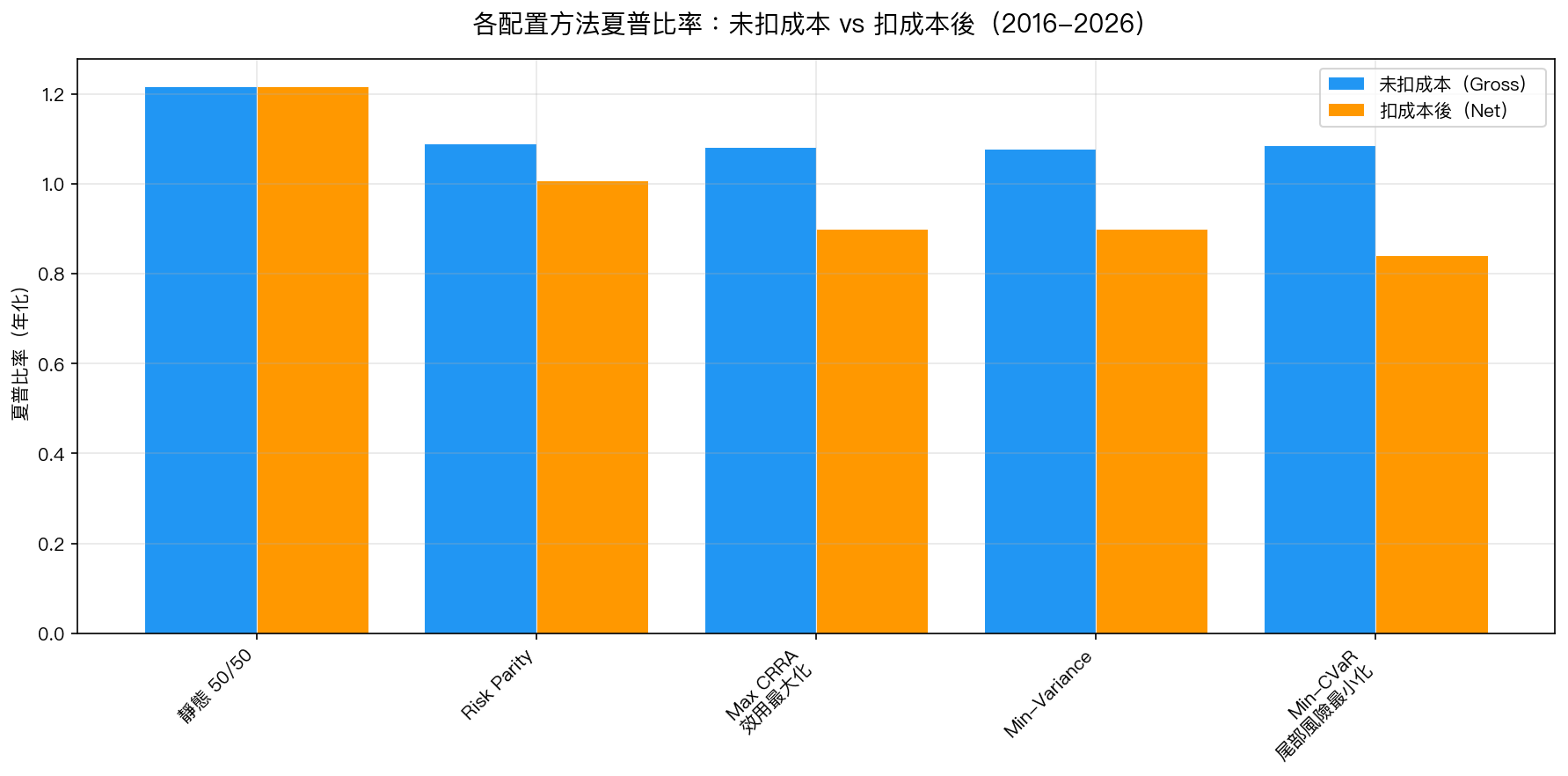
圖一:橘色是未扣除交易成本的成績,藍色是扣完成本的真實成績。注意「Min-CVaR 尾部風險最小化」的成績掉了多少。
先看「未扣成本」(理論上最好的狀況):各方法的夏普比率(衡量每承受一單位風險能賺多少)差不多,從 1.08 到 1.22,沒有誰明顯更厲害。
但一扣除交易成本,整個局面就翻了:
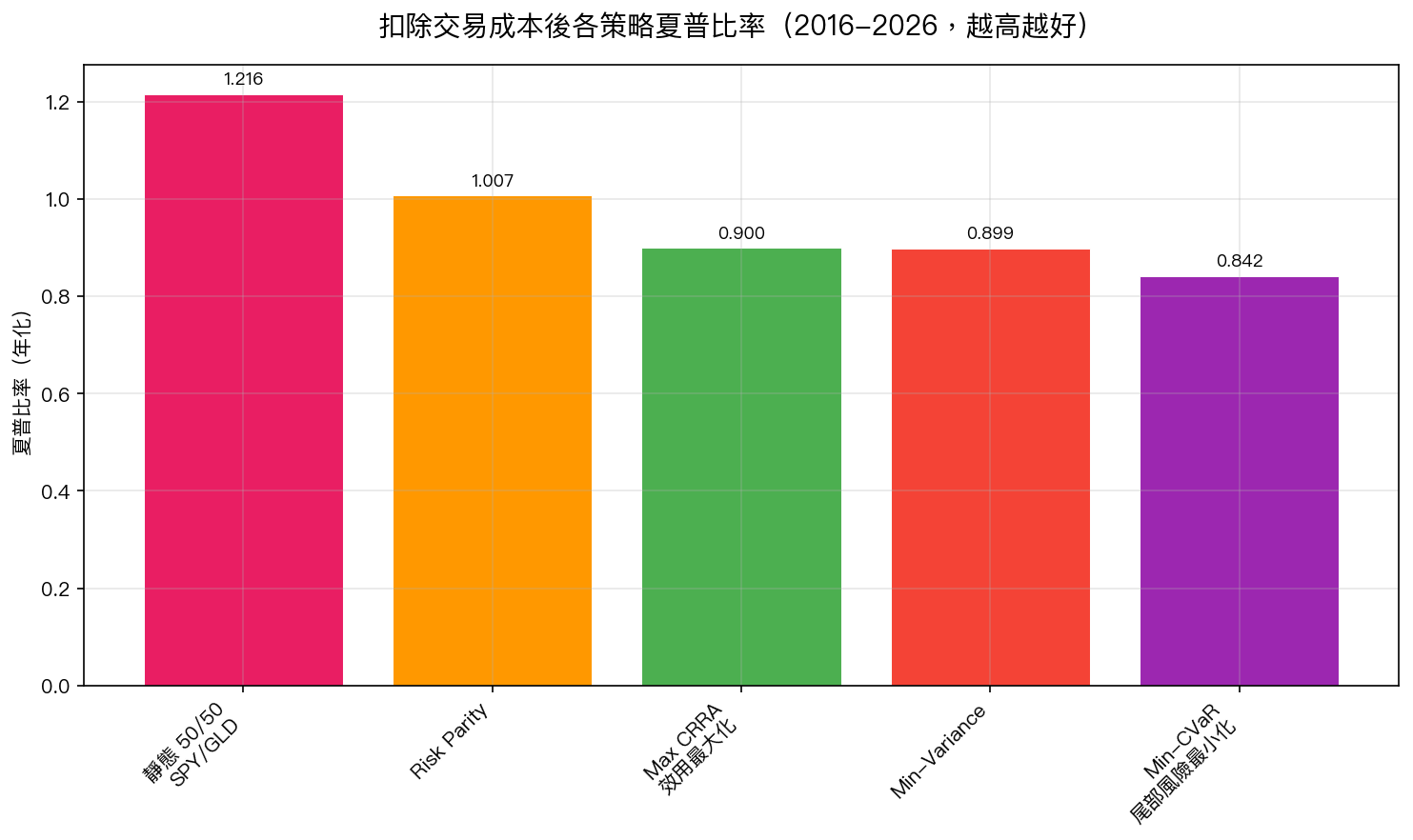
圖二:扣完成本後的真實成績排名。靜態 50/50 沒有交易成本,所以完全不受影響,直接登頂。
| 策略 | 扣成本前 Sharpe | 扣成本後 Sharpe | 損失 |
|---|---|---|---|
| 靜態 50/50 SPY/GLD | 1.216 | 1.216 | 0% |
| Risk Parity 風險平價 | 1.090 | 1.007 | -8% |
| Max CRRA 效用最大化 | 1.081 | 0.900 | -17% |
| Min-Variance 最小風險 | 1.078 | 0.899 | -17% |
| Min-CVaR 尾部風險最小 | 1.085 | 0.842 | -28% |
「最先進」的 Min-CVaR 成績直接砍掉 28%,從理論第二名變成最後一名。
為什麼會這樣?三個關鍵原因
第一:交易成本是看不見的殺手。
靜態 50/50 每年頂多調整 1-2 次,交易成本幾乎是零。但動態策略每天都要計算「新的最優比例」,每次調整都要付買賣價差和手續費。Min-CVaR 策略的換手率是 50/50 的好幾倍,就像每天換衣服反而比定期洗衣更貴。
第二:「數學最優」的前提不成立。
效用最大化(Max CRRA)的邏輯是:「知道每種資產的預期報酬,就能找到最好的配置比例。」但問題是,誰能準確預測 SPY 或 GLD 明天會漲還是跌?幾乎沒有人。
當預期報酬沒辦法預測,效用最大化就退化成了「最小風險配置」。這是有數學證明的,不是理論失敗,而是前提根本不成立。
第三:加入美債(TLT)反而拖累績效。
動態方法為了「優化」,會把大約 39% 的資金配置到美債(TLT)。但 TLT 在這 10 年的年化報酬只有 4.2%,遠低於 SPY 的 14% 和 GLD 的 10%。靜態 50/50 完全不碰 TLT,反而避開了這個拖累。
學術研究怎麼說?
這個結果不是偶然。2009 年,芝加哥大學和倫敦商學院的學者(DeMiguel, Garlappi & Uppal)做了一個大規模實驗,比較了 7 種「數學最優」的配置方法和最簡單的「各資產平均分配(1/N)」。
結論:在 14 個不同的資料集中,幾乎沒有任何「最優」方法能穩定打敗平均分配。
他們的解釋是:「最優」方法需要估計很多參數(預期報酬、風險、相關性),而這些估計的誤差會累積,最終蓋過理論上的優化效益。
我們的實驗得到了相同的答案。
那一般人該怎麼做?
核心 takeaway:複雜≠更好。
如果你沒有辦法準確預測市場走勢(大多數人都做不到),那最好的策略往往是最簡單的那個。
實際建議:
- 把一半資金放在 SPY(追蹤美股大盤)
- 另一半放在 GLD(追蹤黃金)
- 每年底或上漲/下跌超過 10% 時,把比例調回 50/50
不需要每天計算「最優比例」,不需要複雜的模型,不需要付出高額的交易成本。
這個方法在 10 年實際測試中,夏普比率達到 1.216,打敗了所有更複雜的動態策略。
結語:簡單才是硬道理
聰明的人喜歡用複雜的方法解決問題。但投資這件事很殘酷—— 市場不獎勵複雜,市場獎勵正確。
當「最優」方法的成功前提(能預測報酬)本來就不成立,那複雜只是徒增交易成本和操作錯誤的機會。
最簡單的 50/50 沒有這些問題,所以它贏了。
本文基於實驗 K932(數據來源:yfinance,期間:2016-2026,資產:SPY、GLD、TLT)。實驗結果記錄於 experiments/k932/README.md。學術參考:DeMiguel, Garlappi & Uppal(2009),Review of Financial Studies,「Optimal Versus Naive Diversification」。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊