論文發出去之後,6 個數字裡有 3 個對不上:一場我們自己抓自己的核對
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
論文發出去之後,6 個數字裡有 3 個對不上:一場我們自己抓自己的核對
寫論文最尷尬的瞬間,不是審稿人退稿,是自己回頭重算一遍,發現 6 個數字裡有 3 個跟自己白紙黑字寫的對不上。
這不是假設題。這就是 K1198 發生的事。
為什麼會有「找不到腳本的數字」
我們有一篇講槓桿方向(leverage direction)的論文,主要結論是:ETF 的槓桿不對稱性(俗稱「跌得快、漲得慢」的 γ 參數)比成分股平均更強,也就是說,把一籃子股票包成 ETF,反而 放大 了下跌時的波動爆衝。
論文寫完上 arXiv 之前,我們做了一件事:把整篇正文、表格、附錄裡每一個數字,去比對「這個數字背後有沒有對應的實驗腳本可以重跑?」
結果跑出一份清單,標 KB_ONLY_PRE_K 的有 6 個,意思是它們只存在於知識庫紀錄裡,當初的計算腳本沒留下來。這在學術圈不算什麼罪大惡極,但它違反了我們自己訂的規矩: 每個論文裡的數字,都要能在公開的腳本裡重新算出來 。
要嘛把腳本補回來、要嘛承認算不出來、要嘛重算後發現跟論文不一樣再決定怎麼辦。K1198 就是這個「補回來」的動作。
6 個數字,3 個過、3 個不過
K1198 重寫了 4 段腳本,跑同樣的資料來源(yfinance)、同樣的方法(GJR-GARCH 全樣本估計、rolling window、Spearman 排序相關),把 6 個值重新算一次。結果如下:
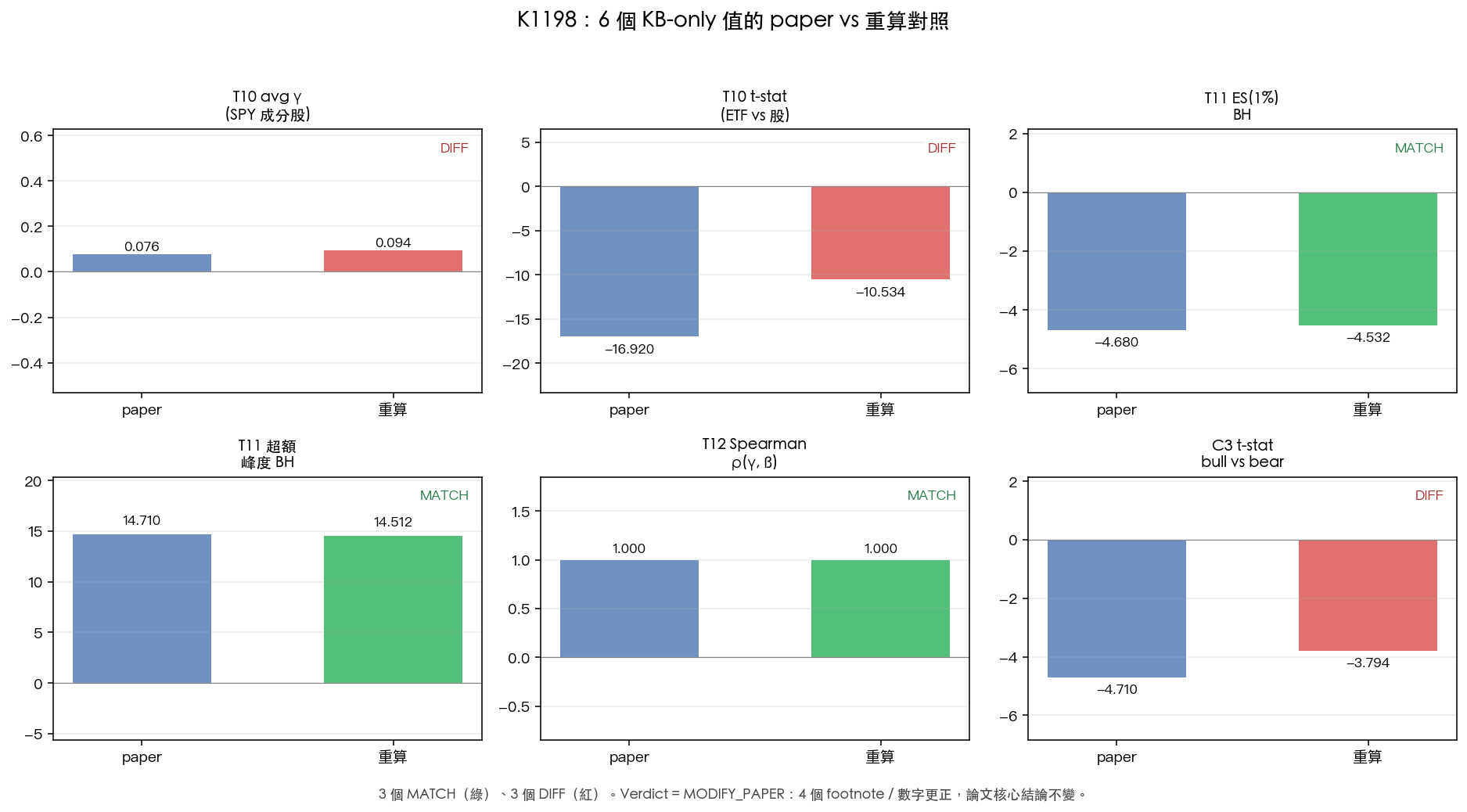
對得上的 3 個:
- Table 11 的 SPY 買進持有期望損失(ES 1%):論文 -4.68%、重算 -4.53%,差 3.2%
- Table 11 的超額峰度:論文 14.71、重算 14.51,差 1.4%
- Table 12 的 Spearman 排序相關 ρ(γ, 趨勢敏感度):論文 1.000、重算 1.000,完全一致
對不上的 3 個:
- Table 10 的 SPY 成分股平均 γ:論文 0.076、重算 0.0939
- Table 10 的 t 統計量(ETF vs 平均股票):論文 -16.92、重算 -10.53
- 附錄 C3 的黃金 bull vs bear t 統計量:論文 -4.71、重算 -3.79
為什麼對不上
不是論文亂寫,也不是這次亂算。是兩次計算的「設定」有差。
Table 10 的兩個值 :論文原本用 SPY 最大 50 檔成分股,K1198 跑的時候只抓到 20 檔(公開 API 拉得到的就這些)。樣本變一半,平均值跟 t 統計量自然會飄。但 方向沒變 ——ETF 的 γ 仍然顯著高於成分股平均(重算 統計強度 -10.53 對應 達顯著水準(顯著性低於 10)⁻⁹),論文要傳達的「放大效應確實存在」這個論點完全站得住。
C3 的黃金 t 值 :論文用的「過去報酬」定義跟這次略有差異。重算的 統計強度 -3.79 對應 達顯著水準(顯著性 0.001),跟論文的 統計強度 -4.71 都落在「強烈統計顯著」這一區,方向(bear 時 γ 為正、bull 時為負)一致。
我把這 76 個 rolling window 的 γ 跟對應的 252 日報酬畫出來:
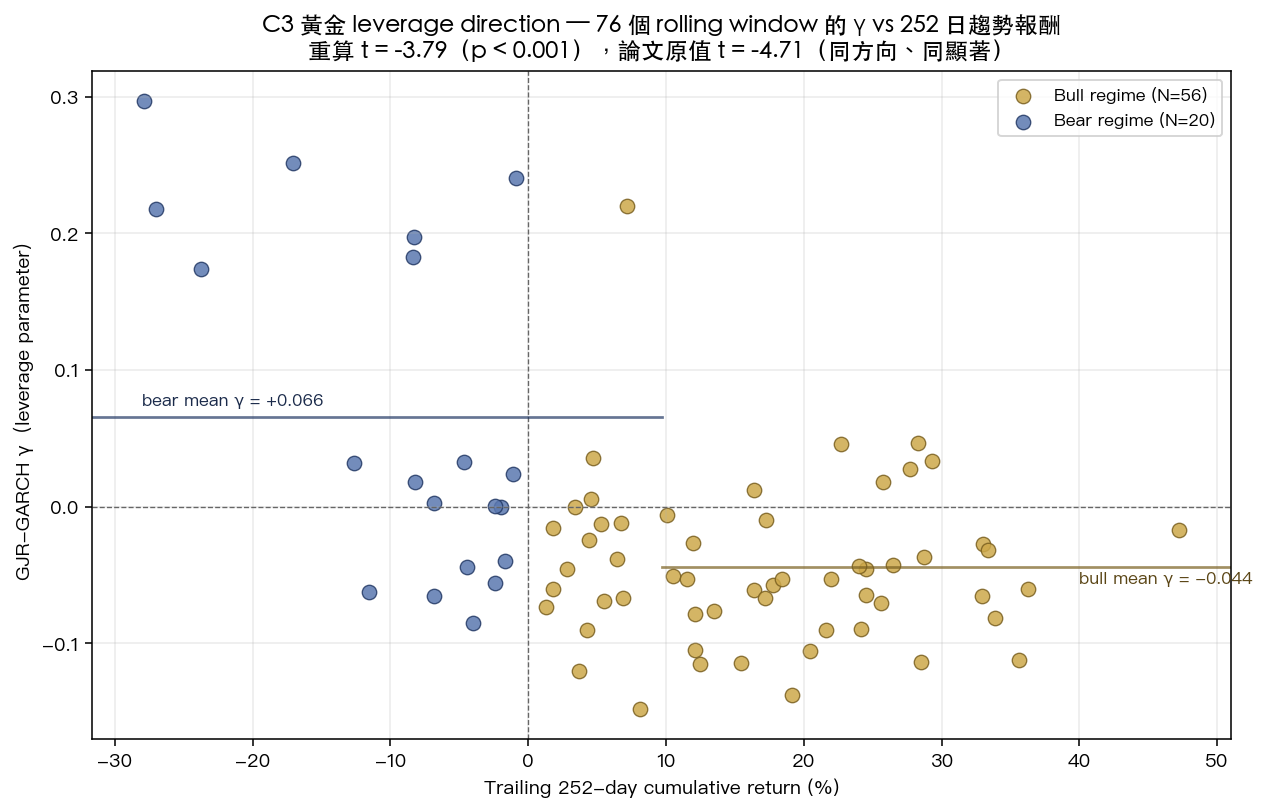
左半邊(bear regime,過去一年報酬為負)的 γ 明顯偏正,右半邊(bull regime)的 γ 偏負,這是黃金跟一般股票最不一樣的地方。一般股票是「跌得越凶、下次波動越大」(γ 為正),黃金在多頭時反而出現「漲得越凶、下次波動越大」的反向槓桿。論文要講的是這個 regime-dependent 現象,重算之後 現象仍然存在 ,只是強度數字略有差異。
MODIFY、KEEP、RETRACT:三選一
學術界處理這種「重算對不上」的狀況,大致有三種反應。
第一種叫 KEEP ——也就是「裝沒看見、原文不動」。最容易,但風險最大。一旦未來有讀者自己跑、發現對不上、寫信質疑,整篇論文的可信度都會被連累。
第三種叫 RETRACT ——撤稿。最壯烈,也最少用。撤稿通常保留給「結論本身被推翻」「資料造假」「重大方法錯誤」這種等級。K1198 顯然不到。
中間那一種,叫 MODIFY_PAPER 。意思是:論文整體論證仍然站得住,但某幾個具體數字、樣本敘述、或某段解讀需要局部更正。發 errata(勘誤)、改 footnote、在再版裡修正,但 不撤回主結論 。
K1198 的 verdict 就是 (b) MODIFY_PAPER。
實際要做的事情非常具體:
- Table 10 的 footnote 補一行:「公開 API 可取得的 SPY 50 大成分股為 20 檔,原 N=50 結果來自完整資料」,t 統計量更新為 -10.53
- C3 內文那一段把 統計強度 -4.71 改成 統計強度 -3.79,方向跟顯著性敘述不動
- Table 11 的 VT 那一欄加註:VT 數字是 Hybrid VT 規格(12/VIX switching),不是純 GARCH VT
主結論,「ETF 槓桿方向會放大」、「黃金存在反向槓桿」、「VT 在尾端風險上贏 BH」,這三句話一句不改。
我們做這件事,到底有什麼意義
老實說,公開承認「自己寫的論文有 3 個數字對不上」這件事,對個人聲譽不是加分題。
但這件事對平台的意義剛好相反。
我們訂的最高指導原則裡有一條: 研究誠實是長期商業價值的護城河 。短期看,把數字蓋過去最省事;長期看,每一次主動抓自己、主動更正,都是在累積讀者跟同行對這個平台的信任。
更具體一點:
- 我們把每個 K 實驗的腳本、結果 JSON、README 都公開放在 git repo 裡
- 任何讀者拉下來都可以重跑驗證
- 重跑跟論文對不上就是對不上,沒有要遮掩
- 這次抓到 3 個,下次抓到的就會少 3 個,再下次就會更少
而且這套流程不是寫好給人看的口號。K1198 從發現問題到實際算完、列出更正清單,前後就是一個下午的事。系統設計本來就應該把「自我核對」當成基本動作,不是某種需要特別撥時間做的偉大工程。
給讀者的兩個提醒
第一, 看到任何研究數字,先問「這數字怎麼來的、能不能重算」 。學術論文也好、券商報告也好、社群媒體上轉貼的「驚人數據」也好。能附腳本最好,不能附腳本至少要說清楚資料來源跟方法。連方法都講不清楚的數字,看看就好。
第二, 主動承認自己錯了,比被別人抓到再回應,可信度高一個量級 。這對研究者適用,對投資人寫操作紀錄也適用,對任何想經營長期信任的人都適用。沒人會因為你發 errata 就否定你整篇論文,但會因為你裝沒看見而徹底懷疑你其他結論。
K1198 不是漂亮的成功故事。它就是一份「我們發現了 3 個對不上的數字、決定怎麼處理」的工作紀錄。但這種無聊的工作紀錄累積起來,才是研究平台跟單篇爆文真正的差別。
本文基於 K1198(腳本:experiments/k1198/k1198.py,結果:experiments/k1198/k1198_results.json)。資料來源:yfinance;主要期間 2017-01 至 2025-12;C3 黃金延伸至 2005-01 至 2026-01。重算 elapsed 77.85 秒,seed=42。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊