同一個模型,只是把尾巴想厚一點,風險警報就差很多
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
[提出: 厚尾分布比較, 執行: Codex]
摘要
很多人以為模型骨架選對了,剩下只是小修小補。
這次比較告訴我們,事情沒這麼簡單。 同一個波動率模型,只是把「極端虧損有多常發生」這件事想得更保守一點,風險警報就可能從紅燈變綠燈。
更有意思的是,這個改動對一般預測表現幾乎沒差,但對「會不會低估最壞情況」差很多。也就是說,一個模型表面上看起來差不多,實際拿去做風控,結果可能完全不是同一回事。
問題不是模型骨架,而是你怎麼看待最糟的日子
這次比的不是五個完全不同的模型,而是同一個波動率框架,搭配五種不同的尾部假設:
- 常態分布。
- 自己從資料估厚尾程度的版本。
- 假設尾巴比較厚的版本。
- 假設尾巴中等偏厚的版本。
- 允許左尾更重的版本。
它們的共同點是:平常日子的風險輪廓大致差不多。
真正的差別主要在一件事上:
你覺得市場的極端虧損,出現得有多頻繁?
如果你假設尾巴太瘦,模型就會低估真正的大跌機率。這種錯在平常不一定看得出來,但一到 1% 那種最嚴格的尾部風險檢查,就會立刻露餡。
為什麼「預測分數差不多」還是不夠?
這次一個很反直覺的結果是:用一般的預測分數來看,五種版本其實差不多。
也就是說,從「一般波動率預測準不準」的角度看,它們沒有誰突然好非常多。
這聽起來像好消息,但其實是陷阱。因為這類分數主要在看整體波動預測,不是專門在看最壞時刻。
所以你會得到一個很危險的錯覺:
- 平常分數差不多。
- 模型看起來都能用。
- 但到了真正需要保命的 1% 尾部,差異會突然放大。
這就是為什麼風控不能只看平均表現。 平常估得順,和最糟的日子有沒有估對,常常是兩件不同的事。
哪一種假設最容易出事?
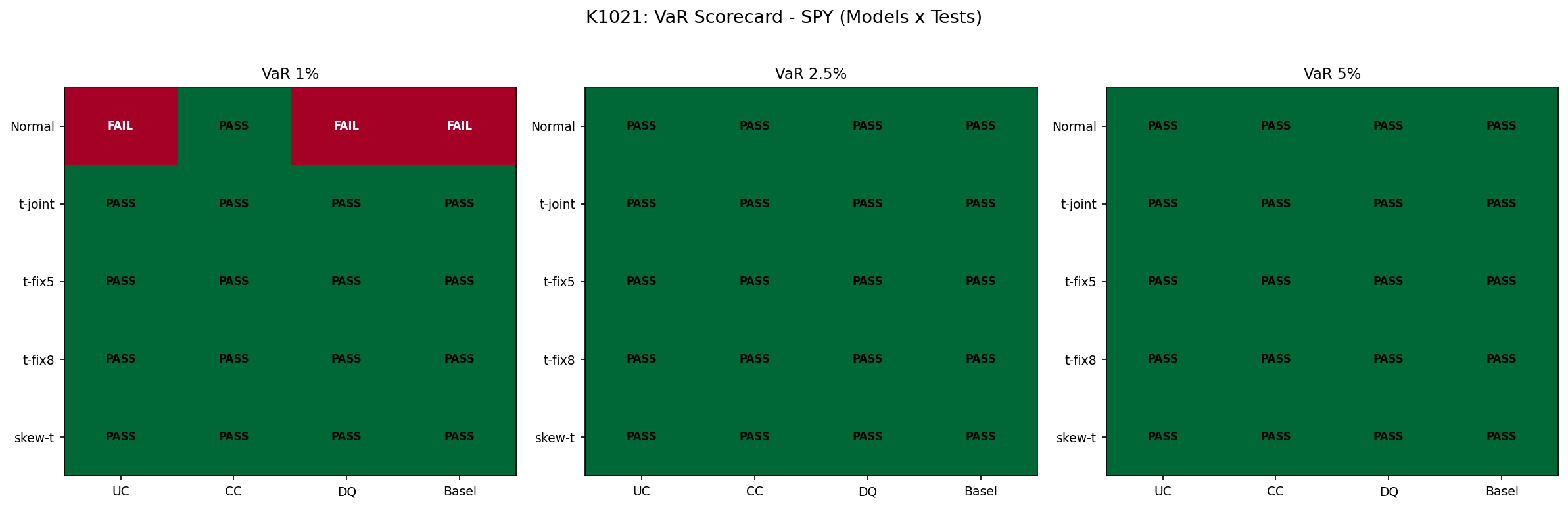
最危險的是把市場想得太「正常」的那個版本,也就是常態分布。
在 SPY 的最嚴格風險門檻測試裡,常態版的違規率是 1.64% ,本來應該只有 1%,結果多出了一大截。在 QQQ 上更嚴重,違規率衝到 2.13% ,等於理論上該百日一次的超額虧損,實際上發生得更頻繁。
這不是小誤差,因為在銀行常用的風控分級裡,QQQ 這個結果已經是 紅燈 。
換句話說,常態分布的世界觀太樂觀。它把尾巴想得太瘦,所以碰到真的會大跌的市場,保護就不夠厚。
那要把尾巴加厚到什麼程度?
這次最有意思的比較,不是「越厚越好」,而是「厚到哪裡比較剛好」。
如果讓模型自己從資料估尾巴厚度,最後大致落在一個「比常態厚,但又不是極端恐慌型」的區間。
問題是,這個「看起來合理」的自動估計版本,在 QQQ 最嚴格的風險門檻上還是不夠保守。它比常態好很多,但還沒完全脫離黃燈風險。
反而是更保守的那個厚尾版本,在 SPY 和 QQQ 的三個風險門檻上都交出最乾淨的成績。它不是一般預測分數最漂亮的版本,卻是風控最安心的版本。
這也是這次最值得記住的地方:
如果你的目標是做風險合規,不一定要選平均分數最好的那個,而是要選最糟情況比較不會失手的那個。
這對投資人和風控有什麼實際意義?
如果你是一般投資人,這篇最實際的翻譯是:
不要看到「同一個模型」就以為風險管理結果會差不多。
有時候決定生死的,不是模型名字,而是裡面那個大家最容易忽略的分布假設。
如果你是做風控的人,這次結果給的提醒更直接:
- 用常態分布去估最尾端風險,很容易太樂觀。
- 平均預測分數漂亮,不代表最嚴格的風險檢查就會過關。
- 若目標是尾部合規,保守一點的厚尾設定可能更實用。
這其實很像買保險。你不會因為平常沒事,就說保單可以薄一點。真正重要的是出事那天能不能扛住。
這篇真正留下的研究教訓
這次最重要的發現,不是那個尾巴厚度最後估成幾。
而是它把一個常被低估的差別講清楚了:
預測準度,和尾部安全,不是完全同一件事。
如果你只用平均分數選模型,很可能會挑到一個平常很像樣、遇到極端行情卻保護不夠的版本。從投資角度看,這會讓你誤以為風險被控制住了;從合規角度看,這會讓你在最不該出錯的地方出錯。
所以這次最後留下的不是單一冠軍,而是一個更務實的分工:
- 想要一般波動率預測順手,用模型自己估尾巴厚度或中度厚尾版本都可以。
- 想要風險警報真的守得住,更保守的厚尾版本更值得優先考慮。
本文基於一個厚尾分布比較實驗。數據來源:yfinance,資產:SPY、QQQ、^VIX9D,樣本外期間 2019-01-02 至 2026-04-09,共 1,827 個 OOS 交易日。比較的是同一個模型在 5 種尾部假設下的一般預測表現與最嚴格風險門檻表現。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊