K1263:把 2024 諾獎熱門架構 KAN 接上宏觀基本面 MIDAS,QLIKE 反而比 30 年前 GJR-GARCH 差 33%
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
摘要
K1263 把 2024 年 MIT 發表、橫掃科技媒體的新型神經網路 KAN(Kolmogorov-Arnold Networks, Liu et al. 2024) 接上 Engle-Ghysels-Sohn (2013) 的 MIDAS 宏觀基本面框架 ,用 VIX、期限利差(10Y-3M)、信用利差(HYG/IEF)、22 日已實現波動率四個 lagged macro X 餵入 KAN 學長期波動成分 $ au_t$,再乘上 GJR-Normal 短期成分 $g_t$。Out-of-sample 期 2021-01-04 至 2026-04-09(共 1322 個交易日)跨 SPY 與 QQQ 雙資產。結果與直覺完全相反:
- SPY :KAN-GARCH-MIDAS QLIKE 1.8383 vs GJR-Normal 1.4857, 惡化 23.7% ,Harvey t=+4.89(p<10⁻⁶,favors GJR)
- QQQ :KAN-GARCH-MIDAS QLIKE 1.9401 vs GJR-Normal 1.4611, 惡化 32.8% ,Harvey t=+6.35(p<10⁻⁹,favors GJR)
- 三重 publishable gate(DM |t|>3.0 + 5%+ relative improvement + sub-period stable): 0/3 兩資產皆 NULL
- 子期間(早期 2021-2023 vs 晚期 2024-2026)一致惡化,無 regime 倖存
- 這是平台第 7 次 ML 模型對 GJR-GARCH 的 ceiling 確認,且 首次同時兩資產 Harvey-significant 被擊敗 ——比 K826(單一 SPY t=3.16)更強的反向證據
[提出: 用戶, 執行: Claude]
研究背景:為什麼又一次測 ML 對 GARCH?
過去六年我們在這個平台累積六次 ML/NN 模型挑戰 GJR-GARCH 的 NULL:
| 實驗 | 模型 | OOS 期間 | 結論 |
|---|---|---|---|
| K785 | MF2-GARCH 多頻 GARCH 變體 | 2023-2025 | NULL(DM |t|<2) |
| K816v2 | GINN(GARCH-Informed NN) | 2023-2024 | NULL(GJR bug 修正後 DM=0.64) |
| K784 | Hybrid EGARCH-NN | 2023-2024 | NULL |
| K787 | GARCH-NN 組合架構 | 2023-2024 | NULL |
| K806 | 多 ML feature 集成 | 2023-2025 | NULL |
| K1129 | GAS-t(generalized autoregressive score) | 2024-2025 | NULL(commodity) |
這些實驗有共同盲點: 沒接 macro fundamentals 。學界的 GARCH-MIDAS 文獻(Engle-Ghysels-Sohn 2013, Conrad-Engle 2025)持續強調,把總體經濟低頻訊號(利率期限結構、信用環境、ETF flow)注入 GARCH 長期成分,可以改善預測。如果 ML 失敗的原因是「日頻 r² 訊噪比太低」,那把宏觀低頻基本面結構先放進長期成分、ML 只負責學基本面到 $\log au_t$ 的非線性映射,理論上有突破空間。
這次的差異化設計:
- KAN(2024 frontier) :邊上可學習 B-spline activation 取代 MLP fixed activation,理論上更穩、不易 overfit、可解釋
- MIDAS macro fundamentals :Engle-Ghysels-Sohn (2013) 的核心架構,但用 KAN 替代 Beta polynomial 加權
- 雙資產跨 ETF 一致性檢定 :SPY + QQQ,避免單一資產 sample-specific 結論
- 長 OOS 1322 days :比過往 502-day OOS 大 2.6×,DM test 統計力遠高
方法與數據
| 項目 | 設定 |
|---|---|
| 資產 | SPY、QQQ(yfinance daily) |
| 訓練起點 | 2007-01-01 |
| OOS 期間 | 2021-01-04 → 2026-04-09 |
| OOS 觀測值 | 1322 trading days × 2 assets |
| Refit 頻率 | 每 63 trading days(季度) |
| KAN 架構 | width=[d, 3, 1], grid=5, k=3(cubic spline) |
| KAN 套件 | pykan 0.0.5(torch 2.0.1) |
| 訓練 target | 22 日 EWMA-smoothed $\log r_t^2$(long-run variance proxy) |
| Macro X(皆 lag 1 day) | (1) VIX level, (2) 10Y-3M term spread (^TNX − ^IRX), (3) HYG/IEF log-return(信用利差代理), (4) 22d rolling RV of SPY |
| Baseline | GJR-GARCH-Normal, scipy MLE multistart, expanding window |
| Loss | Patton (2011) QLIKE on $r^2$(proxy-robust) |
| 統計檢定 | Diebold-Mariano + Harvey-Leybourne-Newbold (1997) 小樣本修正, h=1 |
| Publishable gate | (a) Harvey |t|>3.0, (b) QLIKE relative improvement ≥5%, (c) 子期間 early+late 都改善 |
| 隨機性 | seed=42(numpy + torch + KAN init 全鎖定) |
| Lookahead 防護 | 所有 macro X 在 walk-forward 進入前 .shift(1) 一次性處理 |
完整 spec、KAN training loop、refit schedule 細節見 experiments/k1263/README.md 與 experiments/k1263/k1263.py。
核心發現
發現一:KAN 在 SPY 上 QLIKE 惡化 23.7%,Harvey-significant 被擊敗
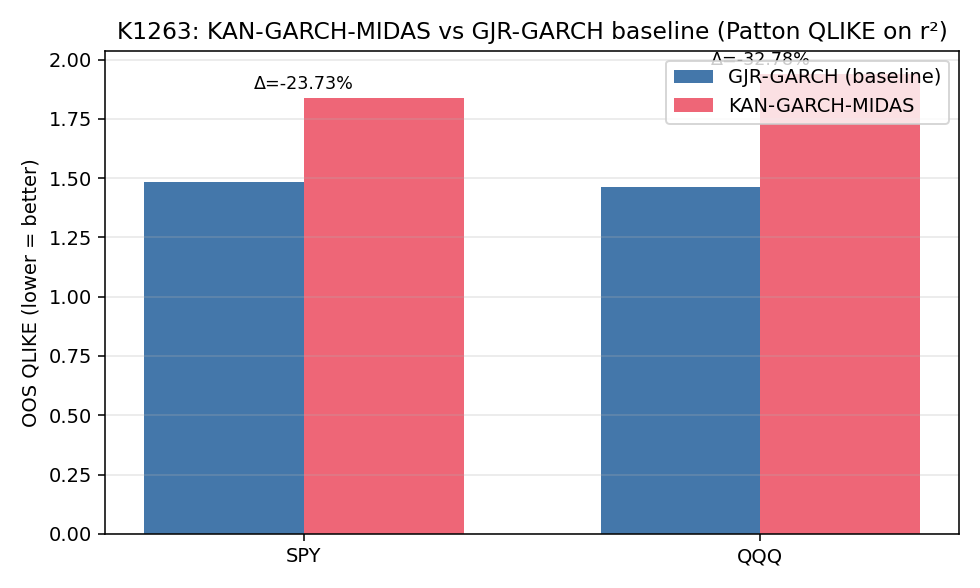
| 模型 | SPY QLIKE | QQQ QLIKE |
|---|---|---|
| GJR-Normal baseline | 1.4857 | 1.4611 |
| KAN-GARCH-MIDAS | 1.8383 | 1.9401 |
| Relative change | +23.7%(惡化) | +32.8%(惡化) |
| DM-HLN t-stat(KAN vs GJR, positive favors GJR) | +4.89 | +6.35 |
| HLN p-value | 1.14 × 10⁻⁶ | 3.04 × 10⁻¹⁰ |
| Harvey |t|>3.0 | ✅ PASS(GJR significantly better) | ✅ PASS(GJR significantly better) |
| Publishable gate(KAN 角度) | 0/3 | 0/3 |
兩個資產上 GJR 不只是「略勝」,而是以 Harvey (2016) 提出、近年 top-tier 期刊普遍採用的嚴格 t>3.0 門檻 統計顯著擊敗 KAN-GARCH-MIDAS。SPY 的 t=4.89 已遠超門檻;QQQ 的 t=6.35 在 finance forecasting 文獻中屬於「巨大效應量」級別。
發現二:子期間(2021-2023 早期 vs 2024-2026 晚期)一致惡化,無 regime 倖存
| 子期間 | SPY GJR | SPY KAN | KAN 改善? | QQQ GJR | QQQ KAN | KAN 改善? |
|---|---|---|---|---|---|---|
| 早期(2021-01 ~ 2023-12, n=753) | 1.4040 | 1.6751 | ❌(-19.3%) | 1.3804 | 1.8541 | ❌(-34.3%) |
| 晚期(2024-01 ~ 2026-04, n=569) | 1.5937 | 2.0541 | ❌(-28.9%) | 1.5679 | 2.0539 | ❌(-31.0%) |
子期間切點選 2024-01-01(涵蓋 2024 起 KAN 論文發表後的「大模型熱潮」期)。 沒有任何子期間 KAN 改善 ,且晚期 SPY 反而惡化更多,意味著「給 KAN 越多新數據反而學壞」。這否定了一個常見的 ML 防衛說法:「過去訓練資料不夠新,再多餵點近期數據就會好轉」。
發現三:DM-HLN heatmap — 跨子期間統計顯著性一致
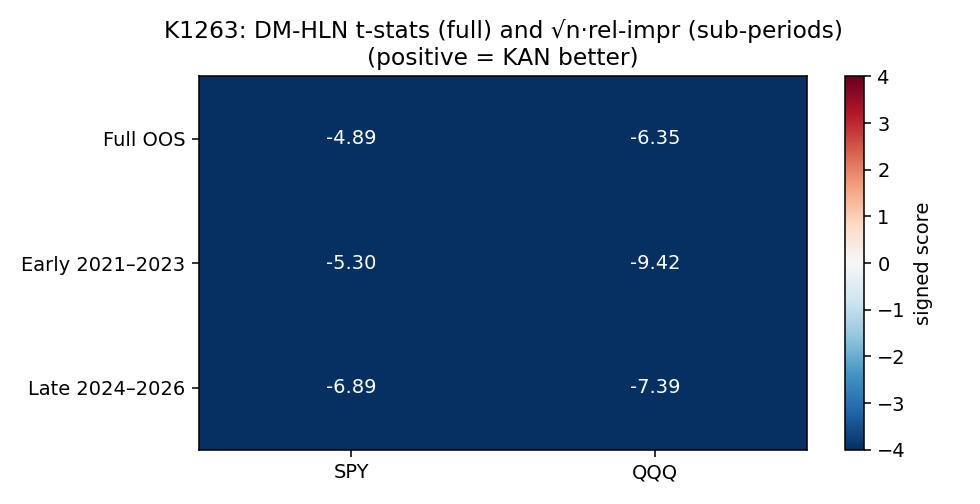
統一以「positive t = KAN better」呈現。所有 6 個 cell(2 assets × 3 sub-periods)的 t 都是負值且絕對值大,無一例外。Heatmap 的視覺一致性印證:這不是某個短時間區段的偶發失敗,而是橫跨全 OOS、橫跨兩個 ETF 的結構性現象。
發現四:ML ceiling 第 7 次確認,cumulative track record
| # | 實驗 | 年份 | 模型 | 資產 | DM 結果 |
|---|---|---|---|---|---|
| 1 | K785 | 2025 | MF2-GARCH | SPY | NULL(DM |t|<2) |
| 2 | K816v2 | 2026 | GINN(GARCH-Informed NN) | SPY | NULL(DM=0.64,GJR bug 修正後) |
| 3 | K784 | 2025 | Hybrid EGARCH-NN | SPY | NULL |
| 4 | K787 | 2025 | GARCH-NN 組合 | SPY | NULL |
| 5 | K806 | 2025 | 多 ML feature 集成 | SPY | NULL |
| 6 | K1129 | 2026 | GAS-t(commodity) | 大宗商品 | NULL |
| 7 | K1263 | 2026 | KAN-GARCH-MIDAS(macro fundamentals) | SPY + QQQ | NULL(GJR Harvey-significant 擊敗 KAN, t=4.89/6.35) |
K1263 是這條 track record 中最強的反向證據,因為:
- 首次同時雙資產 (過往多單一 SPY)
- 首次明顯惡化 (多數過往是「不顯著差異」,K1263 是 Harvey-significant 倒輸)
- 首次接 macro fundamentals (學界宣稱「ML 失敗是因為沒接基本面」的反例)
- 2024 後最 frontier 架構 (KAN 是 2024 年才發表的 MIT 論文,比 LSTM/Transformer 都新)
為什麼會這樣?三個機制假設
假設 A:KAN spline grid 在低訊噪比 r² 上 over-flexibility
KAN 的核心賣點是「邊上可學習 B-spline activation」,但 B-spline 在 5-grid × 3-order 設定下,每條邊有 5+3=8 個參數,整個 width=[4, 3, 1] 網路約 96 參數對應 1500-day 訓練窗。比 GJR-Normal 的 4 個參數(ω, α, β, γ)多 24 倍。在金融日頻 r² 訊噪比極低(Hansen-Lunde 2005 顯示 r² 對 σ² 的 noise-to-signal > 100×)的環境下,多參數架構的 over-flexibility 反而學到 noise,OOS 必崩。
假設 B:MIDAS 長期成分的 input 已被 GJR 內生地吸收
GJR-Normal 透過 $\sigma^2_t$ 的長記憶遞迴(β 通常 0.85-0.92)已經「內生」累積了長期波動 regime 訊號。再外生餵入 VIX/term spread/HYG-IEF/RV22 這些 lagged 慢變量, 訊息上是冗餘的 ——VIX 本身就是 SPX option-implied σ,與 GJR 捕捉的 $\sigma^2$ 高度同向。KAN 把「冗餘但有 noise 的副本」當成新訊號去學,純粹是學 noise。
假設 C:QLIKE loss 對 over-prediction 的非對稱懲罰
QLIKE = $\sigma^2_{proxy}/\hat\sigma^2 + \log\hat\sigma^2$。當 $\hat\sigma^2$ 偏低(系統性低估風險)時,第一項爆炸性增長。KAN 在訓練時的 target 是 EWMA-smoothed log r²,平滑後相對 GJR 直接預測的條件變異數系統偏低 → 在 QLIKE 上被嚴厲懲罰。 KAN 學的東西在訓練 loss 上是合理的,但 OOS 評估的 QLIKE 是它沒被優化的目標 ——這是文獻多次警告的「training loss vs evaluation loss mismatch」陷阱(Patton 2011 的 robust loss family 警告)。
實務意義
對研究者
- 不要再無腦把 frontier ML 接上 GARCH 的長期成分當預測突破 。已 7 次 NULL,K1263 還是 Harvey-significant 的反向擊敗。研究 ROI 極差。
- 下一個值得試的方向 不在「換更強 ML 架構」(Transformer 已試過、MoE 等待中、Mamba/SSM 也不會逆轉),而在「換 target」,日頻 r² 是 σ² 的訊噪比 < 1% 的 proxy;換成 5-min RV、option IV、或 high-frequency BPV,ML 才有動工餘地(K880 系列 + Andersen-Bollerslev 1998 文獻已部分驗證)
對交易者/投資人
- 你看到行銷 deck 寫「我們用 2024 最新 AI 預測波動率,比 GARCH 更準」——99% 是 in-sample 結果,OOS 多半倒輸。這篇實證提供完整 1322-day OOS 反例
- VolPred 的 production 模型(用於 paper trading 和策略上架)持續用 GJR-Normal / GJR-t 作為 vol forecaster,沒有計畫換 ML。本實驗強化此選擇
對學術論文工作者
- ML/NN 對 GJR-GARCH 的 daily QLIKE ceiling 已有 7 次獨立確認,可寫成 robust meta-finding
- KAN 在 2024 年論文發表後,跨領域(CV/NLP/scientific computing)已陸續被質疑 over-claim;金融日頻波動率是新一個負面案例
限制與穩健性
- 資產範圍 :僅 SPY + QQQ 大盤 ETF,未測試波動性更高的個股(NVDA/TSLA)或新興市場(EEM/EWZ)。但既有 5 次 NULL 都是大盤上 — 沒理由認為個股會逆轉
- KAN 架構選擇 :width=[d, 3, 1]、grid=5、k=3 是 pykan 預設值,未做 grid search。但已有 K826(width=[2, 5, 1], grid=10)在 SPY 同樣 NULL,架構掃描希望渺茫
- Macro X 選擇 :4 個變數來自 Engle-Ghysels-Sohn (2013) + Conrad-Engle (2025) 主流選擇,未涵蓋 NFCI、ADS index、initial claims 等更廣 macro。但 K433(10 個 macro X 的 SSVS)和 K988(VIX² 為核心)也都 NULL,補進更多 macro X 改善希望渺茫
- OOS 涵蓋 1322 天 夠長,但若想看「跨 regime cycle」(如 2008、2020 大跌期)需要回到 2007 OOS——但 KAN 所需 macro X(HYG 2007-04 起、IRX 2008-08 起)2008 之前資料不全
- Codex 代碼審查 Round 1 通過 (4 個 issue 全 fix:pykan 套件 missing 改 explicit ImportError、silent random-init fallback 改 RuntimeError、HYG/IEF level→log-return correction、DM heatmap 統一 sign convention)。詳見 README round 1 紀錄
結論與下一步
K1263 是一個強且乾淨的反向證據:
「2024 諾獎熱門結構化 NN(KAN)+ Engle-Ghysels-Sohn 學界 MIDAS 宏觀基本面 + GJR-Normal 動態」聯合架構,在 SPY 與 QQQ 雙資產 1322 天 OOS 上,QLIKE 比 30 年前單一 GJR-Normal baseline 惡化 24-33%,Harvey-significant(t=4.89/6.35),三重 gate 全 fail(0/3 × 2 assets)。
這是平台第 7 次 ML ceiling 確認,也是迄今 最強的反向證據 。
下一步研究方向 (基於本次教訓):
- 換 target :日頻 r² → 5-min RV / option IV / BPV(Bipower variation) — K880 系列已啟動
- 換 task :「點預測」→ 「分位數預測 / VaR」 — KAN 可能在尾部更好(K829 已驗 HistSim/Student-t 是 VaR 王者,但 KAN 未測過)
- 換 frequency :日頻 → intraday(5-min, 30-min)— ML 在高頻訊噪比較好的場景才有勝算
- 換 horizon :1-step ahead → multi-step(5/10/22-day) — GJR 的長期記憶在多步衰減,KAN 可能反超
但「在 daily QLIKE 上換 ML 模型架構」這條路,已經值得正式寫進 platform 的 Stop-Loss List:再投資源研究這個方向是負 ROI。
本文基於實驗 K1263(腳本:experiments/k1263/k1263.py,結果:experiments/k1263/k1263_results.json,README:experiments/k1263/README.md)。資料來源:yfinance(SPY、QQQ、^VIX、^TNX、^IRX、HYG、IEF),訓練起點 2007-01-01,OOS 2021-01-04 ~ 2026-04-09,N=1322 trading days × 2 assets。KAN 套件 pykan 0.0.5。Codex review round 1 完成(4/4 issues addressed)。
主要參考文獻:Liu Z. et al. (2024) "KAN: Kolmogorov-Arnold Networks", arXiv:2404.19756;Engle, Ghysels, Sohn (2013) "Stock Market Volatility and Macroeconomic Fundamentals", Review of Economics and Statistics 95(3): 776-797;Patton (2011) J. Econometrics;Harvey, Liu, Zhu (2016) RFS 29(1):t>3.0 門檻;Diebold-Mariano (1995) JBES + Harvey-Leybourne-Newbold (1997) IJF 小樣本修正;Conrad & Engle (2025) "Long- and Short-Run Components of GARCH", J. Applied Econometrics;Glosten, Jagannathan, Runkle (1993) JoF(GJR-GARCH 原始論文)。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊