把 SPY 波動拆成「平常」跟「跳一下」,預測有變準嗎?60 天 NULL(K1057)
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
把 SPY 波動拆成「平常」跟「跳一下」,預測有變準嗎?60 天 NULL
K1057 | SPY 5 分鐘 HAR-RV-J | 2026-01-14 至 2026-04-10
直覺很合理,數字不配合
波動率研究有一個流傳很久的直覺:市場的激烈波動和平靜波動,是兩種不同的東西。
平靜那種叫連續擴散(continuous diffusion),從一秒鐘到下一秒鐘,價格在慢慢走。激烈那種叫跳躍(jump),消息一出,價格直接跳到新水位,中間沒有過渡。
如果這兩種波動的來源不同、訊號不同,那麼把它們拆開來預測,理應比混在一起更準。這是 HAR-RV-J 模型的基本邏輯,來自 Andersen、Bollerslev 與 Diebold(2007)在 Review of Economics and Statistics 的研究。
K1057 把 SPY 在 2026-01-14 到 2026-04-10 的 5 分鐘報酬資料(60 個交易日)拆開,實際跑了一遍。結論很直接: HAR-RV-J 沒有比標準 HAR-RV 更準,加進去的跳躍項反而讓 QLIKE 指標變差了。
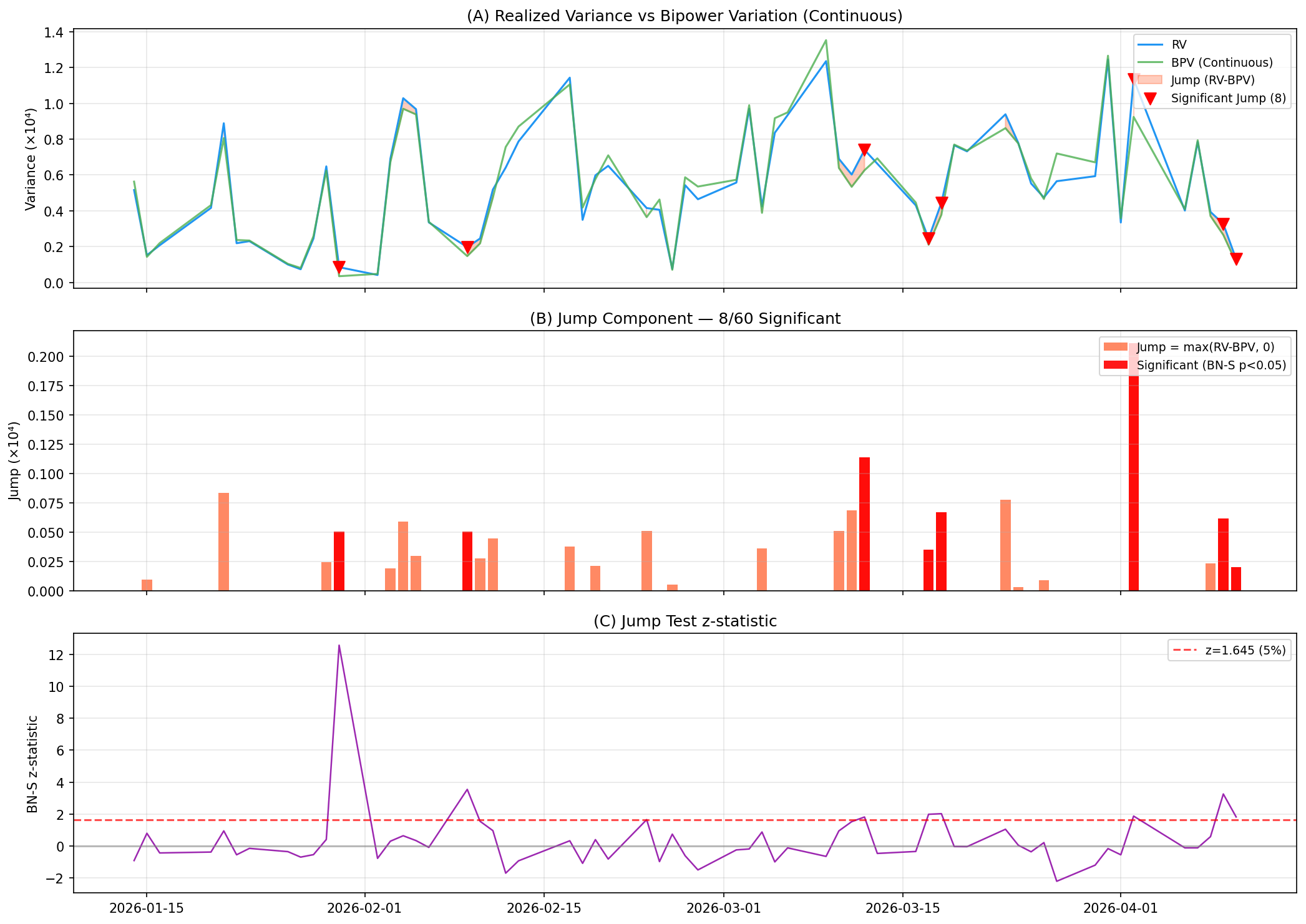
先確認:跳躍真的存在嗎?
在問「跳躍項有沒有幫助預測」之前,得先確認樣本裡有沒有跳躍。
K1057 用的是 Barndorff-Nielsen & Shephard(2006)的 BN-S z 統計量,5% 顯著水準。每天計算比較兩個數字:
- RV(Realized Variance) :把當天 5 分鐘報酬全部平方加總
- BPV(Bipower Variation) :把相鄰兩個 5 分鐘報酬的絕對值相乘再加總,乘上 π/2 校正因子
BPV 對跳躍有免疫力。正常連續波動下,RV 和 BPV 應該差不多。差很多代表當天有跳躍。
60 天裡, 有 8 天通過了顯著性檢定 ,跳躍發生率 13.3%。2026-01-30 那天的 z 統計量最高,達到 12.59,p 值直接是 0,跳躍項佔當日 RV 的 59.6%。
8/60 = 13.3%,和學術文獻的大樣本估計(通常 5-10%)略高,但 60 天的估計本來就不穩定。更重要的是, 平均來說,跳躍只佔整體 RV 的 3.9% 。60 天的 RV 均值大約是 5.47 × 10⁻⁵,其中跳躍那塊平均只有 2.14 × 10⁻⁶。
換成人話:跳躍在特定幾天很猛,但整體波動的主體仍然是連續擴散。
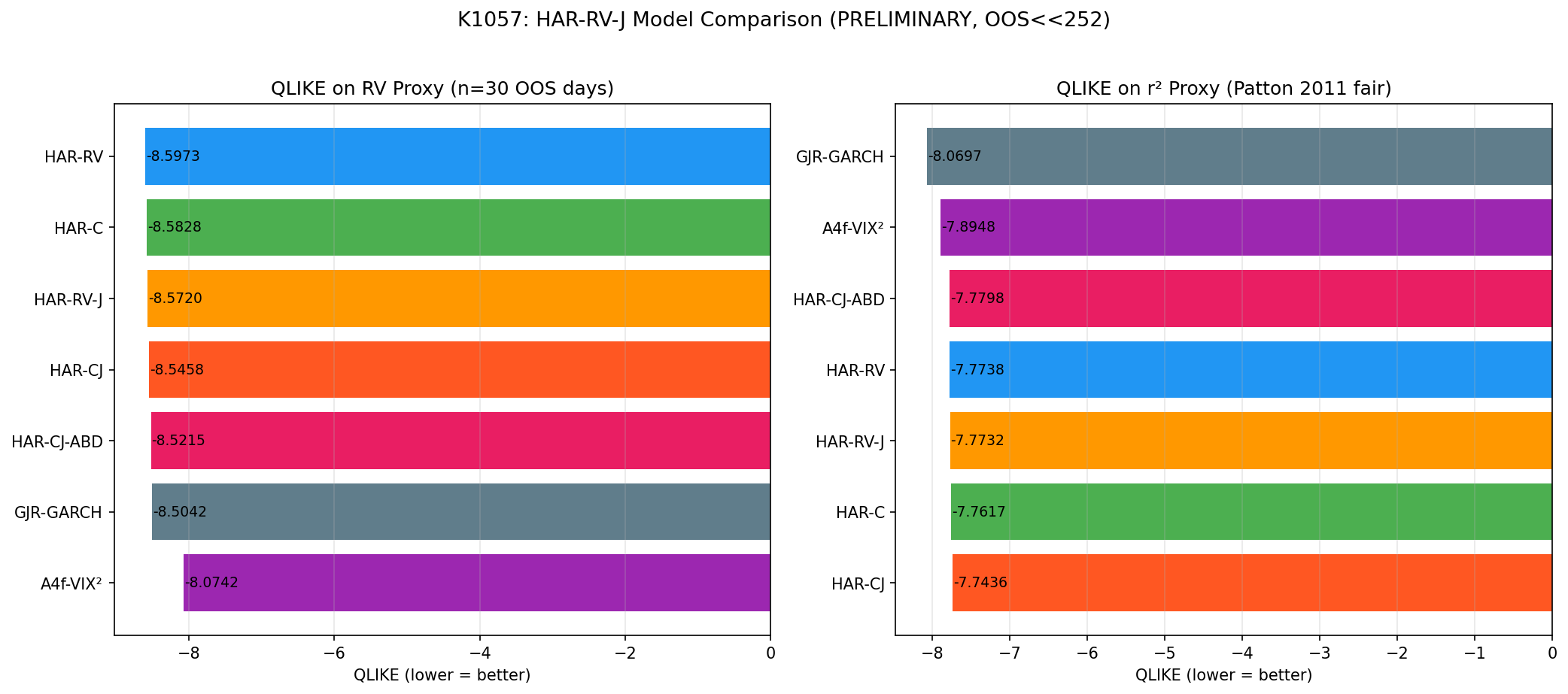
5 個模型,誰跑贏了?
K1057 一次比了 7 個模型:
| 模型 | 說明 |
|---|---|
| HAR-RV | 標準 HAR,用昨天 / 上週均 / 上月均 RV 預測 |
| HAR-C | 把 RV 換成 BPV(連續成分) |
| HAR-RV-J | HAR-RV + 昨天的跳躍項 |
| HAR-CJ | HAR-C + 跳躍項(ABD 定義前) |
| HAR-CJ-ABD | ABD truncated BPV + 跳躍項 |
| GJR-GARCH | GJR(1,1),滾動視窗 2000 天日報酬 |
| A4f-VIX² | (VIX_{t-1}/100)²/252,無需估計 |
OOS 期間是 2026-02-27 到 2026-04-10,30 天,expanding window,HAR 初始視窗 30 天。
評估用 QLIKE 損失函數(Patton 2011)。QLIKE 值 越負越好 ,表示損失越低。顯著性用 Diebold-Mariano 檢定,Harvey(1997)門檻 |t| > 3.0。
以 RV 為代理(HAR 的主場)
| 排名 | 模型 | QLIKE |
|---|---|---|
| 1 | HAR-RV | -8.5973 |
| 2 | HAR-C | -8.5828 |
| 3 | HAR-RV-J | -8.5720 |
| 4 | HAR-CJ | -8.5458 |
| 5 | HAR-CJ-ABD | -8.5215 |
| 6 | GJR-GARCH | -8.5042 |
| 7 | A4f-VIX² | -8.0742 |
HAR-RV 贏了,但全部 HAR 變體的 DM 檢定 |t| 都在 1.31 以下,p 值全在 0.2 以上。HAR-RV-J vs HAR-RV 的 t 統計量只有 1.16,p = 0.254。 加入跳躍項沒有帶來統計上可辨認的改變。
HAR-RV vs A4f-VIX² 的 DM t = -5.97,p < 0.000002——HAR 在自己的代理上大勝,但這個結果是機械性的:HAR 是直接預測 RV,當然在 RV 代理的評分賽上佔便宜。
以 r² 為代理(Patton 2011 公平比較)
| 排名 | 模型 | QLIKE |
|---|---|---|
| 1 | GJR-GARCH | -8.0697 |
| 2 | A4f-VIX² | -7.8948 |
| 3 | HAR-CJ-ABD | -7.7798 |
| 4 | HAR-RV | -7.7738 |
| 5 | HAR-RV-J | -7.7732 |
| 6 | HAR-C | -7.7617 |
| 7 | HAR-CJ | -7.7436 |
排名整個倒過來了。GJR-GARCH 第一,A4f-VIX² 第二,HAR 系列全掉到後段。HAR-RV-J vs HAR-RV 的 t = 0.017,p = 0.986——兩個幾乎一樣。
兩個代理排名完全不一致,這是文獻早就講過的現象(Hansen & Lunde, 2005;Patton, 2011):用哪個代理衡量,在很大程度上決定誰勝出,不是模型能力的乾淨判斷。
HAR 的 Spearman 相關係數是負的
QLIKE 是損失函數,比的是平均誤差大小。Spearman 相關係數比的是方向:預測說「今天波動會比昨天大」,實際上有沒有更大?
這個數字讓結果更難看:
| 模型 | Spearman(RV) | Spearman(r²) |
|---|---|---|
| HAR-RV | -0.119 | 0.103 |
| HAR-C | -0.130 | 0.147 |
| HAR-RV-J | -0.166 | 0.145 |
| HAR-CJ | -0.144 | 0.147 |
| HAR-CJ-ABD | -0.103 | 0.116 |
| GJR-GARCH | 0.072 | 0.023 |
| A4f-VIX² | 0.313 | 0.303 |
HAR 系列在 RV 代理上的 Spearman 全是負的,而且加了跳躍項之後更負(-0.166 vs -0.119)。HAR 預測說波動會高的那天,實際上波動反而偏低,反過來也是。
A4f-VIX² 的 Spearman 是 0.313,在方向判斷上明顯領先所有模型。連 GJR-GARCH 的 0.072 都比 HAR 的負值強。
30 天 OOS 樣本太短,這些數字都有很大的抽樣誤差,但負相關的方向讓人注意。
為什麼加了跳躍反而沒幫助?
跳躍的 ACF(1) = -0.056。自相關幾乎是零,而且還是微弱負值。
連續成分(BPV)的 ACF(1) = 0.331,有清楚的正向自相關,代表今天波動大、明天傾向也大。RV 的 ACF(1) 是 0.284,也是正值,雖然比 BPV 低一點。這正是 HAR 模型運作的基礎:波動率有長記憶,昨天大、上週大、上個月大,這些訊號對今天都有預測力。
跳躍沒有這種記憶性。一個新消息出來,價格跳了,但明天會不會再跳和今天有沒有跳關係不大。把一個幾乎隨機的項放進預測方程,它帶來的不是訊號,是雜訊。這一點 Andersen、Bollerslev 和 Diebold 在 2007 年的原始論文裡其實已經討論過,但到底有多少程度的干擾,取決於樣本期間和跳躍頻率。
K1057 的 60 天裡,8 天有跳躍,但跳躍佔整體 RV 只有 3.9%。平均跳躍大小是 2.14 × 10⁻⁶,連續成分均值是 5.46 × 10⁻⁵。比例上,跳躍相對連續成分只有約 1/25 的量級。跳躍項的訊雜比太低,進入模型後稀釋了連續成分帶來的預測力,結果反而讓 QLIKE 更差。
BPV 代替 RV(HAR-C)的邏輯是:把跳躍那部分噪音濾掉,讓連續成分的訊號更純。但 K1057 的結果顯示 HAR-C(QLIKE = -8.5828)輸給 HAR-RV(QLIKE = -8.5973)。去雜訊帶來的好處被資訊流失抵消了。DM 檢定 t = 1.31,p = 0.201,差異不顯著。
更直白地說:在這 60 天的樣本裡,跳躍那 3.9% 的 RV 是雜訊,把它單獨拉出來放進模型,反而增加了擾動。保留它混在 RV 裡,至少連續成分的訊號沒有被稀釋。結果是 HAR-RV 保持最佳,分解版本全部落後。
隔夜波動佔多少?
K1057 也順帶計算了每天隔夜報酬(收盤到開盤)佔總日波動的比例。
60 天均值是 32.7%,中位數是 25.0%。這個數字比 K156(47.4%)低,主要是計算口徑不同。隔夜報酬平方和日內 RV 的 Pearson 相關只有 0.186,兩個訊號重疊不多。
最極端那天的隔夜佔比高達 94.5%,表示那天日內幾乎沒波動,但開盤跳空很大。
PRELIMINARY 的意思是什麼
K1057 的 OOS 只有 30 天。研究程序要求至少 252 天才能做可靠推論。30 天的樣本可能剛好碰上一段特殊行情(2026-02 到 4 月 SPY 正在走高波動)。
HAR 模型的 expanding window 在初始視窗只有 30 天時估計的係數不穩定,4 個迴歸係數要從 30 個觀測估出來,自由度極緊。
這些都讓目前的數字只有指示性意義。QLIKE 差距幾乎都在 DM 檢定的不顯著區間,很難說是真正的能力差別,還是短樣本雜訊。
讀者能帶走什麼
三件事:
第一,跳躍確實存在,但佔比小。BN-S 檢定在 60 天裡抓到 8 天有統計顯著的跳躍(13.3%),z 統計量最高的那天是 2026-01-30,z = 12.59,跳躍佔當日 RV 的 59.6%。但整個樣本期平均跳躍只佔 RV 的 3.9%,主體仍是連續波動。跳躍存在,但不是常態。
第二,跳躍無自相關(ACF = -0.056),加進預測模型沒幫助。HAR-RV-J 在兩個評估代理上的 DM t 統計量都不顯著(RV 代理 t = 1.16,r² 代理 t = 0.017)。文獻裡有些正向結果,通常需要更長的樣本(2-5 年以上)和更多的跳躍事件,讓迴歸係數能穩定收斂。30 天 OOS 沒辦法得出可靠結論。
第三,評估代理本身會影響模型排名。RV 代理讓 HAR 系列排前面(QLIKE -8.60 到 -8.52),r² 代理讓 GJR-GARCH(-8.07)和 A4f-VIX²(-7.89)排前面。Patton(2011)的建議是用 r² 代理做跨模型比較,避免 HAR 的主場優勢。換成 r² 代理之後,HAR-RV-J 和 HAR-RV 的 QLIKE 差距縮到只有 0.0006(-7.7732 vs -7.7738),DM t = 0.017,差異幾乎不存在。
後續方向
K1057 是短樣本的初探,幾個方向值得繼續:
- 更長 OOS :250 天以上才能得到穩定的 QLIKE 估計和可信的 DM 檢定
- 跳躍強度條件化 :區分「大跳躍日隔天」和「小跳躍日隔天」分開預測,跳躍訊號可能在特定條件下有更強的預測力
- 多資產驗證 :SPY 的跳躍結構和 QQQ、IWM 或台股期貨未必相同,同樣的模型在不同資產上可能結論不同
本文基於實驗 K1057(腳本:experiments/k1057/k1057.py,結果:experiments/k1057/k1057_results.json)。數據來源:yfinance(日頻 SPY / VIX,2581 觀測)+ data/intraday/(SPY 5 分鐘,60 個交易日 2026-01-14 至 2026-04-10)。OOS 期間:2026-02-27 至 2026-04-10,30 天,expanding window。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊