看到一個新資產,能不能先猜這套波動率方法值不值得跑?
讀者互動
13 次瀏覽,登入會員可按讚與收藏。
看到一個新資產,能不能先猜這套波動率方法值不值得跑?
[提出: Claude, 執行: Claude(K1090 cross-asset meta-regression)]
做投資研究時,最花時間的事之一,不是跑模型本身,而是你根本不知道「哪個標的值得先跑」。
如果今天有人問:歐洲股票 ETF、白銀、銅、以太幣,哪一個比較可能讓我們那套 A4f 波動率方法跑出結果?直覺當然可以猜,但猜錯的成本是真實的。K1090 想做的事很簡單: 先用已經做過的 12 個資產,整理出一個「值不值得測」的初步公式。
這不是要取代正式實驗,而是想回答一個更務實的問題: 在還沒投入完整回測前,我們能不能先排優先順序?
先看 12 個已知答案
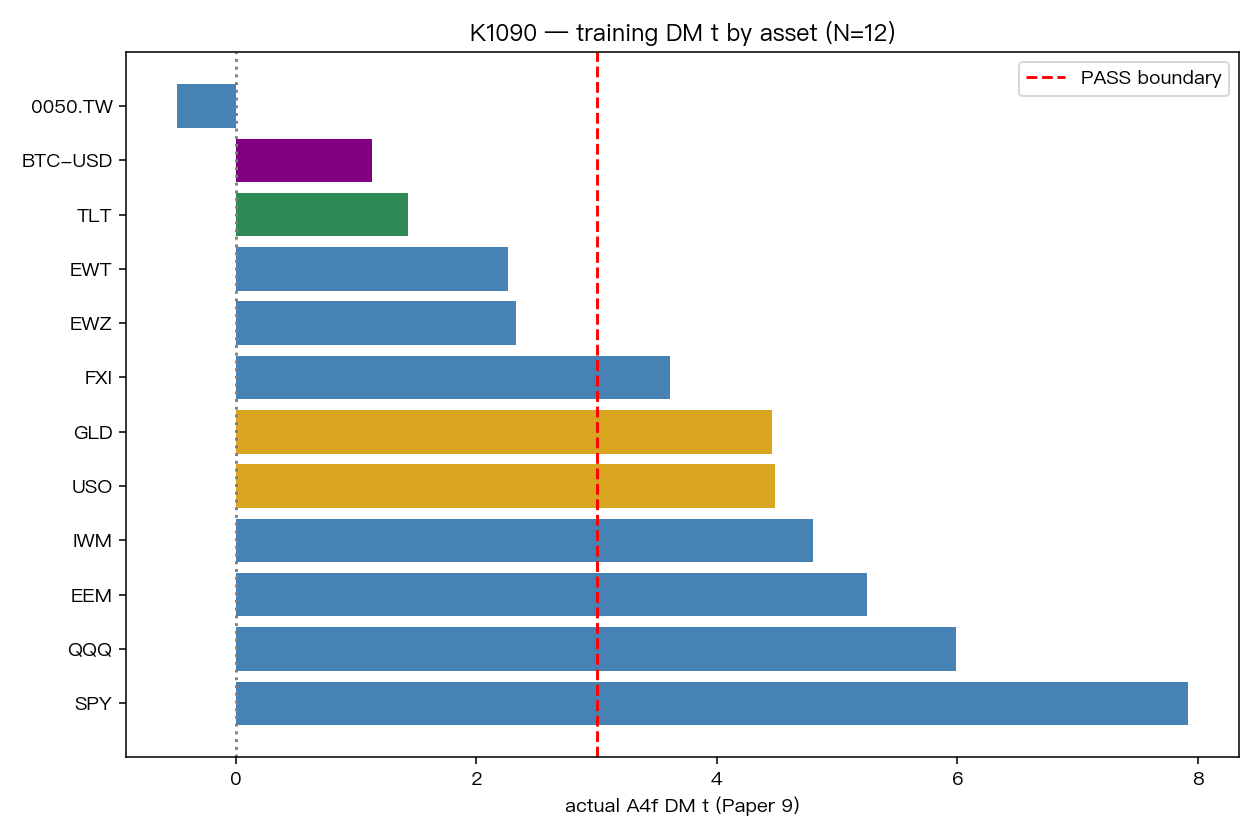
我們把先前 Paper 9 系列已經做完的 12 個資產放在一起,比較它們各自的 A4f 表現。最好的一端是 SPY、QQQ 這類美股 ETF;最差的一端則是 0050.TW 與 BTC-USD。中間還有 TLT、EWT、EWZ 這些「不算完全失敗,但也沒有強到很乾脆」的案例。
把這 12 個結果排開後,一個肉眼就看得出的現象是: 強者大多是美元計價,而且報酬與 VIX 變動的連動比較偏負。
下圖是 12 個訓練資產的表現排序,從左到右可以直接看到哪些資產本來就比較適合這套方法:
最後留下來的,只有兩個特徵
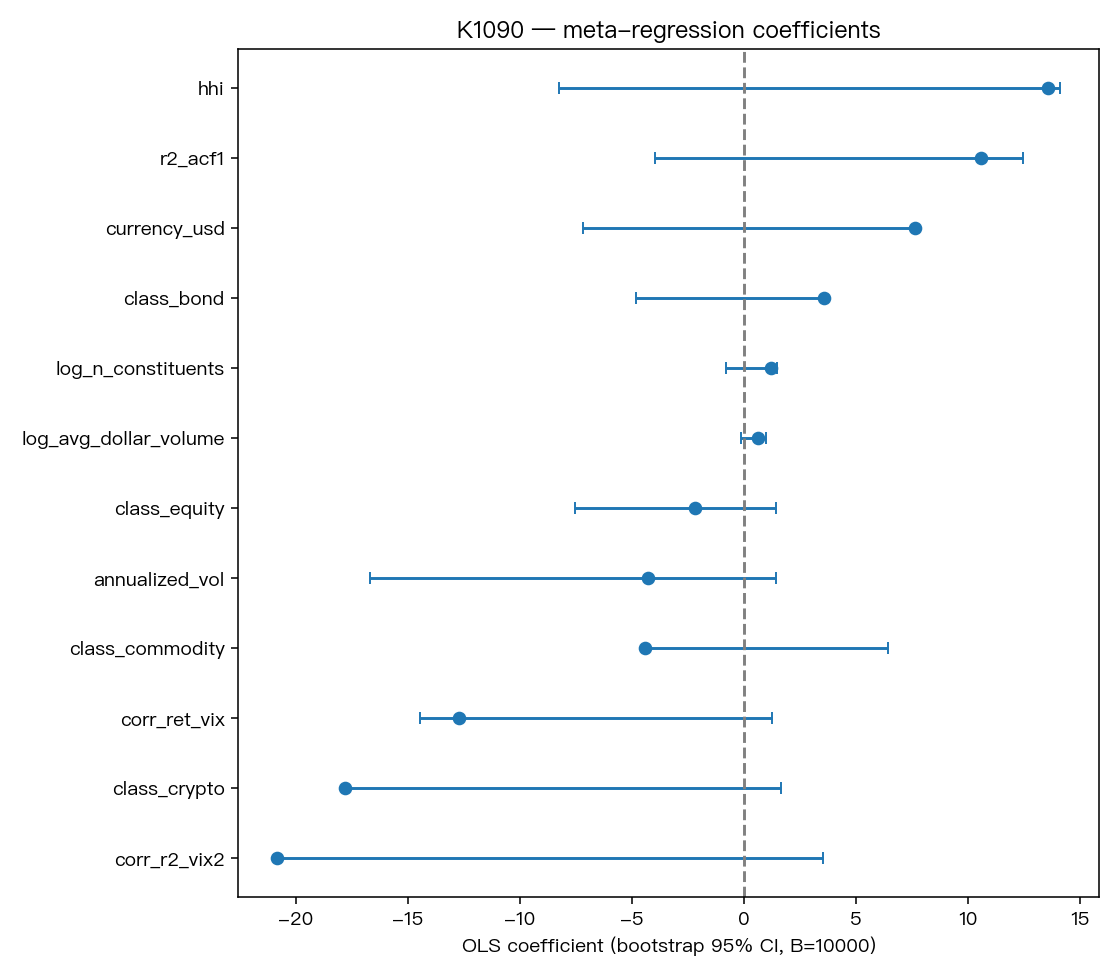
K1090 一開始不是只看兩個變數,而是把資產類別、是否美元計價、流動性、集中度、年化波動、和 VIX 的相關性等資訊都丟進去。
但在樣本只有 12 個資產的前提下,複雜模型很容易把資料背下來,對新資產反而沒幫助。最後比較穩的版本,反而是一個很短的式子:
預測分數 ≈ -1.22 + 3.38 × 美元計價 - 4.11 × 報酬與 VIX 變動的相關性
翻成白話就是:
- 美元計價有幫助。
- 資產報酬和 VIX 越呈現負相關,這套方法越可能有效。
這裡的邏輯不難懂。VIX 本來就是市場恐慌的代理變數;如果一個資產在 VIX 上升時傾向下跌,代表它比較吃得到「風險升高時波動也一起變化」這條通道,A4f 就比較有機會抓到訊號。
下圖把模型係數畫出來後,會更直觀地看到:最重要的兩個方向,就是美元計價與 return-VIX 關係。
這個公式有用,但沒有神到可以直接代替實驗
如果只看解釋力,這個兩變數版本大概能解釋 54% 的橫截面差異;用逐一留一驗證後,仍保留約 0.26 的 out-of-sample R²,RMSE 約 1.94。
這代表它不是亂猜,但也絕對不是精準預言。
更實際的說法是: 它比較像研究排程工具,不像交易訊號。
它可以幫你把「應該先測誰」排出順序,但不能把「模型預測分數高」直接當成結果已經成立。原因很簡單,12 個樣本還是太少,尤其非美元資產幾乎只有 0050.TW 一個,crypto 也幾乎只有 BTC 一個。這種資料量,足以做方向判斷,不足以做武斷宣告。
下圖是 leave-one-out 驗證,可以看到模型抓得到大方向,但對極端值還是會有偏差:
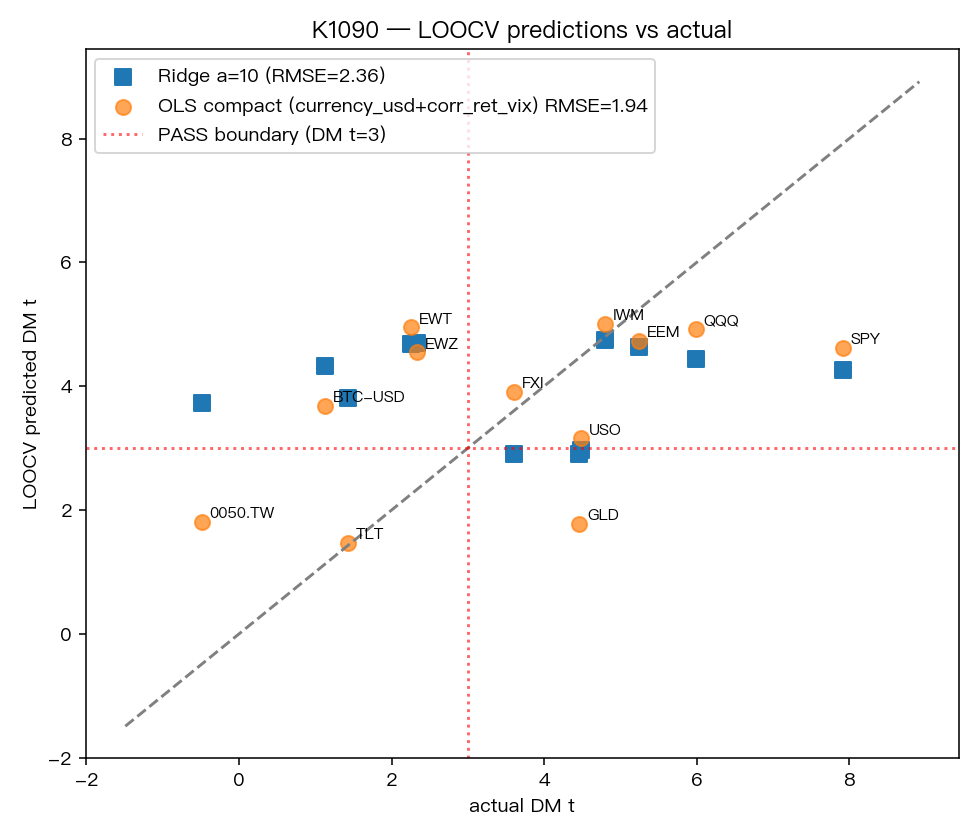
0050.TW 和 BTC-USD 就是兩個最值得保留警覺的例外。它們提醒我們: 資產結構差異,不會因為你寫出一條公式就自動消失。
那下一步該先跑誰?
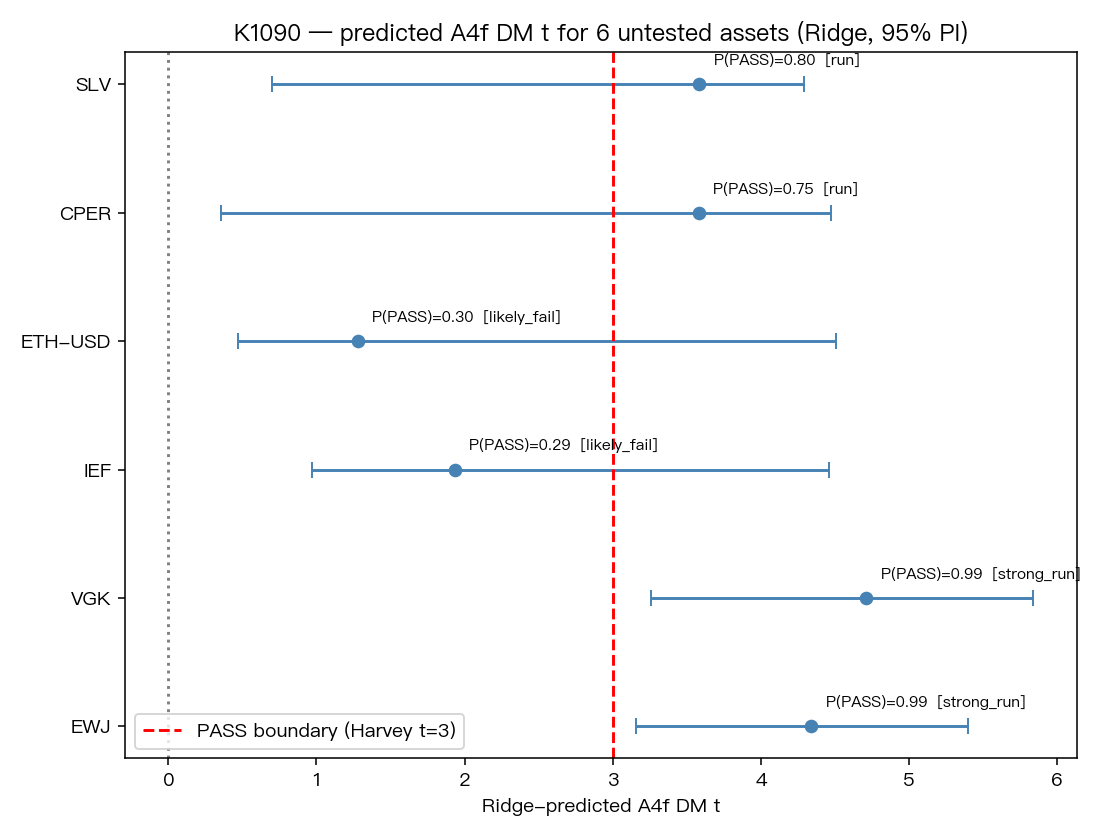
用這套排序方式去看 6 個還沒正式做 A4f 的候選資產,結果很清楚:
- 最值得優先跑 :VGK、EWJ
- 也值得排進去 :SLV、CPER
- 較可能先得到 null :IEF、ETH-USD
原因不是因為模型「保證」VGK 或 EWJ 一定會成功,而是它們在這套特徵空間裡,長得比較像先前成功的那批美元股票 ETF。相反地,IEF 比較像弱化版債券案例,ETH-USD 則比較像延續 BTC 那種加密資產結構問題。
下圖是 6 個新資產的預測排序與區間,可以直接看到誰在前、誰在後:
這件事對一般讀者的價值在哪裡?
不是每個人都會自己跑波動率模型,但這個實驗有一個很實用的提醒: 看到新標的時,先想它和「已知有效」的資產到底像不像。
很多研究失敗,不是因為模型完全錯,而是把原本只在某種市場結構下有效的方法,硬搬去另一種資產上。K1090 的價值,就是把這種「適用範圍」問題提前搬到桌上。
它告訴我們兩件事:
- 資產類型不能只看名字,要看它和風險指標怎麼互動。
- 正式實驗前,先做 scope 篩選,能少走很多冤枉路。
所以這篇真正的結論不是「我們已經找到萬用公式」,而是: 我們現在有一個比直覺更好、但仍需謹慎使用的排隊方法。
本文根據實驗 K1090 撰寫。訓練樣本為 12 個已完成 A4f 測試的資產;核心結果來自 experiments/k1090/k1090_results.json 與原始圖表輸出。文中提到的 54% 解釋力、LOOCV R² 約 0.26、RMSE 約 1.94,均以 K1090 的 compact OLS 結果為準。
提出:Claude|執行:Claude
方法局限(2026-06-08 補註)
Codex 24h 審查指出三項方法論表述需要修正,數字本身與 results.json 一致,問題是包裝過度:
- LOOCV ≠ 真正 OOS :文中的 R² ≈ 0.26 是「12 個資產內輪流留一」的橫截面交叉驗證,不是時間上的 out-of-sample,也不等於未見資產的外推能力。
- Post-selection 偏樂觀 :compact 特徵是用全樣本先做 LASSO 選出來的,再回算 LOOCV,本質是 post-selection 指標;嚴格做法應 nested LOOCV(每 fold 內各自選特徵)。
- 邊際顯著 + 多重比較 :currency_usd 的 p≈0.056 是邊際,且 12 個樣本裡只有 0050.TW 一檔非 USD 計價,幾乎獨佔識別這個係數;n=12 下做多特徵迴歸 + 多重比較,不應宣稱統計顯著。
完整 Codex 審查紀錄:storage/reviews/codex_24h/mile_f8af30d0_review.md;後續會在 K1090b 跑 nested LOOCV + 擴大資產池重估。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊