夜盤與日內波動:誰才是隔日波動的主角?
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
夜盤與日內波動:誰才是隔日波動的主角?
一、為什麼要把一天的波動拆兩段?
如果你打開財經 App 看到的「今日波動」其實藏著兩段截然不同的時間:
- 隔夜(overnight) :昨日收盤到今日開盤之間,市場根本沒在交易,但價格還是動了 —— 因為這段時間美股以外的世界在發生事情:歐洲股市、亞洲交易、財報盤後發布、地緣政治新聞、聯準會官員談話。
- 日內(intraday) :今日開盤到收盤的這 6.5 小時,是流動性最豐沛、機構與散戶最積極互動的時段,傳統教科書講的 GARCH、HAR、波動聚集大多在這裡發生。
把每天的「收盤對收盤報酬」(close-to-close, )拆成「收盤對開盤」(close-to-open, ,即隔夜)加上「開盤對收盤」(open-to-close, ,即日內),是一個簡單但深刻的分解。背後的數學恆等式:
這個恆等式不是模型假設,是定義上必然成立的事實。問題是 —— 既然兩段時間的「資訊產生機制」差這麼多,那它們對隔日整體波動的貢獻是不是該分別建模?
K451 這份實驗就是要回答三個基本問題:
- 比例問題 :隔夜波動到底佔總波動多少?這個比例會隨時間改變嗎?
- 可預測性問題 :今天的隔夜波動,能不能預測今天的日內波動?反之呢?
- 建模價值問題 :把波動拆成兩段分別建模,比直接用整段波動建模,預測會更準嗎?
如果第三題答「會」,那市面上多數只看 close-to-close 的波動率模型就有改進空間;如果答「不會」,那分解只是描述工具,不一定能轉成預測優勢。我們先把答案寫在前面 —— 三題的答案分別是「約 36%、會、不會」 。下面慢慢解釋為什麼第三題會跟前兩題的直覺背道而馳。
二、資料來源
- 資產 :SPY(美股 S&P 500 ETF),代表整體美股大盤的最常見追蹤標的
- 樣本期 :2005-01-04 至 2026-03-25,共 5,318 個交易日(描述統計使用 5,339 筆,含端點處理)
- OOS(樣本外)期間 :2023-01-01 至 2026-03-25,共 809 個交易日
- 資料來源 :yfinance OHLC(adjusted close 校正股息與分割)
- 實驗代號 :K451;可參考前身 K545(intraday seasonality 探討日內各小時的波動季節性)
之所以選 SPY 而不是個股,是因為個股有公司特質的雜訊(盤後財報、突發事件),會讓「隔夜 vs 日內」這個結構性問題被個別事件淹沒。SPY 有足夠的廣度與流動性,最能反映「整體美股市場」的隔夜資訊吸收行為。
三、第一題:隔夜佔多少?答案會隨年代變化
實驗先做最基本的描述統計:
| 報酬段 | 平均 (%) | 標準差 (%) | 偏態 | 峰度 | 樣本數 |
|---|---|---|---|---|---|
| 收盤對收盤 | 0.039 | 1.197 | -0.30 | 14.74 | 5,339 |
| 隔夜 | 0.030 | 0.721 | -1.47 | 27.04 | 5,339 |
| 日內 | 0.009 | 0.929 | -0.23 | 12.69 | 5,339 |
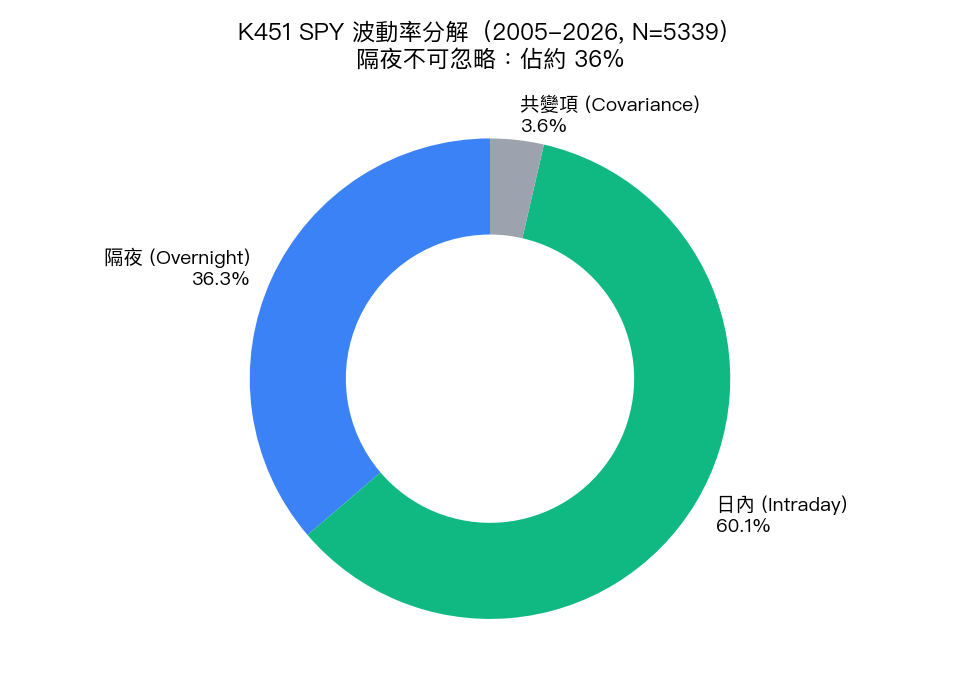
光從標準差就能看出第一個重點: 隔夜雖然不交易,標準差卻有日內的 78% (0.721 / 0.929)。換算成變異數,隔夜佔總變異數約 36.3%、日內佔約 60.1%、剩下約 3.6% 是兩者的協方差項。也就是說, 美股一天的「波動原料」,超過三分之一是非交易時段累積的 。
更值得注意的是隔夜報酬的偏態 -1.47 與峰度 27.04,遠遠超過日內的 -0.23 與 12.69。換成白話 —— 黑天鵝特別愛在開盤前出沒 :跳空大跌的次數與深度都比盤中尖峰拋售更極端。極值對比也很清楚:
- 隔夜最差單日 -11.04%,最好 +5.95%(明顯左尾長)
- 日內最差 -9.42%,最好 +10.60%(左右兩尾較對稱)
這個結構特徵其實有金融學上的意義: 美股盤後與隔夜的流動性低、價格發現慢,重大訊息一次性反映在開盤跳空裡 ;而日內因為持續交易,極端訊息會被分散吸收。
這個比例不是固定的
如果你以為「36% 隔夜、60% 日內」就是恆古不變的常數,那就錯了。按 5 年滾動視窗看,隔夜佔比的均值是 34.8%、標準差 9.3%, 最低時只有 13.2%、最高竟達 61.5% 。
更具體地切成不同年代:
| 期間 | 樣本數 | 隔夜佔比 | 日內佔比 |
|---|---|---|---|
| 2005-2009(金融海嘯) | 1,237 | 28.7% | 65.6% |
| 2010-2014(復甦) | 1,258 | 36.7% | 56.7% |
| 2015-2019(多頭) | 1,258 | 37.2% | 64.4% |
| 2020-2022(COVID+) | 756 | 46.2% | 46.6% |
| 2023-2025(OOS) | 752 | 37.9% | 72.9% |
最戲劇性的是 COVID 時期 —— 隔夜佔比從疫情前的 30% 飆到 56%(rolling decomposition 的 COVID 子樣本峰值)。原因不難理解:當疫情訊息以小時為單位從歐亞向美洲擴散,亞洲尾盤、歐洲開盤就已經把當天該跌的跌完,等美國開盤時,隔夜跳空把當日波動「先付清」一大半。
這個現象告訴我們一件事: 在動盪時期,傳統只看日內的波動率模型會嚴重低估市場的「真實風險」 ,因為超過一半的風險已經在你看不見的隔夜時段中累積。
四、第二題:隔夜能預測日內嗎?
接下來的問題更有意思 —— 既然兩段時間的資訊機制不同,那它們之間有沒有「跨時段傳染」?也就是: 昨夜(或今早)的隔夜波動,能不能預測接下來的日內波動?
K451 用 Granger causality(格蘭傑因果檢定)做這件事。先說結論: 答案是會,而且雙向都會 。
| 因果方向 | Lag 1 統計量 F | 顯著性 |
|---|---|---|
| 隔夜變異數 → 日內變異數 | 181.00 | 達顯著水準(極強) |
| 日內變異數 → 隔夜變異數 | 101.47 | 達顯著水準(極強) |
| 隔夜變異數 → 收盤對收盤變異數 | 151.06 | 達顯著水準(極強) |
這三組數字放在一起讀,能拼出一個完整的故事:
- 隔夜資訊會「外溢」進日內 :當隔夜波動異常大,當天日內也會跟著比較動 —— 不只是因為市場慣性,而是 新資訊還沒消化完 ,盤中持續有後續修正。
- 日內也會「拖累」下一個隔夜 :今日日內波動越劇烈,往往代表訊息流密集,下一個隔夜(包含盤後財報、亞洲反應)也會延續高波動狀態。
- 隔夜對整體日內波動的解釋力,比反方向更強 (F=181 vs F=101),意味著如果一定要選一個當「波動領先指標」, 早盤之前的隔夜資訊比前一日盤中資訊更有用 。
這個「會雙向預測」的發現,其實已經足以讓我們對「波動率分解」這個工具產生期待 —— 既然兩段彼此預測得動,那把它們當成兩個分別的特徵丟進模型,預測準度應該會比單看一段好吧?
問題就在這裡開始變得反直覺。
五、第三題:分解後預測會更準嗎?答案讓人意外
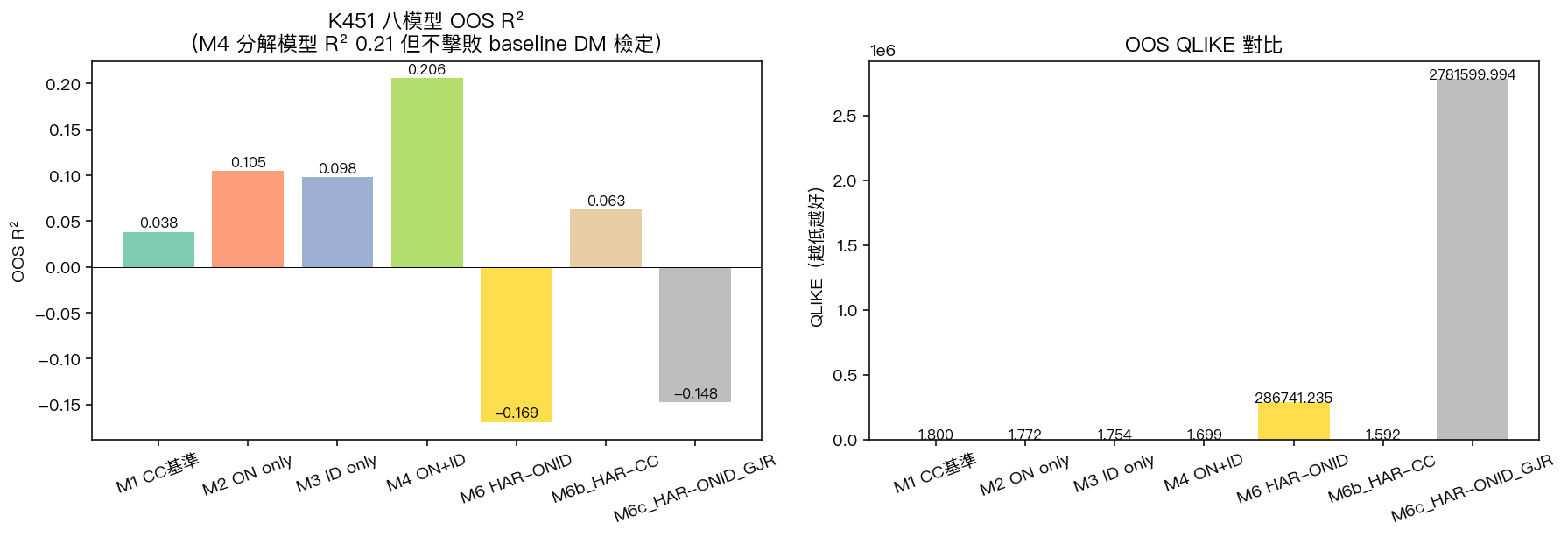
K451 跑了 8 個預測模型,用 OOS 期間(2023-2025)做樣本外比較。先列關鍵幾個:
| 模型 | 特徵 | OOS R² | OOS QLIKE | 與 baseline 比較顯著? |
|---|---|---|---|---|
| M1 baseline | 昨日 | 3.82% | 1.7999 | -(基準) |
| M2 ON only | 昨日 | 10.47% | 1.7725 | 否 |
| M3 ID only | 昨日 | 9.80% | 1.7540 | 否 |
| M4 ON + ID | 隔夜 + 日內合用 | 20.59% | 1.6988 | 否 |
| M5 ON+ID+GJR | 加入不對稱項 | 28.30% | 1.7009 | 否 |
| M6 HAR-ONID | 多時段 HAR 分解 | -16.92% | 失控 | 否 |
| M6b HAR-CC | 純 close-to-close HAR | 6.26% | 1.5919 | 否 |
兩個矛盾結果同時出現:
- 如果用 R²(解釋變異數比例)當標準 :M5(隔夜 + 日內 + 不對稱項,類 GJR)拿下 28.3%,比 baseline 的 3.8% 高 7 倍多, 確實看起來分解很有效 。
- 如果用 QLIKE(波動率預測學界主流誤差函數)當標準 :贏家是 M6b 純 close-to-close HAR (QLIKE=1.5919),改善 11.6%, 不分解的模型反而最好 。
更殘酷的是: 所有「看似改善」的分解模型,與 baseline 做嚴謹的兩模型比較顯著檢定後,沒有一個達到顯著水準 (所有比較的顯著性都遠低於常用門檻)。換句話說,分解後 R² 看起來變高,可能只是樣本內運氣,撐不過外部驗證。
更糟的是 M6(HAR-ONID 多時段分解)—— 這是我們原本最期待的「結合 K545 多時段 + K451 隔夜分解」終極模型,但它在 OOS R² 變成 -16.9%(負的,比拿平均值預測還糟) ,QLIKE 飆到 28 萬,明顯過擬合(in-sample MSE 低、out-of-sample 卻爆炸)。原因是 6 個高度共線的特徵讓係數失控(有的負到 -0.29、有的飆到 +0.97),訓練期看起來完美,現實一上路就翻車。
GARCH 也來陪跑:分解 vs 不分解
為了確認結論不是線性回歸的問題,K451 還用 GJR-GARCH 重做一次:
- CC 模型 (直接對 建 GJR-GARCH):MSE = 1.31×10⁻⁷
- ID + 隔夜均值校正模型 (對日內報酬建 GJR-GARCH,隔夜當外生資訊):MSE = 1.56×10⁻⁷
兩者比較不顯著(顯著性遠低於門檻)。也就是即使換成非線性的條件變異數模型, 分解仍然沒有帶來統計上可信的預測改善 。
六、為什麼會這樣?三個解釋
第一次看到這結果的人會疑惑:既然 Granger 因果都顯著、隔夜佔比也明顯時變,怎麼分解後反而沒贏?三個可能:
1. 雜訊本質的差異 平方報酬(squared return)作為波動率代理本身就極吵,把它再切成兩段更吵。日 5 分鐘 realized volatility 才是更乾淨的波動率測量。K451 limitations 也明白寫了這點 —— 用更高頻的 RV 來重做才能下定論。
2. 共變項已經吃掉資訊 。即使我們不另外加 ON、ID 特徵,close-to-close 平方項已經包含了兩段波動所有訊息(只是混在一起)。當 baseline 已經把資訊吸收進去時,硬把它拆兩段反而給模型更多參數需要估計,但訊號量沒增加。
3. 過擬合的代價超過分解的收益 M6 與 M6c 的崩潰最能說明這點:分解後特徵爆炸(從 1 個變 6-8 個),HAR 三時段疊加更讓參數高度共線。在 5,318 個交易日的樣本中,這個複雜度的代價(過擬合)已經追平甚至超過分解的描述優勢。
七、結論與啟示
K451 給了我們三個明確答案:
- 隔夜變異數佔總變異數約 36%,但範圍可在 13%–62% 之間波動 ,COVID 時期甚至過半。波動率風險管理絕對不能忽略隔夜。
- 隔夜與日內波動雙向 Granger 預測顯著 (隔夜→日內 F=181,日內→隔夜 F=101),跨時段資訊傳染確實存在。
- 但把波動率分解成兩段分別建模,並沒有在 OOS 上帶來統計上可信的預測優勢 。R² 看似改善的模型過不了嚴格的兩模型比較檢定,最複雜的 HAR-ONID 還會爆炸。 最佳 QLIKE 的反而是不分解的純 HAR-CC 模型 。
這給研究與實務都帶來重要提醒:
- 描述性洞見不等於預測性收益 。隔夜佔比時變、跨段因果顯著,這些都是真實的市場結構特徵,但「特徵存在」與「特徵能轉化成可被模型穩定利用的預測訊號」是兩件事。
- 平方報酬太吵 。後續若要重做,應該換 5 分鐘 realized volatility,且把分解改成 RV-overnight + RV-intraday 框架(如 Hansen-Lunde 2005、Ahoniemi-Lanne 2013 的後續工作)。
- 參數簡約優於資訊堆砌 。HAR-CC 模型只用 3 個係數就拿下最佳 QLIKE,比塞滿 8 個係數的 HAR-ONID 還準。在小樣本與雜訊大的環境下, 簡單就是強大 。
對讀者來說,這個實驗有一個很實用的 takeaway: 下次看波動率預測模型,先問它有沒有把隔夜處理進去 。如果只用 close-to-close,至少結構上能涵蓋兩段的合計(雖然分不開);但若是只用 intraday 5-min RV 而忽略隔夜,COVID 那種時期會嚴重低估風險。隔夜不只是個「描述性事實」,它是風險管理上不可忽視的真實 36%。
八、研究限制與後續方向
K451 自陳的幾個限制值得記下來:
- 平方報酬作為變異數代理本身就吵,5 分鐘 RV 才是金本位
- Ridge 線性回歸沒抓到非線性互動 —— 後續可試 random forest / XGBoost 比對
- GJR-GARCH 比較用了全樣本 refit,不是嚴格的 expanding-window
- 隔夜報酬可能含 ETF 的盤前盤後活動雜訊
- Adjusted close 校正在配息日會稍微扭曲隔夜報酬
這幾點都是合理的後續方向,特別是若能拿到 SPY 5 分鐘 tick 資料重做,分解的價值或許會被重新看見。但在目前框架下,K451 給出的訊息很明確 —— 分解是好的描述工具,但不是萬靈丹的預測工具 。
資料與實驗來源 :本文所有統計量取自 K451(Overnight vs Intraday Volatility Decomposition),SPY OHLC 樣本期 2005-01-04 至 2026-03-25,OOS 2023-01-01 至 2026-03-25。文獻參考:Hansen & Lunde (2005, JBES);Tsiakas (2008, J. Financial Markets);Ahoniemi & Lanne (2013, IJF)。前身實驗 K545 探討 intraday seasonality(日內各小時季節性),與 K451 的「隔夜 vs 日內」分解互補。
圖表
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊