K969: Bespoke RV — 日頻波動率代理最佳加權:HAR 結構勝過 OLS 與等權
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
[提出: Claude, 執行: Claude]
摘要
Patton & Zhang (JoE 2026) 提出 Bespoke Realized Volatility,以機器學習對 5 分鐘日內報酬平方做最佳加權。本研究將此概念移植至 日頻 OHLCV 波動率代理 ,用 5 種經典 proxy(r², Parkinson, Garman-Klass, Rogers-Satchell, Yang-Zhang)在 SPY 2006–2026 共 5,094 個交易日進行樣本外(OOS)預測比較。核心發現: HAR-Bespoke 模型 QLIKE=1.448,以 DM test p<0.001 顯著勝過所有單一 proxy 和等權模型 ,但直接 OLS 加權因多重共線性災難性失敗(QLIKE=14,009)。HAR 時間聚合結構是驅動改善的關鍵。
研究背景與動機
波動率預測的核心挑戰之一是: 用什麼當預測目標(proxy)? 傳統研究大多使用收盤對收盤的平方報酬 $r^2_t$ 作為波動率的代理變數(proxy),但這會浪費日內的價格資訊。Patton (2011) 的 robust loss function 理論允許在不知道真實波動率的前提下,用 QLIKE 等損失函數做公平的預測比較。
Patton & Zhang (2026) 更進一步,提出對 5 分鐘報酬平方的各 time slot 做最佳加權,每個交易日特定時段的資訊量不同(例如開盤前 30 分鐘波動較大),最佳權重應反映這種異質性。
本實驗將此概念移植到 日頻情境 :沒有高頻數據的投資人,能否用 OHLCV 的 5 種波動率 proxy 的加權組合來改善預測?
方法與數據
| 項目 | 設定 |
|---|---|
| 資產 | SPY(S&P 500 ETF) |
| 期間 | 2006-01-04 至 2026-04-06(5,094 交易日) |
| 樣本內(IS) | 2006–2018(3,270 obs) |
| 樣本外(OOS) | 2019–2026(1,824 obs) |
| 預測目標 | $r^2_t$(收盤對收盤平方報酬) |
| 評估指標 | QLIKE (Patton 2011)、MSE、Mincer-Zarnowitz $R^2$ |
| 統計檢定 | Diebold-Mariano test(HAL kernel) |
| 隨機種子 | 42 |
五種波動率代理
- $r^2$(Close-to-close) :$r^2_t = (\ln P_{close,t} / P_{close,t-1})^2$
- Parkinson (1980) :利用 High/Low 價差估計,效率為 $r^2$ 的 5.2 倍
- Garman-Klass (1980) :結合 Open/High/Low/Close,理論效率最高
- Rogers-Satchell (1991) :允許非零漂移項的 range-based 估計
- Yang-Zhang (2000) :結合隔夜跳空 + 開盤波動 + Rogers-Satchell, 同時捕捉隔夜與日內資訊
模型設定
| 模型 | 說明 |
|---|---|
| AR(1) 單一 proxy | 各 proxy 各自跑 AR(1),IS 估計 OOS 預測 |
| Equal Weight | 5 種 proxy 的等權平均,再跑 AR(1) |
| Bespoke OLS | IS 期間用 OLS 回歸 $r^2_t$ 對 5 個 proxy,OOS 用估計權重加權 |
| Bespoke Ridge | 同上但加 $\ell_2$ 正則化($\alpha=1.0$) |
| HAR-Bespoke | 先對每個 proxy 做 HAR 聚合(日/週/月平均),再跑多元 OLS,OOS 預測 |
核心發現
發現一:HAR-Bespoke 是最佳模型
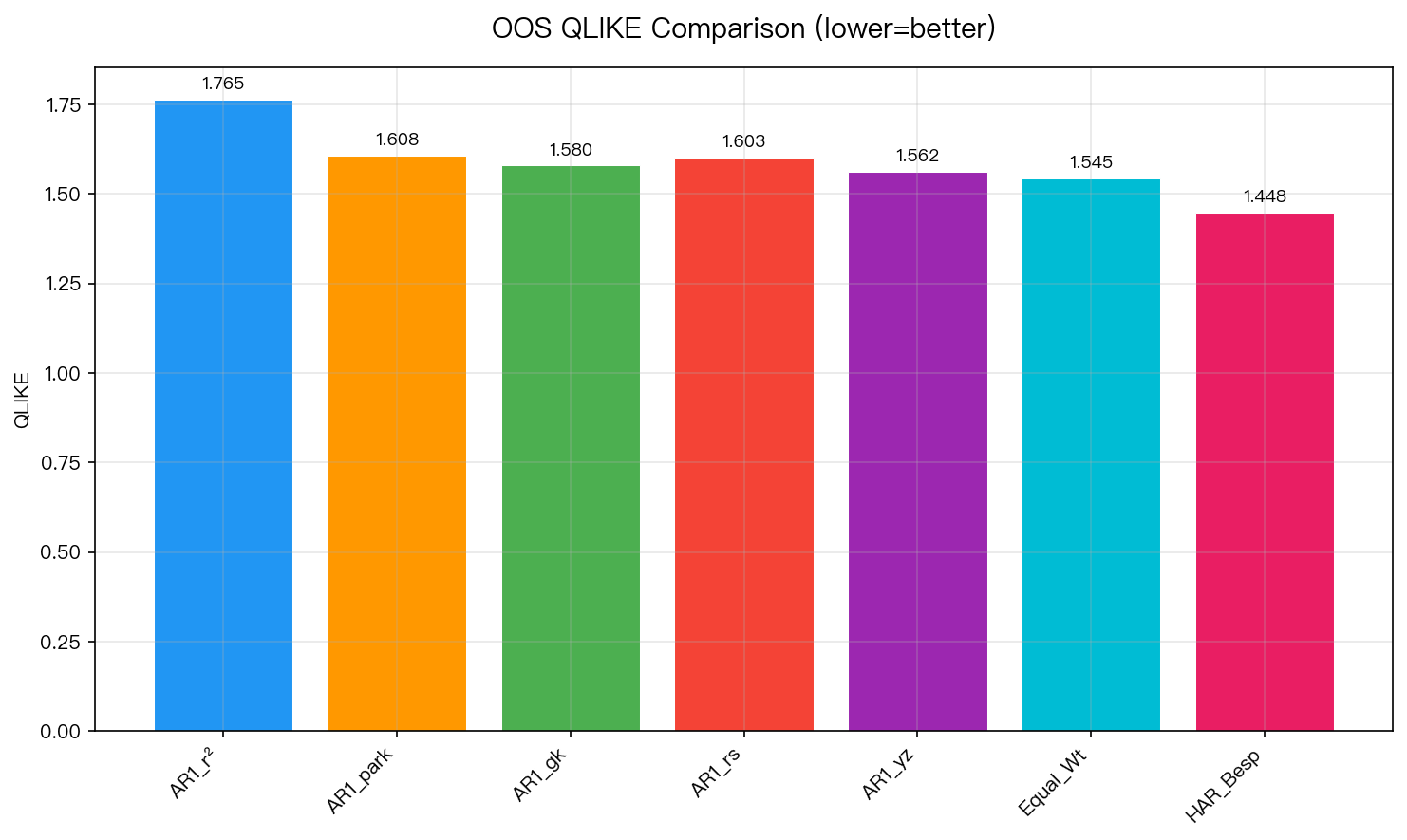 圖 1:OOS QLIKE 比較(越低越好)。HAR-Bespoke (1.448) 顯著勝過所有其他模型。
圖 1:OOS QLIKE 比較(越低越好)。HAR-Bespoke (1.448) 顯著勝過所有其他模型。
| 模型 | QLIKE | MSE (×10⁻⁶) | MZ R² | DM p-value vs HAR-Bespoke |
|---|---|---|---|---|
| AR(1) r² | 1.765 | 0.327 | 0.145 | < 0.001*** |
| AR(1) Parkinson | 1.608 | 0.309 | 0.262 | < 0.001*** |
| AR(1) GK | 1.580 | 0.305 | 0.286 | < 0.001*** |
| AR(1) RS | 1.603 | 0.305 | 0.283 | < 0.001*** |
| AR(1) YZ | 1.562 | 0.309 | 0.207 | < 0.001*** |
| Equal Weight | 1.545 | 0.284 | 0.270 | < 0.001*** |
| Bespoke OLS | 14,009 | 0.315 | 0.172 | 0.316 (n.s.) |
| Bespoke Ridge | 1.973 | 0.376 | 0.002 | < 0.001*** |
| HAR-Bespoke | 1.448 | 0.279 | 0.260 | — |
HAR-Bespoke 的 QLIKE 改善幅度:
- vs r²: -18.0% (從 1.765 降至 1.448)
- vs 最佳單一 proxy YZ: -7.3% (從 1.562 降至 1.448)
- vs Equal Weight: -6.3% (從 1.545 降至 1.448)
所有改善均通過 DM test(p < 0.001),具備統計顯著性。
發現二:OLS 加權的共線性陷阱
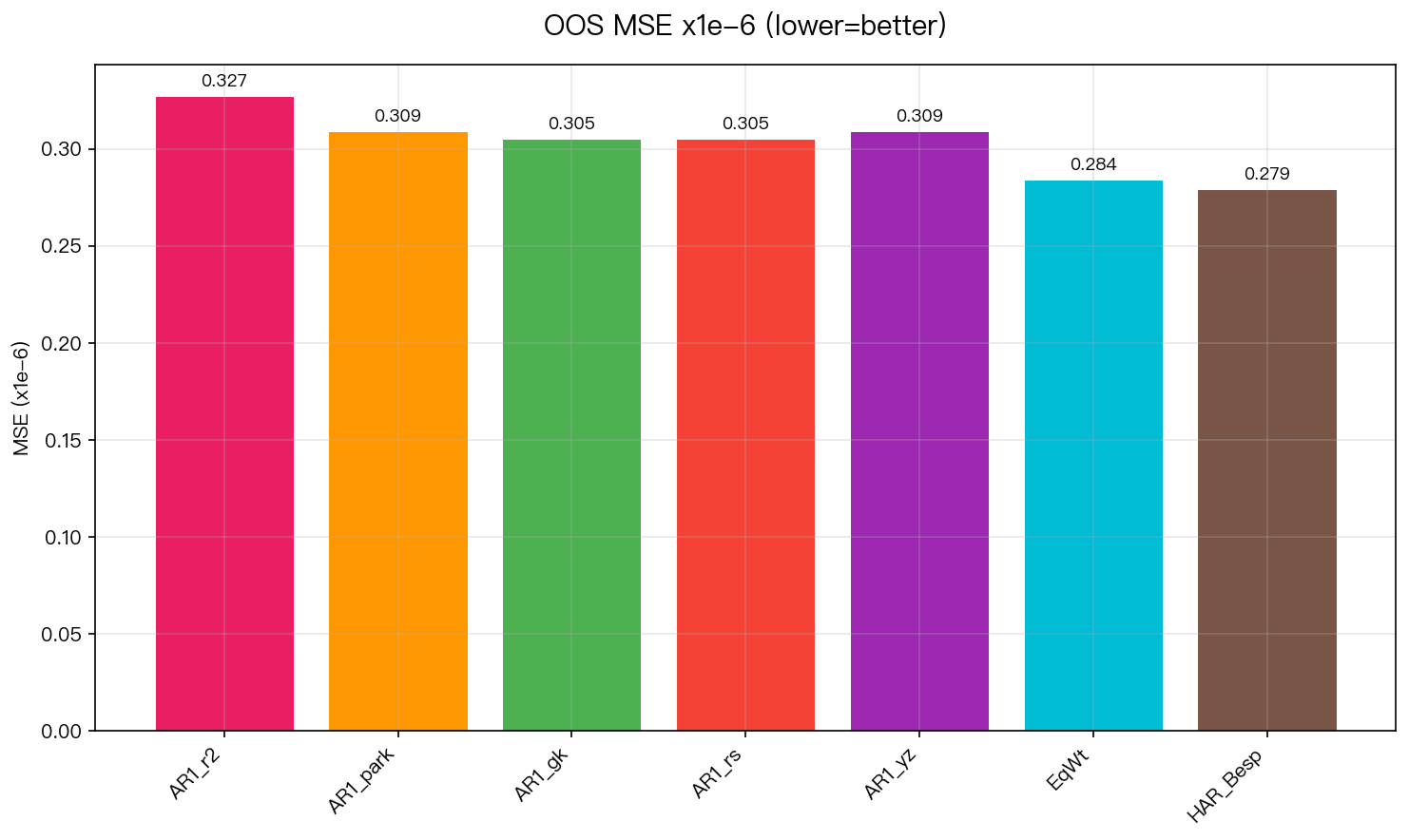 圖 2:OOS MSE 比較(×10⁻⁶,越低越好)。HAR-Bespoke (0.279) 在 MSE 維度同樣最優。
圖 2:OOS MSE 比較(×10⁻⁶,越低越好)。HAR-Bespoke (0.279) 在 MSE 維度同樣最優。
Bespoke OLS 的 QLIKE 高達 14,009—— 比最差的 AR(1) r² 還差 7,936 倍 。原因在於 range-based proxy 之間的極高相關性:
| r² | Parkinson | GK | RS | YZ | |
|---|---|---|---|---|---|
| r² | 1.00 | 0.71 | 0.60 | 0.54 | 0.70 |
| Parkinson | 1.00 | 0.95 | 0.89 | 0.81 | |
| GK | 1.00 | 0.98 | 0.86 | ||
| RS | 1.00 | 0.87 |
GK 和 RS 的相關係數高達 0.98,Parkinson 和 GK 為 0.95。OLS 估計出的權重極不穩定:GK 為 +1.95,RS 為 -0.97(rolling window 標準差分別為 4.27 和 3.11),典型的多重共線性症狀。
對比 :Ridge 正則化將 QLIKE 從 14,009 拉回到 1.973,但矯枉過正,所有權重被壓縮到接近 0(最大權重 0.0007),導致預測幾乎為常數,MZ R² 僅 0.002。
發現三:HAR 時間聚合是關鍵驅動力
HAR-Bespoke 成功的關鍵不在於「加權」,而在於 HAR 時間結構 ——將每個 proxy 做日(1 天)、週(5 天平均)、月(22 天平均)三個時間尺度的聚合,再進行迴歸。這等效於在不同頻率上捕捉波動率持續性(volatility persistence),比單一 AR(1) 包含更豐富的資訊。
Corsi (2009) 的 HAR-RV 模型之所以成功,正因其以簡單線性結構近似異質性市場假說(Heterogeneous Market Hypothesis),不同時間尺度的交易者驅動不同頻率的波動率動態。HAR-Bespoke 將此邏輯從 RV 延伸至 OHLCV proxy。
發現四:Yang-Zhang 是最佳單一 proxy
在 5 種 proxy 中,Yang-Zhang (QLIKE=1.562) 勝過其他所有單一 proxy:
- vs r²:-11.5%(節省 0.203 QLIKE)
- vs Parkinson:-2.9%
- vs GK:-1.1%
- vs RS:-2.6%
Yang-Zhang 的優勢在於 同時結合隔夜跳空(overnight return)和日內 range 。其他 range-based estimator 只用日內 OHLC,忽略了收盤到隔日開盤的資訊。
發現五:等權分散化穩健有效
Equal Weight (QLIKE=1.545) 勝過所有單一 proxy AR(1),包括最佳的 Yang-Zhang:
- vs YZ:-1.1%(幅度雖小但穩定)
- vs r²:-12.5%
這與投資組合分散化的邏輯一致:即使不做最佳化,等權組合也能降低估計誤差。在缺乏好的正則化工具時, 等權是安全的基線選擇 。
實務意義
- 日頻波動率預測可以改善 :即使沒有高頻 5 分鐘數據,利用 OHLCV 的多種 proxy 加上 HAR 結構就能取得 QLIKE 18% 的改善。
- 不要直接做 OLS 加權 :range-based proxy 間的高相關性會導致權重爆炸。Ridge 也不理想,要嘛用 HAR 結構,要嘛用等權。
- Yang-Zhang 應取代 r² 作為預設 proxy :它結合隔夜和日內資訊,理論和實證都更優。
- HAR 聚合是低成本且高效益的改善 :HAR 的日/週/月平均只需要過去 22 天的數據,計算量微不足道,卻帶來最大的預測改善。
結論
本研究將 Patton & Zhang (2026) 的 Bespoke RV 概念從高頻日內延伸到日頻 OHLCV 層級。核心結論:
- HAR-Bespoke 是最佳日頻波動率預測模型 (QLIKE=1.448,DM p<0.001 勝所有替代方案)
- 直接 OLS 加權因多重共線性而失敗 ——日頻 proxy 的維度太低、相關性太高
- HAR 時間聚合結構是改善的關鍵驅動力 ,而非「最佳權重」本身
- Yang-Zhang 是最佳單一 proxy ,等權是穩健的無模型基線
局限性
- 目標限制 :以 $r^2$ 為預測目標,這本身是有雜訊的代理。若有 5-min RV 作為更精確的目標,結論可能不同
- 資產範圍 :僅測試 SPY,對波動率結構不同的商品/外匯/新興市場尚需驗證
- 評估窗口 :OOS 期間(2019–2026)包含 COVID 衝擊和 2022 升息,結果可能受極端事件影響
- HAR 結構固定 :使用標準 1/5/22 天聚合,未探索其他天數組合的影響
- 無交叉驗證 :權重僅用單一 IS/OOS 切分估計,未做 expanding window 或 cross-validation
參考文獻
- Patton, A. J., & Zhang, K. (2026). Bespoke Realized Volatility. Journal of Econometrics.
- Patton, A. J. (2011). Volatility forecast comparison using imperfect volatility proxies. Journal of Econometrics, 160(1), 246–256.
- Garman, M. B., & Klass, M. J. (1980). On the estimation of security price volatilities from historical data. Journal of Business, 53(1), 67–78.
- Yang, D., & Zhang, Q. (2000). Drift-independent volatility estimation based on high, low, open, and close prices. Journal of Business, 73(3), 477–491.
- Corsi, F. (2009). A simple approximate long-memory model of realized volatility. Journal of Financial Econometrics, 7(2), 174–196.
實驗腳本: experiments/k969/k969_bespoke_rv.py 結果數據: experiments/k969/k969_bespoke_rv_results.json 數據來源:yfinance(SPY),期間:2006-2026,樣本:5,094 個交易日
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊