把兩個模型加在一起,反而打敗了其中最強的那一個
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
把兩個模型加在一起,反而打敗了其中最強的那一個
SPY 從 2015 年到 2025 年,十年間穿越低波動、Volmageddon、COVID 崩盤、升息循環、後 COVID 復甦,五段截然不同的市場環境。我們拿同一組模型在這五段分別做跨樣本外預測,排出名次。
結果有點反直覺:拿下 5 期平均排名第 1 的,是把 GJR-GARCH 和 HAR 直接對半加起來的等權集成,兩個單獨模型都排在它後面。
背景:問題從 K467 開始
K467 實驗發現了一個麻煩事。HAR 模型的波動率預測排名很好,但拿 HAR 去做 VaR(風險值,用來估計「某天虧損不會超過多少」),反而是所有模型裡最差的一個。
GJR-GARCH 則相反:VaR 表現穩定,但預測精度不如 HAR。
這代表什麼?代表兩個模型各有瞎眼的方向。HAR 對長期波動結構抓得好,但短期尾部風險低估;GJR 反應速度快,但對長程依賴建模偏弱。
如果你只能選一個,就得接受這個取捨。
但如果把兩個平均呢?
實驗設計:最傻的方法
K475 測的就是這個問題,用的方法傻到有點好笑:把 GJR 和 HAR 的條件變異數預測值,直接 50/50 加在一起。
沒有動態權重,沒有 Bayesian 更新,沒有機器學習。就是算術平均。
這個集成模型叫 Ens_GJR_HAR。
資料用 SPY 日報酬,2005 年 2 月到 2026 年 3 月,共 5319 個交易日。訓練窗口固定 2000 天做滾動預測,五個測試期各有約 500-750 天。評估指標用 QLIKE(數字越低代表預測越準),VaR 用 Kupiec、Christoffersen、DQ 三項檢定。
數字怎麼說
跨期預測排名(QLIKE r² proxy,五期平均)
| 模型 | 平均 QLIKE | 平均排名(共 7 個) |
|---|---|---|
| Ens_GJR_HAR | 0.694 | 1 |
| Ens_3way | 0.705 | 2 |
| Ens_HAR_Semi | 0.712 | 3 |
| HAR | 0.737 | 4 |
| Ens_GJR_Semi | 0.740 | 5 |
| GJR | 0.742 | 6 |
| Semi(半變異數) | 32719 | 7(異常值) |
Ens_GJR_HAR 的平均 QLIKE 是 0.694,GJR 是 0.742,差了 6.4%。HAR 是 0.737,也輸了。
![]()
這不是一期的結果,是五期加起來算平均排名,Ens_GJR_HAR 都是第一。5 期裡有 3 期它排 r² 第一名;另外一期排第 2,最後一期排第 4。換句話說,它不是每一段都在前三,但平均排名仍是全模型最好。
用 Parkinson 範圍估計法(高低價計算的波動率代理)來看,也是同樣的格局:Ens_GJR_HAR 平均 QLIKE 0.252,所有模型最低,HAR 是 0.267,GJR 是 0.350。
VaR 表現
最新 1005 個交易日,做 1% VaR 回測。HAR 通過三項檢定(Kupiec p=0.144,違反率 1.49%)。Ens_GJR_HAR 也通過三項(Kupiec p=0.082,違反率 1.59%)。GJR 只過兩項:Kupiec p=0.001,違反率 2.19%,明顯偏高,代表低估了尾部風險。
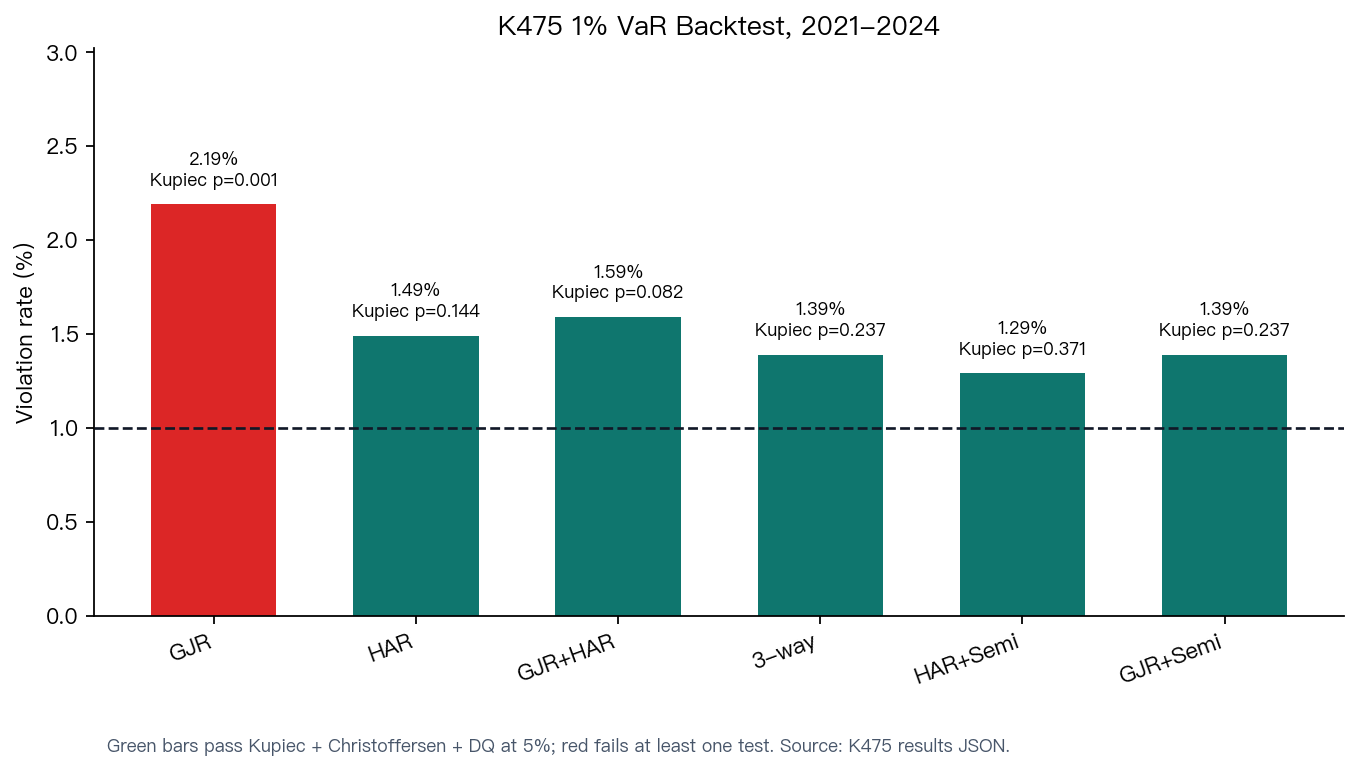
等一下,HAR 的 VaR 在最終期通過了,之前不是說 HAR 的 VaR 很差嗎?
K467 測的是跨 OOS 的平均表現,那個結論仍然成立。K475 這裡的 VaR 只是最近一段期間的快照,不矛盾。重點是:集成把 GJR 的 1% 違反率從 2.19% 壓到 1.59%,同時保住了預測準度。
為什麼加了會更好?
Timmermann 在 2006 年就把這個現象整理出來,後來文獻叫它「forecast combination puzzle」:把幾個模型平均之後,預測表現往往超過其中最好的那一個。
直覺上的解釋有三個:
第一,個別模型各有偏誤,但偏誤的方向不同。GJR 低估長程波動,HAR 低估短期尾部。加在一起,偏誤互相抵消一部分。
第二,集成降低了過度配適的機會。你用 2000 天訓練 GJR,它學到的是樣本內的特定規律,可能在下一段市場環境裡偏掉。集成把這個風險分散了一點。
第三,在市場結構不斷切換的情況下(低波動到 COVID 到升息),沒有任何一個模型能永遠最準。集成提供了跨環境的穩健性,以輕微放棄「在最好的那段期間當冠軍」為代價,換取「不在任何一段期間崩掉」的保險。
這三點加在一起,其實說的是同一件事:在訊號嘈雜的領域裡,過度押注於某一個模型的判斷,往往是在放大偏誤而不是消除它。
相對照:K434 的 BMA 為什麼失敗了
K434 試過 Bayesian Model Averaging(BMA),用歷史預測誤差動態調整各模型的權重。聽起來比等權平均聰明多了。
結果 BMA 把 99.8% 的權重集中在單一模型,等於失去了所有集成效益。
這不是 BMA 這個概念的問題,是這個 spec 的問題:BMA 在預測誤差訊號裡看到一個模型持續領先,就把幾乎全部的籌碼押過去。偏偏波動率預測本來就是很嘈雜的訊號,「過去哪個模型比較準」並不穩定地預測「下一段哪個模型比較準」。押太集中的結果,反而輸給了傻傻的 1/N。
要說明的事
5 期 OOS 確認了 Ens_GJR_HAR 排名最高,但每一期的 Diebold-Mariano 檢定,集成對最佳單模型的優勢都沒有達到統計顯著水準(p 值最低也在 0.10 以上)。
5 期的排名觀察,不等於統計上能宣稱「集成永遠贏」。這是一個跨不同環境的一致性樣式,但樣本期數太少,還沒辦法做強結論。
要真的確認這個優勢持續,需要在未來的市場期間做前向驗證,看排名能不能繼續維持。
對實務的意義
這個結果有個對操作者的簡單啟示:在模型選擇上,如果你有兩個設計邏輯不同的模型,而且各有短板,把它們平均可能比從裡面選一個好,也很可能比花很多時間調參數還穩定。這件事在風險模型上特別值得注意,因為一個 VaR 失準的代價,在實務上遠比預測誤差高出一點的代價嚴重。
複雜的組合方法(動態加權、BMA、機器學習混合)在方法論上沒有問題,但需要更多資料才能訓練,也需要更複雜的超參數穩定。等權是一個極低成本的基線,先跑這個看看,再決定複雜方法是否值得額外成本。
特別是在你不確定市場環境下一段要怎麼走的時候,集成給你的緩衝是「不在某段環境裡踩雷」,精度可能稍微讓出一點,但穩定性留住了。
小結
K475 的核心發現用一句話說:對 SPY 做跨 2015-2025 五段 OOS 測試,GJR 和 HAR 的等權平均(Ens_GJR_HAR)在波動率預測上平均排名第一,並且在最近 1005 個交易日的 1% VaR 回測中通過三項檢定;平均 QLIKE 比最好的單模型低 5.7%。
這個結果對應 Timmermann(2006)整理的 forecast combination puzzle,也印證了 K434 的反面教材:讓 BMA 過度集中反而是錯的方向,把權重押回到 1/N 反而贏了。
5 期 OOS 沒有任何一期達統計顯著,結論要謹慎,但一致性排名是可以觀察到的。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊