資產要配對自己的恐慌指數:黃金多一點,預測模型才看得出差別
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
資產要配對自己的恐慌指數:黃金多一點,預測模型才看得出差別
故事的開頭:一個直覺的問題
你大概聽過 VIX,也就是俗稱的「美股恐慌指數」。它是芝加哥選擇權交易所從 S&P 500 選擇權價格反推出來的隱含波動率,反映市場對未來一個月美股波動的預期。每次新聞講「VIX 飆破 30」、「VIX 創年內新高」,多半就是在講它。
問題是:黃金也有類似的指數,叫做 GVZ,是從黃金 ETF(GLD)選擇權算出來的。如果你手上同時持有 SPY(追蹤 S&P 500 的 ETF)和 GLD,那麼設計一個風險預測模型時,要怎麼用這兩個指數?
第一種直覺:兩個資產都用 VIX。畢竟 VIX 是「市場恐慌」的代名詞,黃金也會被市場恐慌帶動,乾脆都用 VIX。
第二種直覺:各用各的。SPY 用 VIX、GLD 用 GVZ。畢竟 GVZ 才是黃金自己的隱含波動率,邏輯上應該比 VIX 更貼近黃金的真實波動。
哪一種比較準?答案不是「一定有一邊贏」這麼簡單。 它取決於你的投資組合裡黃金佔多少 。本實驗(K1093)系統化地檢驗這個問題。
實驗設計:5 種權重 × 3 個模型 × 3,234 個交易日
我們用 SPY 和 GLD 構築 5 種不同權重的投資組合:
| 投資組合(SPY / GLD) | SPY 比重 | GLD 比重 |
|---|---|---|
| 70 / 30 | 70% | 30% |
| 60 / 40 | 60% | 40% |
| 50 / 50 | 50% | 50% |
| 40 / 60 | 40% | 60% |
| 30 / 70 | 30% | 70% |
每種權重底下都比較三個風險預測模型:
- DCC-GJR :完全不用隱含波動率,純粹靠歷史報酬訓練的 GARCH 家族模型。
- DCC-A4f-SYMM (對稱版):兩個資產都用 VIX 當外生變數。
- DCC-A4f-ASYM (不對稱版,本實驗主角):SPY 用 VIX、GLD 用 GVZ,「資產配對自己的隱含波動率」。
樣本期間是 2005 年 1 月到 2026 年 4 月(n = 5,350 個交易日),其中真正用來評估的樣本外(out-of-sample, OOS)期間從 2013 年 6 月開始,共 3,234 個交易日。
在預測上,我們嚴守「今天的預測只能用昨天以前的資訊」這條紅線。每天的條件變異數預測都是「站在 t-1 日收盤時、預測 t 日的波動率」,模型每 63 個交易日重新校正一次參數。
評估指標包含三類:
- QLIKE :衡量條件變異數預測的準度(負值愈大愈好,越接近 0 越差)。
- VaR / ES 三位一體檢定 :分別測試 1% 與 2.5% 兩個分位數的左尾風險預測在「次數對不對」、「有沒有群聚」、「巴塞爾紅黃綠燈」三個面向。
- FZ 聯合分數 :同時評估 VaR 與 ES 的綜合分數。
模型兩兩比較時用比較檢定推算「兩模型差距是否真實」的統計強度,並要求達到嚴格統計檢驗門檻(嚴格學術門檻,比一般市調慣用的兩倍標準差還高)才算贏。
核心發現:權重一變,結論就變
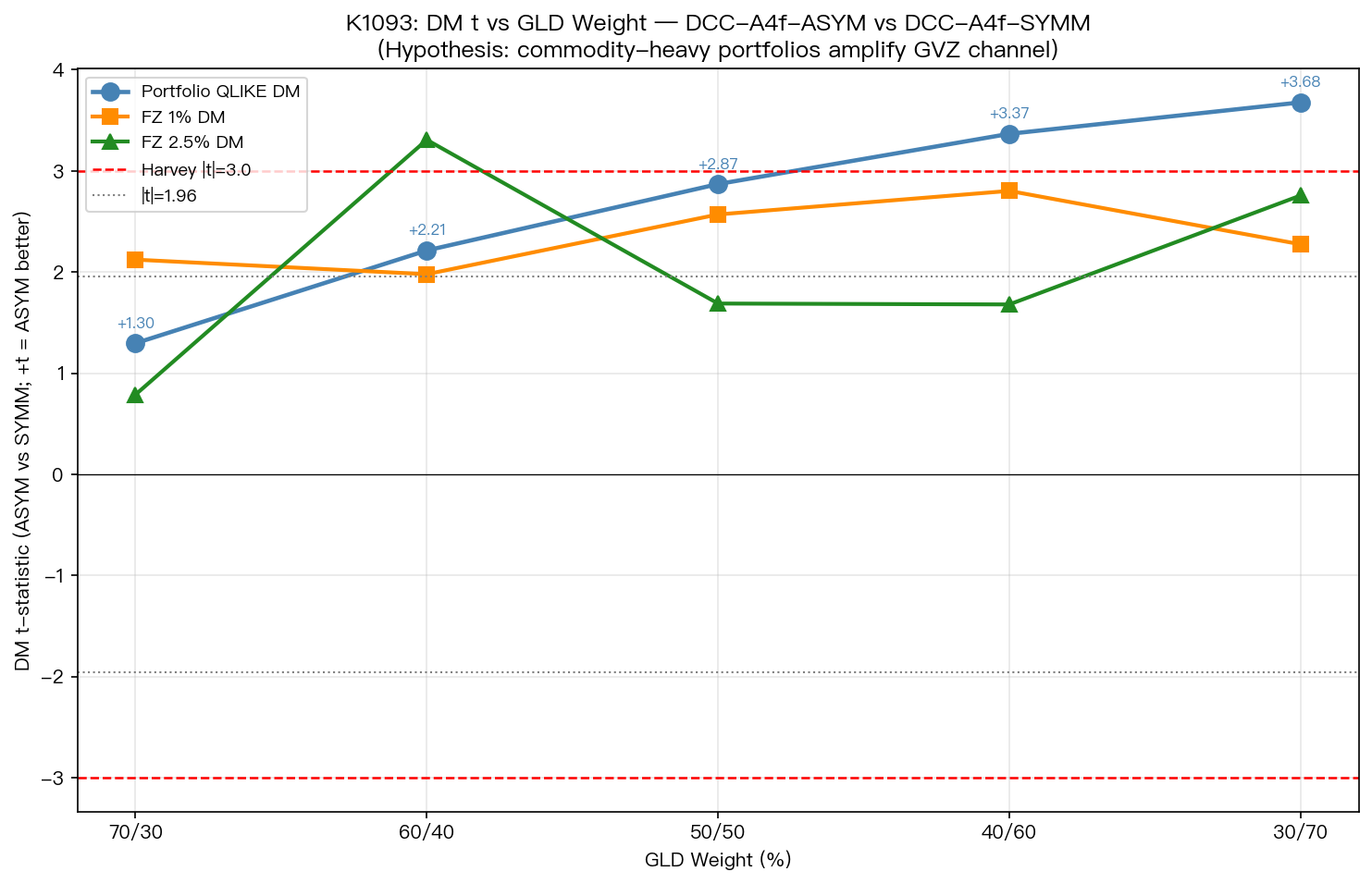
下表是核心結果。每個欄位的數字是「資產配對版(ASYM)」相對於「全用 VIX 版(SYMM)」的統計強度,正值代表 ASYM 比較好。
| 投資組合 | GLD 比重 | QLIKE 統計強度 | FZ(1%)統計強度 | FZ(2.5%)統計強度 |
|---|---|---|---|---|
| 70 / 30 | 30% | +1.30 | +2.12 | +0.79 |
| 60 / 40 | 40% | +2.21 | +1.98 | +3.31 ★ |
| 50 / 50 | 50% | +2.87 | +2.57 | +1.69 |
| 40 / 60 | 60% | +3.37 ★ | +2.80 | +1.68 |
| 30 / 70 | 70% | +3.68 ★ | +2.27 | +2.76 |
★ 表示達到嚴格統計檢驗門檻。
讀這張表的方式是這樣:
- 第一欄是 GLD 在投資組合裡的比重 ,從 30% 一路爬到 70%。
- 第二欄是 QLIKE(條件變異數預測準度)的差距 ,從 +1.30 一路單調往上升到 +3.68。
- 黃金愈重,「資產配對隱含波動率」的優勢就愈明顯。
更精確地說:QLIKE 的統計強度與 GLD 比重之間的等級相關係數是 +1.000 (達顯著水準),這是「完美單調上升」。五個權重排出來的順序與 GLD 比重的順序完全一致,沒有任何例外。
而當 GLD 比重達到 60% 以上(也就是 40/60 與 30/70),QLIKE 的差距就跨過嚴格學術門檻,意思是「資產配對版」的條件變異數預測準度顯著優於「全用 VIX 版」,不是運氣。
為什麼會這樣?一個直白的比喻
把投資組合想成一桶酒,SPY 是高粱、GLD 是紅酒。
- 50 / 50 比例的時候,酒桶裡兩種味道差不多,分別判斷它們各自的細微差異,對整桶酒的整體口味影響有限。
- 30 / 70 比例的時候,紅酒佔七成,整桶酒的味道幾乎被紅酒決定。這時候你用「白酒的描述」來形容紅酒(GLD 用 VIX),跟「直接用紅酒的描述」(GLD 用 GVZ),差距就會被放大。
換成統計的語言:投資組合的條件變異數是
σ²_p = w₁²·h_SPY + w₂²·h_GLD + 2·w₁·w₂·ρ·√(h_SPY·h_GLD)
當 w₂(GLD 權重)變大,h_GLD 的權重就變大。如果你對 h_GLD 的估計比較準(用 GVZ 而不是 VIX),整個 σ²_p 的估計也跟著比較準。這就是為什麼差距是單調的,數學上必然如此,只是在小權重時統計上看不出來,在大權重時才達顯著水準。
但這個故事有個轉折
如果你以為結論是「持有黃金的人,模型應該用 GVZ;持有股票的人,模型可以隨便」,那你只看了一半。
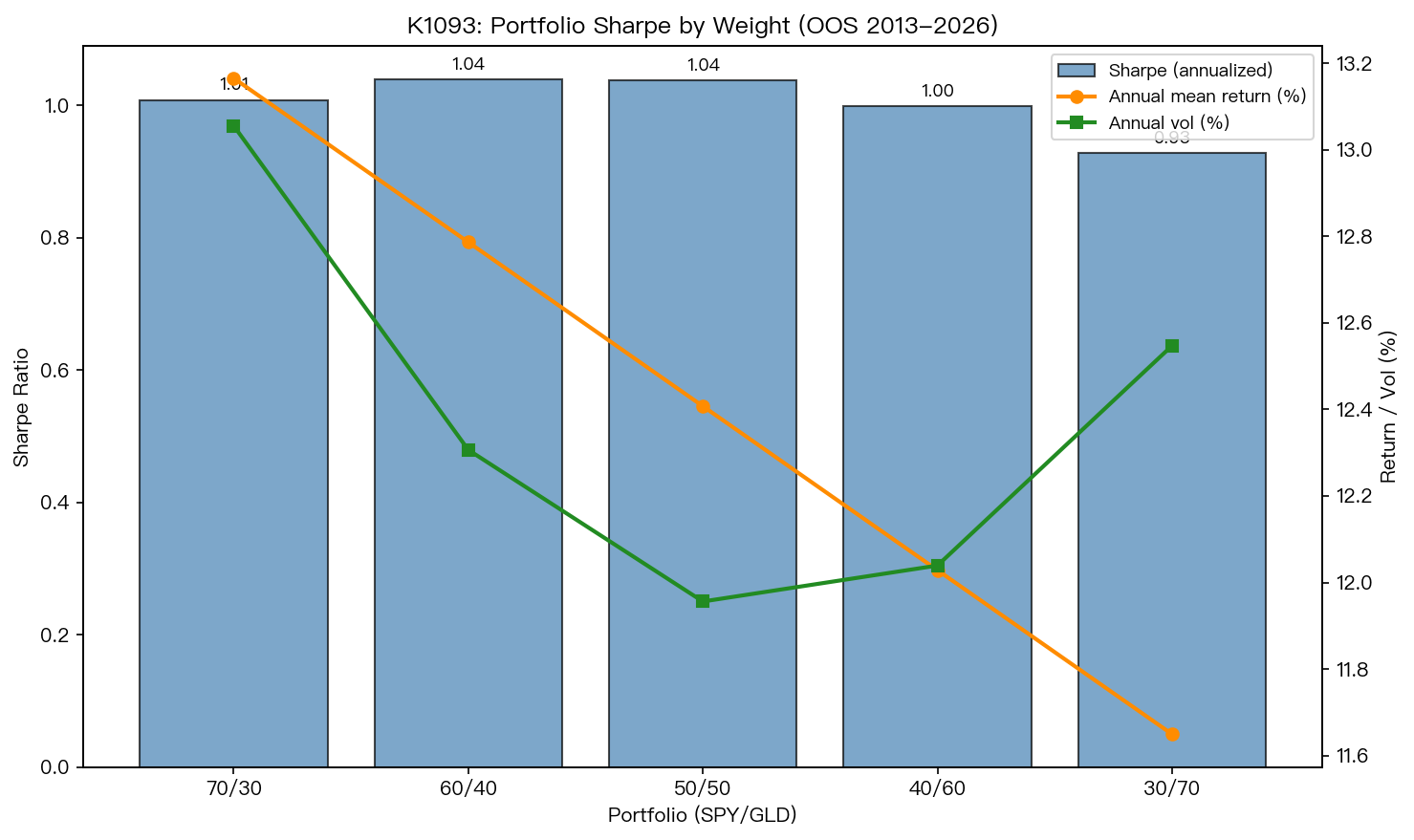
我們再加一張表,看不同權重下投資組合本身的風險調整後報酬:
| 投資組合 | 風險調整後報酬 | 年化報酬 | 年化波動 |
|---|---|---|---|
| 70 / 30 | 1.008 | 13.17% | 13.06% |
| 60 / 40 | 1.039 | 12.79% | 12.31% |
| 50 / 50 | 1.038 | 12.41% | 11.96% |
| 40 / 60 | 0.999 | 12.03% | 12.04% |
| 30 / 70 | 0.928 | 11.65% | 12.55% |
風險調整後報酬最高的是 60 / 40,其次是 50 / 50。當你把 GLD 拉到 60% 以上, 雖然「資產配對版」的預測準度開始顯著贏過「全用 VIX 版」,但投資組合本身的風險調整後報酬卻在下降 。
換言之: 模型優勢最大的權重,恰好不是組合表現最好的權重 。
這對實務工作者意味著什麼?
- 如果你的目標是「最大化風險調整後報酬」,你大概會選 50/50 或 60/40。在這個區間,「資產配對版」對 QLIKE 的優勢還沒跨過嚴格學術門檻(50/50 是 +2.87、60/40 是 +2.21),方向對,但還不是統計上能打包票的事。
- 如果你的目標是「研究『資產配對隱含波動率』是不是真的有用」,那 30/70 是最容易看到效應的權重,但這已經不是大多數人會持有的「分散投資」配置。
統計上沒能成立的另一個故事
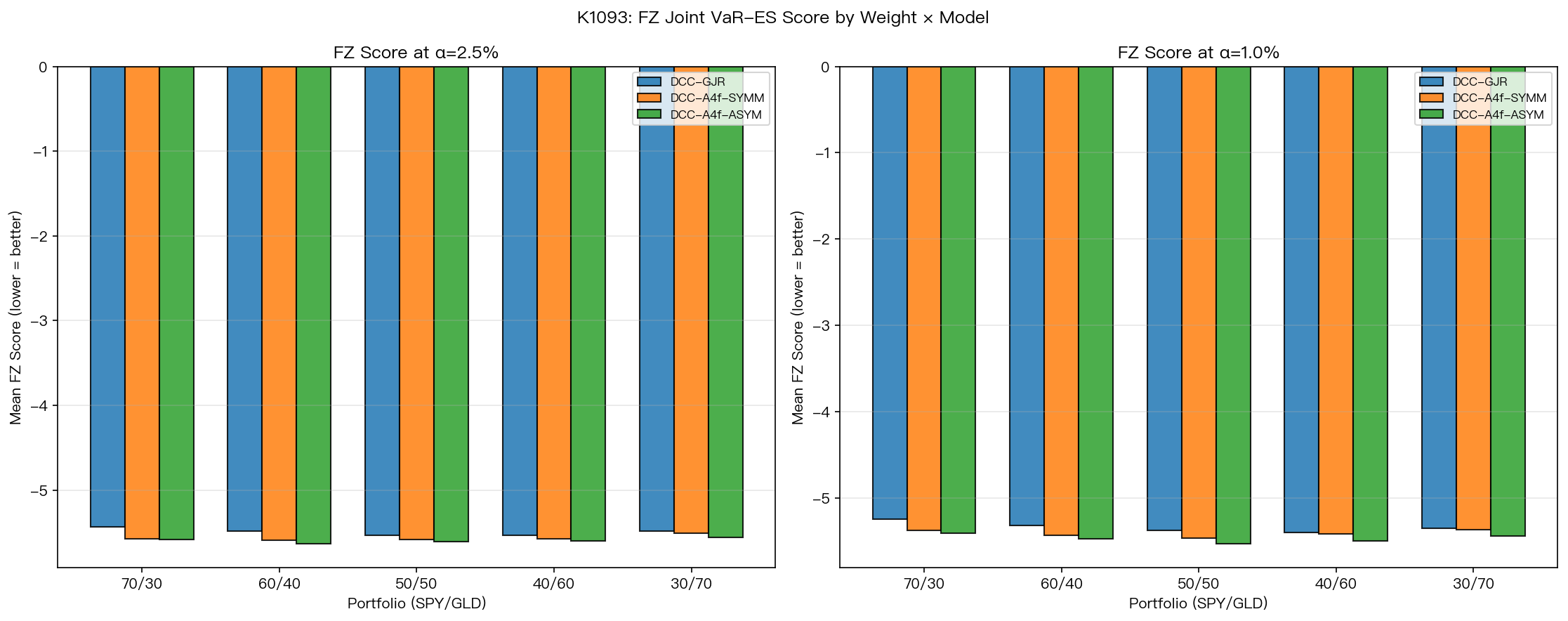
光是看 QLIKE 是不夠的。實務上更關心的是「左尾風險(VaR / ES)有沒有預測準」。我們從 FZ 聯合分數的欄位看到一個複雜的訊號:
- FZ(1%):5 個權重沒有任何一個達到嚴格學術門檻。最高出現在 40/60(+2.80),但還是差一點。
- FZ(2.5%):只有 60/40 一個權重達標(+3.31)。其他都沒到。
也就是說, 「資產配對版」對左尾風險預測的提升並不像對條件變異數的提升那麼一致 。在條件變異數這個層次上,黃金愈重、優勢愈明顯;但在 VaR / ES 這個層次上,這個故事不成立。
三個誠實的限制
第一, 這不是「ASYM 完勝」的結論 。它只在條件變異數預測(QLIKE)上、在 GLD 比重 60% 以上時,才達到嚴格學術門檻。對 50/50 這個一般人最常持有的配置,方向正確、但統計上還算不上「贏」。
第二, 左尾風險的故事比預測準度的故事複雜 。FZ 聯合分數沒有呈現像 QLIKE 那麼漂亮的單調關係。這代表「資產配對隱含波動率」對「平均的波動率預測」與「極端尾部事件」可能是兩回事,不能一概而論。
第三, 違規率(VaR 被突破的比例)在三個模型之間的差距其實很小 (一致都在 1% 上下,誤差都不到 1 個百分點)。這提醒我們:模型差距能在統計檢定下顯著,不代表你拿來實戰會看到天差地別的損益曲線。
結論:把「正確的問題」問完整
很多人問「VIX 跟 GVZ 哪個比較好?」這其實是個沒答案的問題,好不好取決於你要預測什麼資產的波動率。
更精確的問題是: 「在資產 A 占投資組合 w 的權重下,用『資產配對的隱含波動率』取代『全用市場 VIX』,能讓條件變異數預測顯著變準嗎?」
我們的答案是:
- 如果 GLD 比重 ≥ 60%:是的,跨過嚴格學術門檻。
- 如果 GLD 比重在 50% 上下:方向是對的,但統計上還算不上「顯著」的決定性勝利。
- 如果是左尾風險(VaR / ES)的問題:不論權重,幾乎都還沒達到嚴格學術門檻,需要更多研究。
這個結論不是行銷語言、也不是「我們的新模型大勝舊模型」,它就是一個誠實的研究觀察: 資產配對隱含波動率的好處在數學上必然是「資產比重愈大、效果愈明顯」,這個預測在五個權重的測試上完美吻合;但這個好處在實務上並不一定壓倒風險調整後報酬的考量 。下一步要回答的問題是:什麼樣的尾部事件估計方法,能讓「資產配對」的好處在 VaR / ES 上也呈現一致的勝出?這還是個 open question。
資料來源
- 價格資料 :yfinance — SPY、GLD(auto_adjust=True,含股利調整);^VIX、^GVZ。
- 樣本期間 :2005-01-04 至 2026-04-10,共 5,350 個交易日。
- 樣本外評估期 :2013-06-01 起,共 3,234 個交易日。
- 滾動視窗 :1,250 日;每 63 個交易日重新校正參數;CF-Rolling VaR 視窗 252 日。
- 相關文獻 :Engle (2002, JBES)、Engle, Ghysels & Sohn (2013, RES)、Patton (2011, JoE)、Fissler & Ziegel (2016, Annals of Statistics)、Patton, Ziegel & Chen (2019, JoE)。
- 實驗代碼 :K1093(建構於 K1041、K1085、K1088、K1091、K1092 之上)。完整結果與圖表存放於
experiments/k1093/。
本文為 K1093 實驗的讀者面向版本。研究設計、完整數值、所有檢定統計量、以及代碼皆收錄於對應實驗資料夾,歡迎複現與討論。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊