模型看起來更聰明,為什麼 7 年後還是沒贏老方法?
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
模型看起來更聰明,為什麼 7 年後還是沒贏老方法?
新模型的賣點很直接。遇到大漲大跌時,它會用厚尾分配處理極端值,不容易被單日暴衝拉歪。直覺上,這聽起來像波動率模型的升級版。
K1038 把這個直覺拿去做樣本外檢驗。四個資產是 SPY、QQQ、GLD、0050.TW,樣本外從 2019 年 1 月 2 日跑到 2026 年 4 月 10 日。SPY、QQQ、GLD 各有 1,828 個交易日,0050.TW 有 1,759 個交易日。
先把名詞拆清楚。GARCH 是最基本的老方法;GJR 是會多看下跌衝擊的老方法;GAS-t 是主打厚尾與 score-driven 更新的新版本;GAS-t-Lev 則是在 GAS-t 上再加槓桿項。
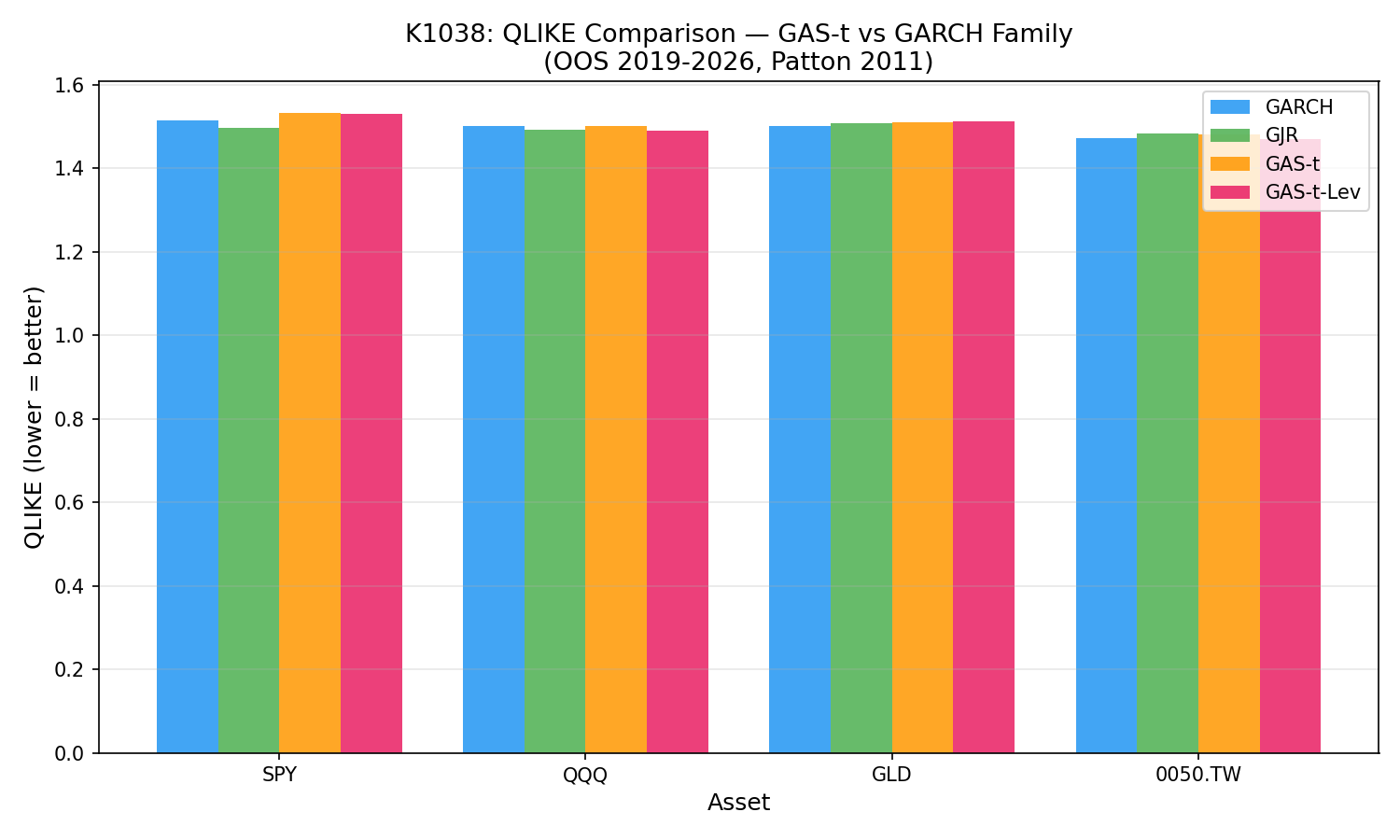
QLIKE 分數越低,代表平方報酬 proxy 下的波動率點預測越好。四個資產的結果如下:
| 資產 | GARCH | GJR | GAS-t | GAS-t-Lev | 點估計最低 |
|---|---|---|---|---|---|
| SPY | 1.514 | 1.496 | 1.531 | 1.530 | GJR |
| QQQ | 1.501 | 1.491 | 1.502 | 1.488 | GAS-t-Lev |
| GLD | 1.501 | 1.508 | 1.510 | 1.511 | GARCH |
| 0050.TW | 1.472 | 1.482 | 1.480 | 1.470 | GAS-t-Lev |
這張表有兩個重點。第一,GAS-t 沒有穩定打敗 GARCH 或 GJR。第二,GJR 在 SPY 和 QQQ 的點估計都很強,不能把 GJR 的數字當成 GARCH 的成績。
以 SPY 為例,純 GARCH 的 QLIKE 是 1.514,GJR 是 1.496,GAS-t 是 1.531。若只看點估計,SPY 上最好的是 GJR,不是 GAS-t。正式比較檢定也沒有給出足夠證據:GARCH 對 GJR 的 p 值是 0.565,GAS-t 對 GJR 的 p 值是 0.324,GAS-t-Lev 對 GJR 的 p 值是 0.084,都過不了研究事前設定的嚴格門檻。
QQQ 也不是簡單的「新模型贏」。GARCH 是 1.501,GJR 是 1.491,GAS-t 是 1.502,GAS-t-Lev 是 1.488。GAS-t-Lev 的點估計最低,可是與 GJR 的差距沒有通過正式檢定。
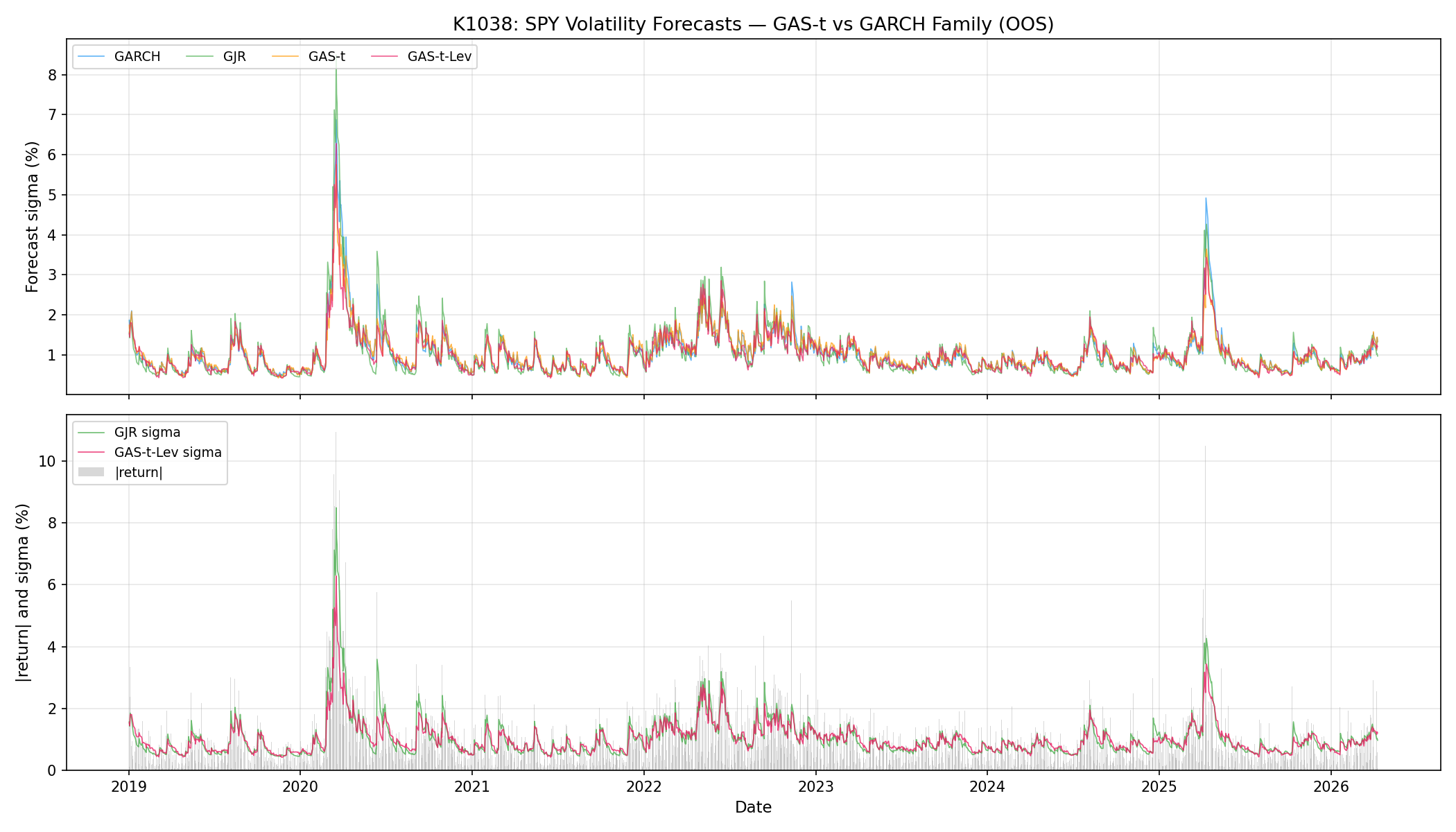
路徑圖也說明了原因。幾條線的大方向很接近,分數差距多半不夠大。模型多一層設計,不代表日線波動率點預測會穩定拉開。
風控線的故事比較不同。SPY 的 1% VaR 實際超標率,GARCH 是 2.30%,GJR 是 2.02%,GAS-t 是 1.70%,GAS-t-Lev 是 1.81%。厚尾版本把超標率往 1% 拉近,但 SPY 仍沒有完整通過 1% VaR 的三重檢查。
GLD 和 0050.TW 的尾端檢查比較支持厚尾設定。這兩個資產上,GAS-t 或 GAS-t-Lev 在 1% VaR 檢查拿到通過;GARCH 與 GJR 沒有。換成投資語言,厚尾分配對「最糟 1% 情境」的校準有幫助,但這不等於它在一般波動率點預測也贏。
所以這篇修正後的結論很窄:K1038 沒有證明 GAS-t 能取代 GARCH 或 GJR。若只看 QLIKE,四個資產各有不同贏家,而且所有模型對比都沒有通過嚴格比較門檻。若看 1% VaR,厚尾分配在部分資產上改善尾端校準。
投資人該分開看兩個問題。想預測明天波動率,GAS-t 沒有交出穩定勝利。想避免尾部風險線太常低估,厚尾分配值得保留在工具箱裡。
資料來源與限制:本文基於 VolPred K1038 實驗腳本與 experiments/k1038/k1038_results.json。價格資料來自 yfinance。全樣本期間為 2005-01-01 至 2026-04-10;樣本外起點為 2019-01-02。SPY、QQQ、GLD 樣本外各 1,828 筆,0050.TW 為 1,759 筆。QLIKE 以平方報酬作為波動率 proxy;正式比較採研究預先設定的嚴格門檻。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊