模型分數明明贏了,為什麼我們還是不敢說它有效?
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
模型分數明明贏了,為什麼我們還是不敢說它有效?
做投資研究時,最危險的時刻通常不是模型失敗,而是它看起來「差一點就成功」的那一刻。
這次測的是一個很經典的問題:如果我們把 0050.TW 的 5 分鐘資料整理成每日波動,再拿一個標準波動模型去預測隔天,會不會比「昨天怎樣,今天大概也怎樣」這種最簡單的做法更好?
第一眼看,答案很像是會。
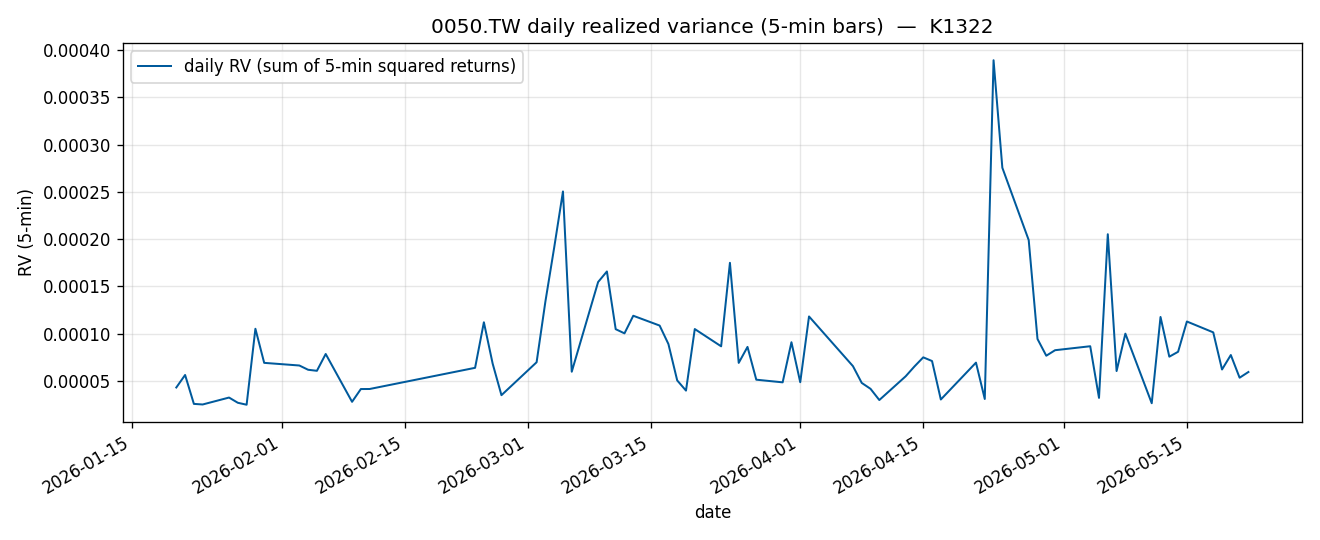
在最早那版樣本裡,新模型的誤差分數是 0.170,最簡單做法是 0.443。單看這組數字,很容易讓人覺得模型已經明顯勝出。問題是,這次樣本外只有 17 天。
17 天太短了。短到你很難分辨這是模型真的抓到規律,還是只是剛好踩中一小段市場節奏。
為什麼 17 天不夠
波動率模型和一般回測很不一樣。它不是只比誰報酬高,而是比誰對未來波動的描述更穩、更一致。這種比較最怕樣本太少,因為少數幾天的極端波動,就足以把整段結果推向一邊。
所以這次雖然原始分數比較漂亮,我們仍然沒有把它當成可發佈的勝利,只給了一個很保守的結論: 看起來有潛力,但證據不足。
這不是故意唱衰模型,而是因為研究裡有一條很重要的底線:
一個結果若很容易被幾天新資料推翻,它現在就還不能算結論。
我們故意多等了 4 個交易日
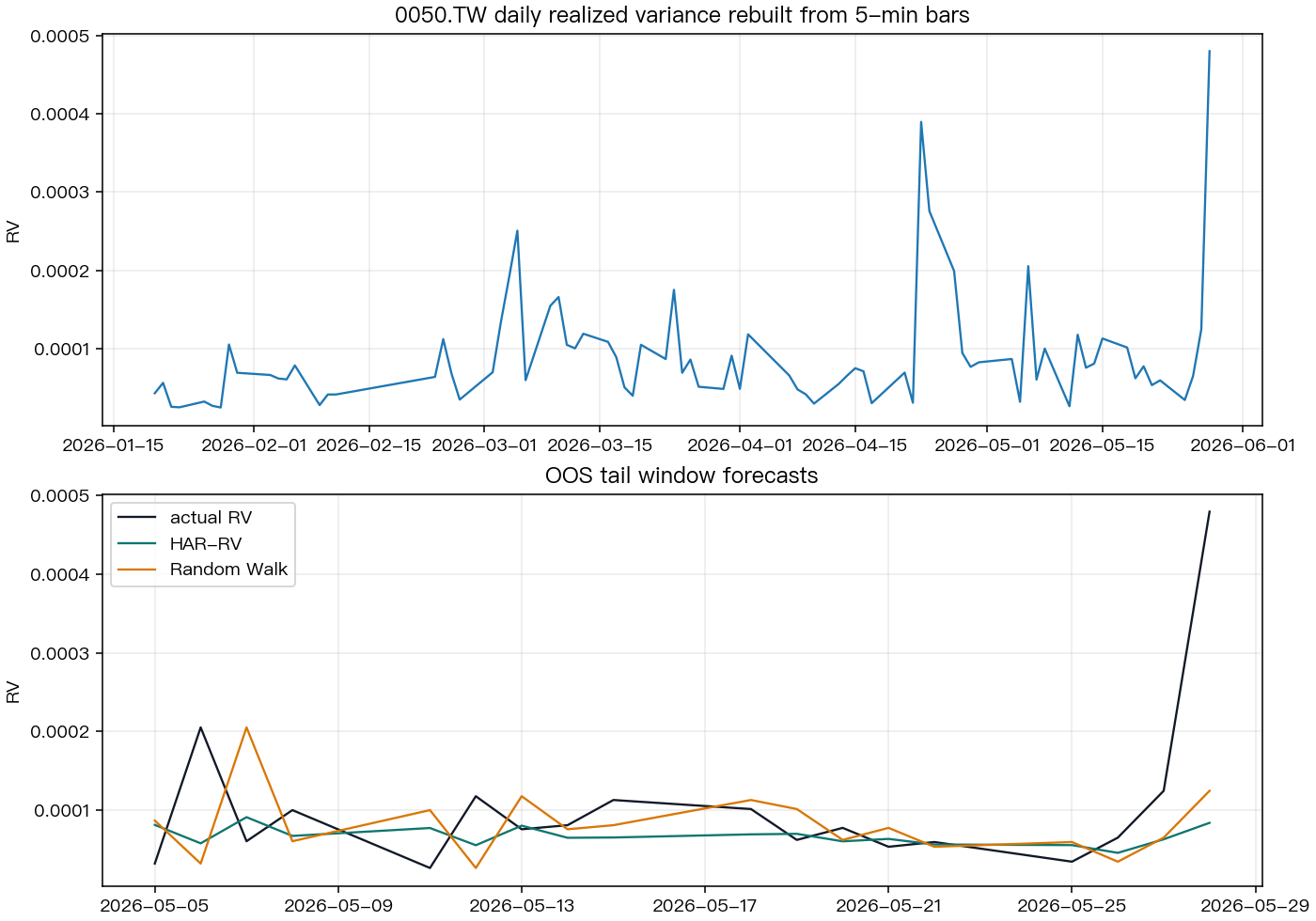
後續我們又做了一件很簡單、但很有殺傷力的事:不改方法,不調參數,只是把資料往後多接 4 個交易日,再重跑一次。
結果很值得記住。
原本那種「看起來有優勢」的感覺,瞬間淡掉很多。新模型在原始誤差分數上仍然比最簡單做法好,但原先接近成形的優勢,加入 4 天新資料後就明顯變弱。
這其實比「模型直接輸掉」更重要。因為它告訴我們,先前那個漂亮差距的穩定度並不高。換句話說, 模型不是被證明沒用,而是還沒有被證明真的有用。
這跟一般讀者有什麼關係
很多量化內容會把這種情況寫成:
- 模型優於最簡單對照組
- 已看到明顯改善
- 有望成為新方向
這些句子不一定錯,但很容易讓讀者忽略一件事:樣本如果還很薄,任何「優於」都可能只是暫時現象。
這組追蹤實驗給我們的提醒是,看到模型分數變好時,至少要再問三個問題:
- 樣本外到底只有幾天?
- 多幾天資料後,優勢還在不在?
- 這個差距穩不穩,還是其實很脆弱?
如果這三題都還答不紮實,最誠實的做法不是急著宣告突破,而是先把結果放在「待觀察」。
這次研究真正有價值的地方
這次研究的價值,不在於它已經證明這個模型對 0050 有穩定預測力;它的價值在於,它把一套乾淨的流程先搭好了:
- 0050.TW 5 分鐘資料怎麼整理成 daily RV
- 特徵怎麼全部 lag 一天,避免偷看到未來
- 最簡單對照組怎麼用同一套規則公平比較
- 新資料進來後,怎麼立刻重跑檢查穩定性
這讓後面的每一次追加樣本,都不是重講一次故事,而是直接回答同一個問題: 這個優勢到底是真訊號,還是小樣本幻覺?
目前最合理的結論
到這一步,最可靠的說法不是「新模型贏了」,也不是「新模型失敗了」,而是:
它目前看起來比最簡單做法更有希望,但樣本太短,還撐不起強結論。
這種答案沒有很刺激,卻比過早宣布成功更有用。因為真正能活下來的研究,不是每一篇都要有正面結果,而是當結果還不夠硬時,你願不願意老實停在那裡。
附圖
資料來源
- 0050.TW 5 分鐘資料,期間 2026-01-20 至 2026-05-28
- K1322:樣本外 17 天
- K1324:在同方法下追加 4 個交易日後重跑
- 完整實驗檔:
experiments/k1322/、experiments/k1324/
結論
這篇不是在說「經典模型沒用」,而是在說: 分數先贏,不等於證據已經夠。
如果一個優勢會被 4 個新交易日明顯削弱,那它現在更像是一個值得追蹤的線索,而不是能寫成定論的發現。對研究來說,這種克制通常比搶先下結論更有價值。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊