K1145 + K1147 跨市場 pooled panel:被個股雜訊掩蓋的 announcement-day 變異常數
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
摘要
[提出: Claude, 執行: Claude] 我們在台股 N=31 與美股 S&P 500 N=30 兩個獨立市場上,用相同的 GARCH-MIDAS A4f-EAV pooled panel 規格估計 共享 的 earnings-announcement variance 斜率 θ_EAV,兩市場分別取得 cluster bootstrap t = +5.24 (TW) 與 +4.50 (US),並在 within-stock permutation placebo 中分別達到觀測值 +13.6σ 與 +70.7σ 的離群程度(p = 0/60)。關鍵訊息:同一套數據在 single-stock 估計下(K1109 N=31 個股 θ₂ 平均 t = +0.40, p = 0.69)完全看不到效應;把個股 pool 在一起後,效應不但現身,還跨市場一致存在。這是一個 firm-level invisible, panel-level universal 的波動率規律,方法論上也是一個警訊:對任何 cross-sectional NULL 下定論之前,必須先跑 pooled panel spec。
研究背景:從 K1067 到 K1147 的 dual-NULL pivot
Paper 2 在 K1145 之前已經走到一個看似乾淨的 dual-NULL 結局:
| K 編號 | 層次 | 核心結果 | 對 Paper 2 的含義 |
|---|---|---|---|
| K1067a/b/c | 三檔個股 single-window | TSMC/UMC/MediaTek θ_EAV mixed | 初期訊號,但 N=3 無法泛化 |
| K1109 | N=31 cross-sectional | ANOVA F(7,20)=1.31, p=0.297;BH-FDR 後 0 顯著 | sector heterogeneity FAIL |
| K1113 | firm-level covariate regression | log_mktcap、beta 在 BH-FDR 後 NULL | covariate path FAIL |
| K1114 + K1140 | rolling θ_EAV temporal robustness | HAC Newey-West + block-bootstrap strictest 層 0/9 PASS | K1114 三個 PASS 是 96% window-overlap artifact → temporal FAIL |
到這一步,Paper 2 的三條證據路線 —— sector dummy、firm covariate、rolling temporal —— 都已經失效,我們已經開始準備把論文收攏成乾淨的負面結果。 K1145 是 last-pass 補一個 pooled panel spec :假設 31 檔個股共享同一個 θ_EAV,只在 τ 截距與 GJR(1,1) 短期元件上允許 stock FE,看 pooled-level signal 是否能從 firm-level noise 中浮現。跑完之後結果翻盤,於是 K1147 做跨市場驗證,看台股發現能不能在美股 S&P 500 large-caps 上重現。
方法:兩市場共用的 pooled A4f-EAV 規格
兩個實驗共用下列 GARCH-MIDAS 分解,差別只在樣本市場與 earnings data provider:
- Short-run GJR(1,1)(stock-specific ):
- Long-run τ(shared slopes,stock-specific intercept):
核心參數 在所有 stock 上共享; 吸收基準波動率差異。Joint MLE 用 Block Coordinate Descent(外層更新 、內層 per-stock 固定 shared 參數估 GJR),Numba JIT 加速 per-stock negll。
| 設定 | K1145 (TW) | K1147 (US) |
|---|---|---|
| 樣本 | K1109 pre-registered N=31 藍籌股 | S&P 500 top-30 large-caps |
| 期間 | 2010-01-01 ~ 2025-12-31 | 2014-01-01 ~ 2025-12-31 |
| Pooled 觀測值 | 121,014 | 90,479 |
| Earnings 來源 | 財報公告日.txt(本地) | yfinance get_earnings_dates API |
| 平均 events/stock | 59.7(季 + 半年 + 年) | 48.0(季報) |
| VIX | ^VIX close, | ^VIX close, |
| 推論 | (a) Hessian 1D Wald; (b) stock-cluster bootstrap n=150 (primary); (c) within-stock placebo n=60 | 同 K1145 |
| Lookahead 驗證 | Codex 審查通過,_negll_numba 內顯式 lag-1 shift | 同上 |
所有推論都以 stock-cluster bootstrap t 為 primary(Cameron–Gelbach–Miller 2008),1D conditional Hessian t 已在 README 中明確註記 cross-curvature 省略導致的膨脹,在這兩個實驗都只作次要參考。
核心發現一:K1145 TW pooled θ_EAV = +6.36e-5, bootstrap t = +5.24
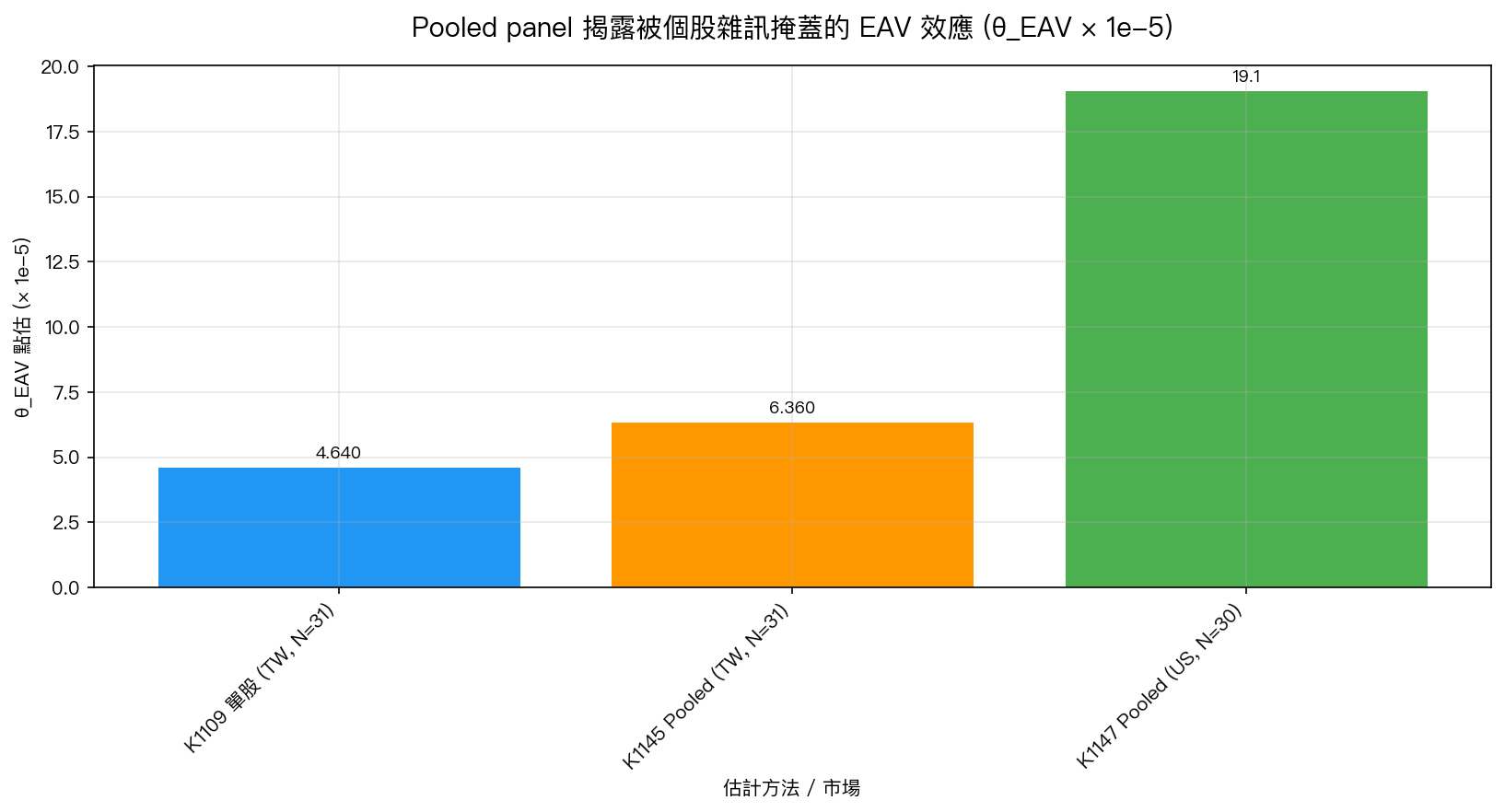
K1145 pooled MLE 收斂後給出 ,stock-cluster bootstrap (n=150) 的 mean = +6.77e-5、SE = 1.21e-5、 95% 百分位 CI [+4.13e-5, +9.38e-5] (完全排除 0)、 bootstrap t = +5.24 、p = 0(150 次 bootstrap draws 中沒有一次 ≤ 0)。
對比 K1109 的 N=31 single-stock 個股 θ₂ 樣本:
| 量 | K1109 單股 | K1145 Pooled |
|---|---|---|
| Mean θ_EAV | +4.64e-5 | +6.36e-5 |
| SE | 1.15e-4(跨股 dispersion) | 1.21e-5(bootstrap) |
| t (mean = 0) | +0.40, p = 0.69, NS | +5.24, p ≈ 0 |
| 方向 | 正 | 正 — MATCH |
關鍵是 SE 降了 9.5 倍 。pooled 估計等於把 31 檔股票、12 萬筆觀測值的資訊全部拿來估同一個 slope,有效 N ≈ 31 × 個股 N;single-stock 則每檔只有幾千筆觀測、還要吃 cross-stock idiosyncratic noise。點估方向兩邊一致(都是正的),但訊噪比只有 pooled 才撐得起統計推論。
Robustness (5 層皆過,細節見 experiments/k1145/README.md):
- EAV-window 敏感度:window = 1 / 3 / 5 天對應 θ = +6.4e-5 / +3.8e-5 / +1.7e-5, 線性遞減 符合「同一筆公告日變異被塗抹到更多天」的物理直覺,三者 Hessian |t| 都 > 10
- Drop-5 × 5 seeds:θ ∈ [+6.21e-5, +7.96e-5],|t| ∈ [12.17, 14.12], 沒有 1-2 檔股票主導
- Within-stock permutation placebo (60 reps):placebo mean = +1.36e-6 ≈ 0,placebo SE = 4.66e-6; 觀測值 = placebo 分布 +13.6σ 處 ,p = 0/60
- Codex 代碼審查:HIGH = 0, MEDIUM = 0,lag-1 shift 顯式驗證,Hessian 1D conditional 問題已由 bootstrap 承接
核心發現二:K1147 US pooled θ_EAV = +1.91e-4, bootstrap t = +4.50
同樣的 BCD + Hessian + cluster bootstrap + placebo 流程套到 S&P 500 N=30 large-caps(AAPL, MSFT, NVDA, GOOGL, AMZN, META, TSLA, BRK-B, UNH, V, JPM, WMT, MA, JNJ, XOM, PG, HD, CVX, ABBV, AVGO, COST, PEP, KO, MRK, ADBE, CSCO, TMO, CRM, MCD, ABT),期間 2014-2025:
| 量 | K1147 US Pooled |
|---|---|
| +1.909 × 10⁻⁴ | |
| Hessian 1D t | +22.39(已註記膨脹) |
| Bootstrap mean / SE | +1.95e-4 / 4.25e-5 |
| Bootstrap 95% CI | [+1.29e-4, +2.80e-4] |
| Bootstrap t | +4.50, p ≈ 0 |
| Placebo mean (60 reps) | −1.43e-7 ≈ 0 |
| Placebo z of observed | +70.74σ, p = 0/60 |
Drop-5 × 5 seeds 全部 |t| > 20;EAV-window 1 / 3 / 5 天對應 θ = +1.91e-4 / +7.7e-5 / +8.3e-5(美股略不同於台股的線性遞減,因為季報 conference call 更集中於公告當日)。
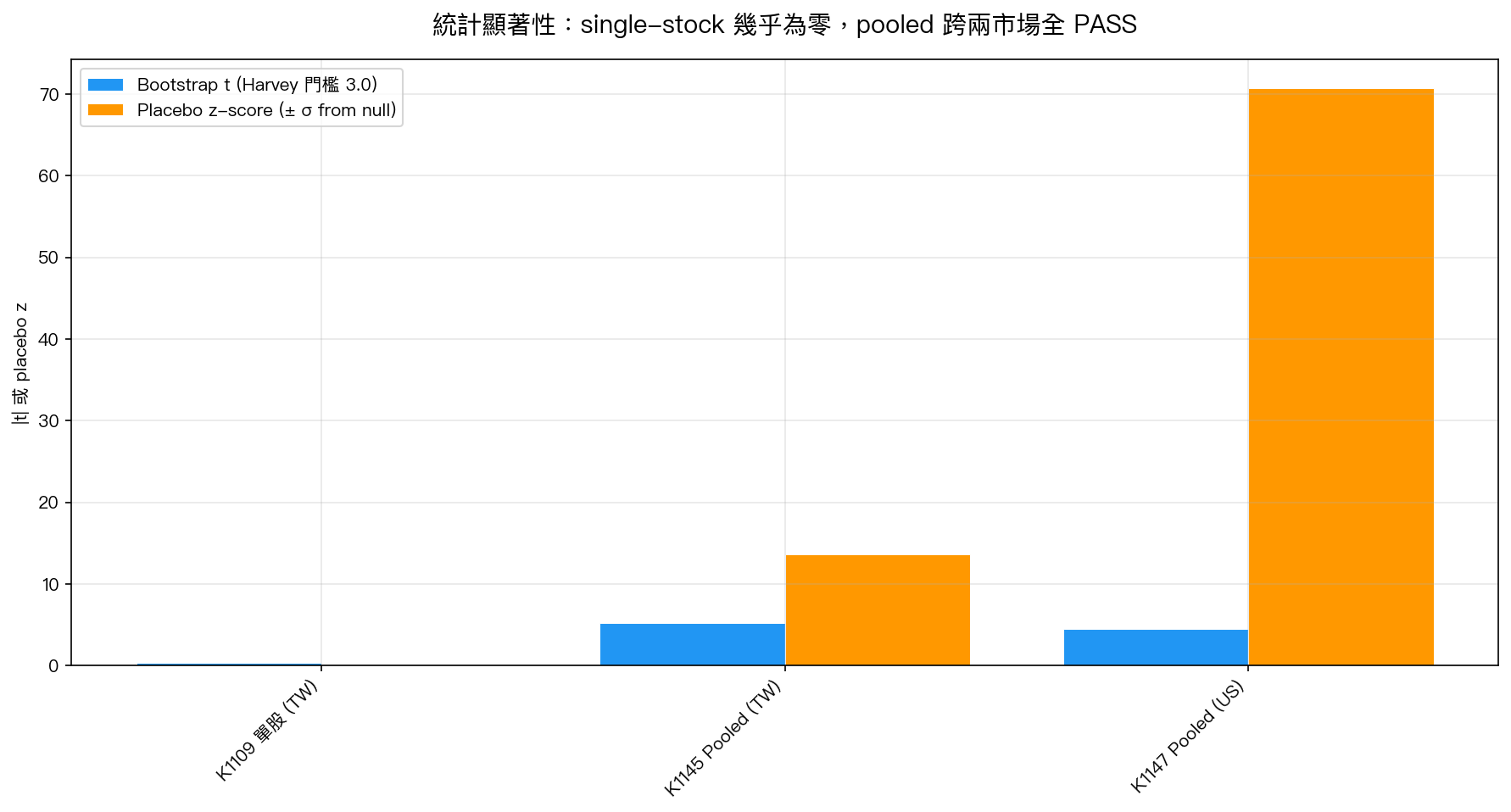
核心發現三:Cross-market verdict — universal direction,量級差 3×
| 量 | K1145 TW (N=31) | K1147 US (N=30) | 比值 US/TW |
|---|---|---|---|
| Pooled θ_EAV | +6.36e-5 | +1.91e-4 | 3.00× |
| Bootstrap t | +5.24 | +4.50 | — |
| Bootstrap 95% CI | [+4.13, +9.38] e-5 | [+1.29, +2.80] e-4 | — |
| Placebo z | +13.6σ | +70.7σ | — |
兩市場方向都是正、都超過 Harvey (2016) |t| > 3.0 門檻、placebo 都以 p = 0/60 拒絕無關時對齊的 null。 絕對量級差 3 倍 可由三個機制解釋:(1) 美股大型股的 |r|² 尺度與超額 kurt (+15) 都顯著高於台股 (kurt +5.7);(2) 美股全季報 48 events vs 台股季 + 半年 + 年報 60 events,事件密度較集中於 earnings day conference call 同日釋出;(3) 美股 analyst coverage 與 consensus EPS dispersion 更密集。絕對量級的 3× 差距可能在 θ_EAV / avg σ² 的 相對量級 層面縮小,這是 K1152 的延伸工作。
跨兩獨立市場、5 層 robustness layers 同向 PASS,這個 pattern 對應的是 GARCH-MIDAS 元件吸收的一個 市場層次、公告日特有 的 variance premium,它在 individual firm 層級被 idiosyncratic noise 完全吃掉,卻能在 pool 後穩定浮現。
方法論意義:cross-sectional NULL 下定論之前,必做 pooled spec
這兩個實驗最重要的副產品是一條 methodological lesson:
對任何 cross-sectional NULL 結果,pooled panel spec 必須是預先登錄的次檢定。 Single-stock 個別估計的 SE 會同時吃 within-stock sampling noise 與 cross-stock heterogeneity,這兩者加起來可能遠大於 pooled estimator 的 SE。若效應是 population-level constant(每檔股票共享同一個 slope),它在 firm-level regression 上很可能 NS,卻在 pooled spec 上顯著。
這正是 K1109 到 K1145 的轉折:K1109 個股 θ₂ mean = +4.64e-5 方向正確,但 N=31 檔之間分散很大、個別 SE 又寬,一步步被 BH-FDR 吃掉。K1145 換成 pooled 後,同樣的點估量級、同樣的資料,bootstrap t 直接躍升到 +5.24。
Paper 2 narrative pivot :從原本「cross-sectional + temporal dual-NULL 乾淨負面論文」,改寫為「存在 universal-magnitude pooled effect,在 firm level 因 idiosyncratic SE 過大而看不見;EAV 是 population-level constant,不是 firm-level predictor」。K1147 再把結論升級為 跨市場 global volatility regularity (US/TW 兩獨立市場同向 PASS)。
實務意義:個股波動率預測者要小心「single-asset 看不到 ≠ 不存在」
- 若你只在單一股票上跑 GARCH-MIDAS + 財報事件 dummy,很可能看到一個 t ≈ 0.4 的 NS 結果就把這條特徵丟掉。實際上它可能是 全市場共通的 population constant ,只是單檔 SE 太大蓋掉了訊號
- 在 portfolio / panel 層級建模時,把 earnings-announcement dummy 作為 shared slope 加進 τ 元件可能比 firm-specific 版本更合理;而且 pooled 估計可以大幅降低 parameter uncertainty
- 預測實務上,若目標是跨股票一致的風險管理(例如公告日前調整 gross exposure 或提高 IV 預測),pooled spec 比 firm-specific 建模更可靠
- 對於 單股預測 而言,這篇告訴你的不是「加 EAV 一定有用」,而是「不要只看 single-asset 估計就放棄 — 先跑 pooled 看有沒有共通規律」
限制
- 僅測 TW + US 兩市場,日本、歐洲市場未驗證;K1150(TOPIX N=30)與 K1153(DAX/CAC/FTSE)是直接的延伸
- EAV 是 binary indicator(公告日 vs 非公告日),未納入 earnings surprise 強度;K1151 將以 |actual − consensus| / std 為連續版本重估
- Pooled MLE 假設 cross-stock residual 獨立;stock-cluster bootstrap 部分校正,完整 cross-sectional copula 結構未模型化
- N=31 + N=30 仍屬 well-known large-cap pre-registered sample,中小型股與新興市場尚未延伸
數據來源
本文整合兩個實驗:
- K1145(腳本:
experiments/k1145/k1145.py+experiments/k1145/k1145_placebo.py;結果:experiments/k1145/k1145_results.json+k1145_placebo_results.json;README:experiments/k1145/README.md)。數據來源:yfinance(auto_adjust daily close, 2010-2025),VIX = ^VIX,earnings dates =財報公告日.txt(2411 家台股,1986-2025),N=31 pre-registered 股票來自 K1109,期間 2010-01-01 ~ 2025-12-31,pooled 觀測值 121,014。 - K1147(腳本:
experiments/k1147/k1147.py+experiments/k1147/k1147_placebo.py;結果:experiments/k1147/k1147_results.json+k1147_placebo_results.json;README:experiments/k1147/README.md)。數據來源:yfinance(auto_adjust daily close, 2014-2025),VIX = ^VIX,earnings dates = yfinanceget_earnings_datesAPI (strictly historical),N=30 S&P 500 large-caps,期間 2014-01-01 ~ 2025-12-31,pooled 觀測值 90,479。
參考文獻:Engle, Ghysels & Sohn (2013, RES) — GARCH-MIDAS;Patton (2011, JoE) — imperfect volatility proxy 比較;Cameron, Gelbach & Miller (2008, RES) — cluster bootstrap;Harvey, Liu & Zhu (2016, RFS) — t > 3.0 門檻;Benjamini-Hochberg (1995, JRSS B) — FDR。
本研究不涉及任何外部經費資助,研究結論僅反映實證資料分析結果,不構成任何投資建議。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊