為什麼風險模型要用「金本位分數」量?SPY 19 年的答案
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
一個老問題:哪個風險模型比較準?
衡量一個風險模型「好不好」,過去最常被引用的指標有兩個:VaR 違約率有沒有貼著目標(例如 1% 信心水平,違約率就該接近 1%),以及 Expected Shortfall(ES,極端損失的條件平均)有沒有低估真實尾部。
兩個指標分頭看都還合理,但 單獨拿任何一個對兩個模型做比較 ,會踩到一個漏洞:ES 在數學上不是 elicitable(Gneiting 2011 JASA 證明),也就是說,沒有單一的 loss function 能讓「對的 ES 預測得最低分」。比 ES 沒辦法用「分數最低者勝」這個標準裁。
直到 Fissler & Ziegel 在 2016 年的 Annals of Statistics 找到答案:把 VaR 和 ES 看成一個「pair」,這對組合 有 jointly elicitable 性質 ,而且存在唯一的 strictly consistent joint scoring function class。從此業界與學界有了風險模型比較的「金本位」。
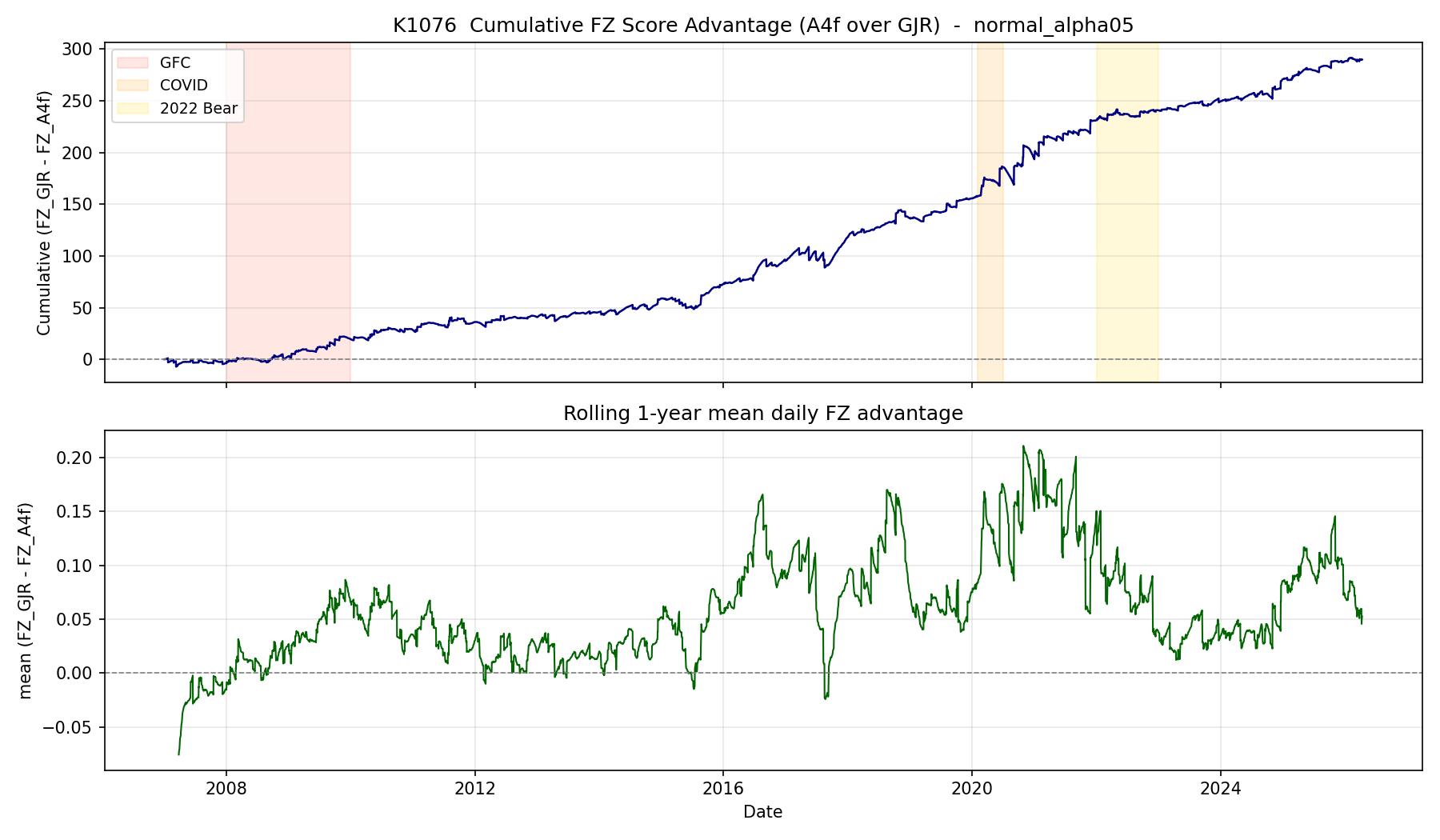
K1076 就是把這套金本位拉到 SPY 19 年(2007–2026,n=4,848 筆日資料),對兩個候選做正面對決:經典的 GJR-GARCH(1,1),與我們先前 K988 找到的贏家——A4f(一個用 VIX² 做尺度校準的 component-GARCH)。
結果一:A4f 全面顯著贏,但贏不大
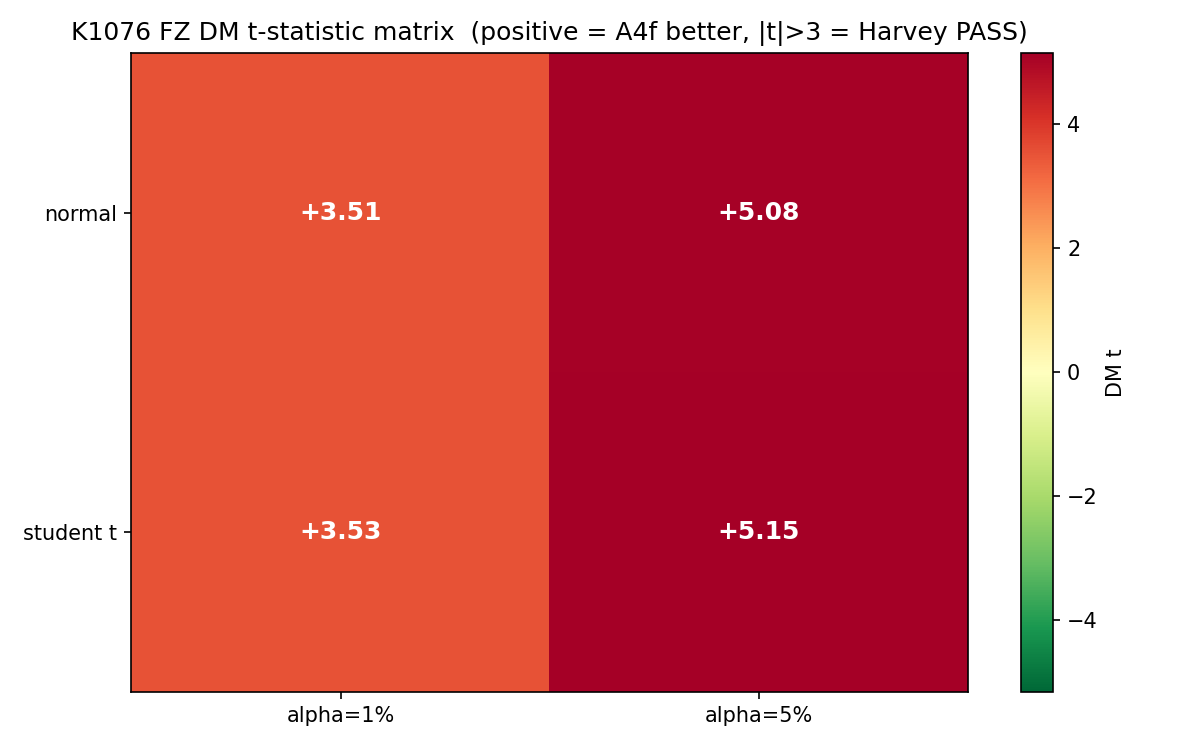
| 分布假設 | 信心水平 α | FZ_GJR | FZ_A4f | DM 統計量 | p 值 | Harvey 通過 |
|---|---|---|---|---|---|---|
| Normal | 1% | −3.178 | −3.318 | +3.51 | 0.0005 | ✓ |
| Normal | 5% | −3.753 | −3.813 | +5.08 | 3.8e-07 | ✓ |
| Student-t(5) | 1% | −3.336 | −3.433 | +3.53 | 0.0004 | ✓ |
| Student-t(5) | 5% | −3.758 | −3.815 | +5.15 | 2.6e-07 | ✓ |
FZ 分數越低越好(負得更深)。四個 spec(兩種分布 × 兩種 alpha)裡,A4f 全部贏 GJR,DM 統計量都壓過 Harvey (2016) 的 |t|>3 嚴格門檻,已是論文等級的 evidence。
但贏的幅度要看清楚:FZ 平均分數差 1.5%~4.4%,不算壓倒性。A4f 的角色更像同類模型裡 一個系統性更穩的選擇 ——每天小贏一點點,19 年累積起來才在 DM 上達到極度顯著。跟「神奇收益曲線」的故事完全是兩回事。
結果二:ES 還是低估了,兩個模型都是
風險模型最容易讓人放心過頭的部分,就是「我的 ES 看起來貼著歷史」。Acerbi-Szekely (2014) 的 Z2 test 用 bootstrap 重抽 1,000 次去看 ES 的條件期望偏差,結果寫在下表(Z2<0 代表真實尾部損失比預測大):
| Spec | Z2_GJR | p_GJR | Z2_A4f | p_A4f |
|---|---|---|---|---|
| Normal, α=1% | −1.711 | 0.000 | −1.267 | 0.000 |
| Normal, α=5% | −0.327 | 0.000 | −0.267 | 0.000 |
| Student-t, α=1% | −0.389 | 0.008 | −0.281 | 0.022 |
| Student-t, α=5% | −0.352 | 0.000 | −0.298 | 0.000 |
兩個模型 8 個 spec 全部在 5% 水平拒絕 H₀,意思是 ES 在絕對意義上仍 under-forecast。這是 SPY 收盤價樣本的老問題:尾部事件(含 2008 金融海嘯、2020 COVID 急殺)的損失幅度超出任何 GARCH 家族 model 的條件分布假設。
A4f 沒有解決這個結構性問題,但 它的 |Z2| 一致低於 GJR ——偏誤雖在,相對精度更高。實務上的意義:模型告訴你 ES 是 −2.5%,你可能要心裡準備 −2.8%~−3.0%;如果你信的是 GJR 給的 −2.4%,那要打的折扣更大。
結果三:A4f 的優勢在「平靜期」,不是 crisis
把 19 年資料按 VIX 分四個區段(Normal α=5% spec),結果有點反直覺:
| 區段 | VIX 範圍 | 樣本數 | DM 統計量 | Harvey 通過 |
|---|---|---|---|---|
| Low | [0, 15) | 1,545 | +2.89 | ✗ |
| Normal | [15, 25) | 2,421 | +4.01 | ✓ |
| High | [25, 40) | 703 | +1.60 | ✗ |
| Crisis | [40, ∞) | 179 | +1.05 | ✗ |
Crisis 區段樣本只有 179 天,統計力本來就不夠,所以 DM 沒過 Harvey 門檻 不代表 A4f 在恐慌期不行 ,比較像「資料還不夠多到分得出來」。
真正值得注意的是 Normal 區(VIX 15–25,常態市場那 5 年裡比例最大的時段):DM=+4.01,A4f 在這裡顯著贏。這顯示 A4f 透過 VIX²₍ₜ₋₁₎ 校準的長期 τ 元件,主要是在「市場沒事發生時」吃下對方來不及調整的緩慢資訊。
A4f 真正的強項不在 black swan,而 落在 boring market 不會掉以輕心 。「危機時才該用更好的模型」的直覺剛好踩反,平日的小累積,才是 19 年差異的真正來源。
給讀者的三個取用方式
第一,挑 risk model 不要只看 VaR 違約率。違約率只是邊際指標;joint FZ 分數能同時懲罰過保守(VaR 太寬)與過樂觀(ES 太低)兩種錯誤,是目前學界給 risk management model comparison 的最嚴格判準。
第二,做 stress test 時別只看 crisis bucket。如果你的模型在 boring market 系統性偏離,accumulating error 才是長期 P&L 的真正殺手,這個樣本下 A4f 對 GJR 的 19 年 t=+5.08 就是這條道理的具體化身。
第三,所有 GARCH 家族在 SPY 收盤價上 ES 都會偏小。如果監管或內部風控用 ES 來定資本,留 10–20% 的 cushion 是合理的,這不算「模型錯了」,比較像收盤價資料先天的 limitation。換高頻或 intraday range estimator(K683 已驗證過)才有結構性改善空間。
對 Paper 9 的意義
K1076 是 Paper 9 risk-management section 的核心 empirical evidence。把這個結果寫進 manuscript 後,A4f 的優勢從 K988 的 QLIKE-only 擴張到 joint VaR/ES 金本位,同樣的故事在四個獨立 spec 上重複,每個都有 Harvey-level 統計顯著性,這在 risk-modeling 文獻裡屬於 rare evidence。下一步是把 ES under-forecast 的結構性偏誤獨立成一個 sensitivity 章節,並比較 Patton-Ziegel-Chen 2019 的 0-homogeneous 與 1-homogeneous FZ variants。
實驗 K1076 :Fissler-Ziegel joint score,SPY 2007–2026 全 OOS(n=4,848),refit window 2,000 / step 63。完整數據與重現腳本在 experiments/k1076/;參考文獻 Fissler & Ziegel (2016) Annals of Statistics 44(4):1680–1707、Acerbi & Szekely (2014) Risk 27(11)、Patton-Ziegel-Chen (2019) J. of Econometrics 211:388–413。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊