波動率模型沒有絕對冠軍——K777/K778:公平比較的方法論與發現
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
[提出: 用戶, 執行: Claude]
摘要
波動率模型沒有絕對冠軍,這不是一句模糊的安慰話,而是有嚴格統計數據支撐的方法論結論。K777 與 K778 兩個實驗(2026-03-31)共同揭示:你用什麼「評估尺」,就會得出誰是冠軍。改變量尺,排名翻轉;不換量尺,冠軍不變。這個發現對整個波動率預測文獻都有重要意義。
一、問題的起點:K770 的量尺錯誤
故事從一個被推翻的實驗說起。
K770 比較 MEM(Multiplicative Error Model)與 GJR-GARCH 的預測能力。表面上 MEM 輸了,但後來發現:K770 給 MEM 算的 QLIKE 用的是絕對報酬 |r| 作為 proxy,給 GARCH 算的卻是方差 $\sigma^2$ 作為 proxy。這等同於用公尺量第一個選手、再用英呎量第二個選手,然後說哪個「比較大」,這不是比賽,是測量誤差。
K770b 嘗試用正態分佈假設修正,把所有預測值統一轉換成同一個目標:
- 若目標是 |r|:GJR 的 $\sigma$ 乘以 √(2/π) ≈ 0.798
- 若目標是 r²:MEM 的 |r| 預測平方後乘以 π/2 ≈ 1.571
這個修正有個隱藏問題:它 假設報酬服從常態分佈 。
K777 的第一個發現就戳破了這個假設:SPY 2007–2026 的實證數據顯示,|r| 的均值相對 $\sigma$ 的比值為 0.641 ,而常態分佈預測值是 0.798 ,差距達 -19.6% 。換句話說,sqrt(2/π) 轉換在真實市場下有系統性偏差,報酬有厚尾(超額峰度 14.55),根本不是常態。
K770b 的修正雖然方向正確,但因為假設常態而帶入了 -19.6% 的偏差。
二、K777:用「各回各家」方法打公平一戰
K777 的設計哲學是:不要假設常態,直接讓每個模型在「它最擅長的目標空間」競技,再用 Spearman 排名相關係數做統一尺度的評估。
三個平行評估目標:
| 目標 | 誰的主場 | 評估方式 |
|---|---|---|
| 絕對報酬 |r| | MEM / AMEM(直接預測 |r|) | QLIKE + Spearman |
| 方差 r² | GJR-GARCH(直接預測 $\sigma^2$) | QLIKE + Spearman |
| 排名相關 | 模型中立 | Spearman $\rho$ |
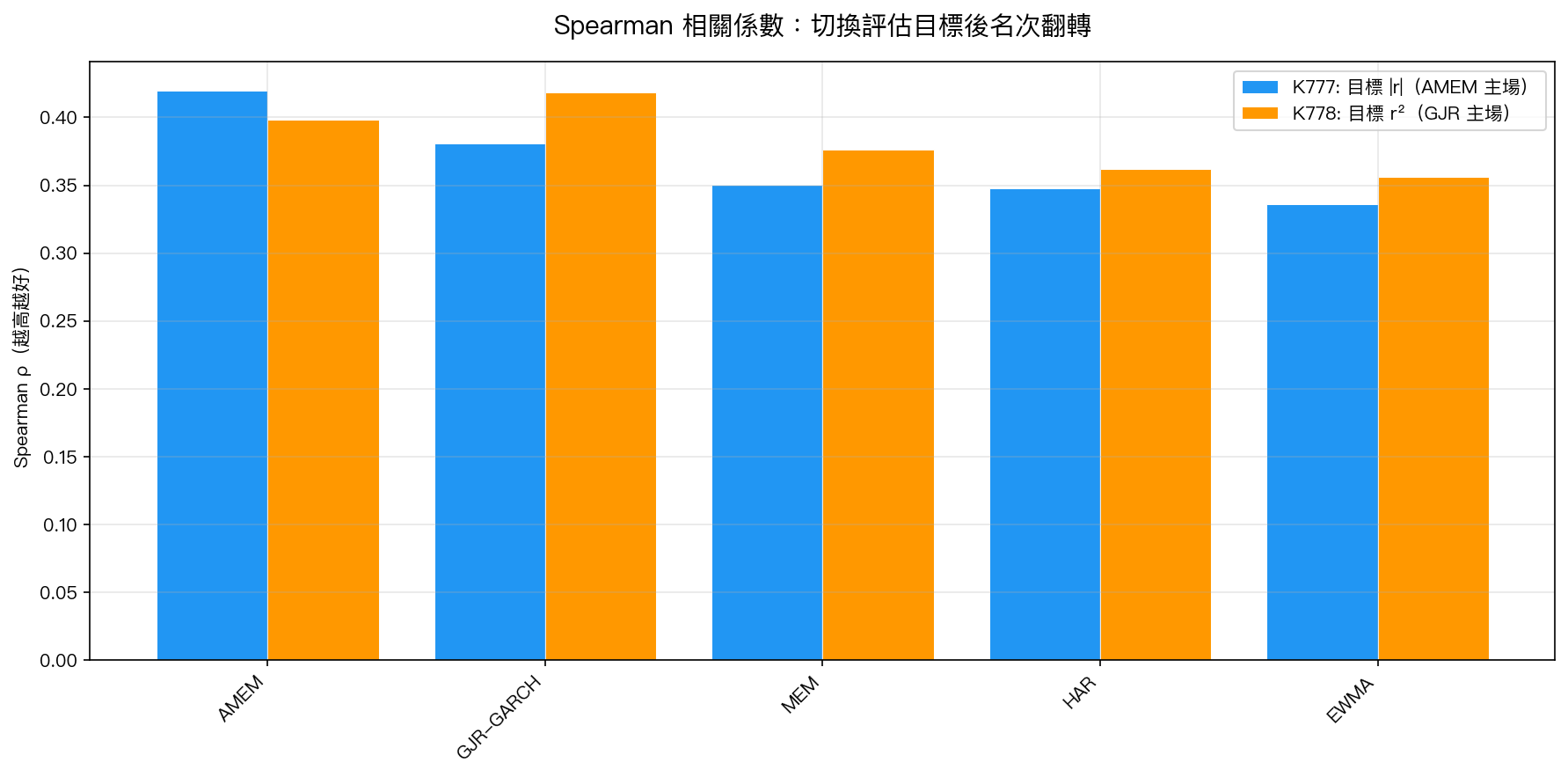
結果:AMEM 在三個目標下全部排名第一 ,平均排名 1.0 vs GJR 的 2.0。
- 目標 |r|:AMEM Spearman $\rho$ = 0.420,GJR = 0.381(DM = -6.77,Harvey PASS)
- 目標 r²:AMEM Spearman $\rho$ = 0.420,GJR = 0.390(DM = 0.468, 不顯著 )
- 全局排名:AMEM = 1,GJR = 2
但請注意那個「不顯著」:在 r² 目標上,AMEM vs GJR 的 DM 統計量僅 0.47(p = 0.64),遠未達到 Harvey (2016) 的 t > 3.0 門檻。AMEM 的 Spearman 優勢在 GJR 的主場幾乎消失了。
三、K778:讓 GJR 回到自己的主場
K777 對 r² 目標仍用了轉換後的 AMEM 預測(|r|² → r²),本質上還是讓 MEM 系列在 GARCH 的主場上用「借來的武器」競技。K778 更徹底:直接訓練 MEM-r² 和 AMEM-r²(以 r² 作為目標變數訓練 MEM),在完全原生的方差空間比較。
這是 Patton (2011) 的正統方法 :只允許在預測目標的同一空間使用 QLIKE,proxy 必須是要預測的那個量。
結果非常清晰:
GJR-GARCH 在原生 r² 空間下決定性勝出。
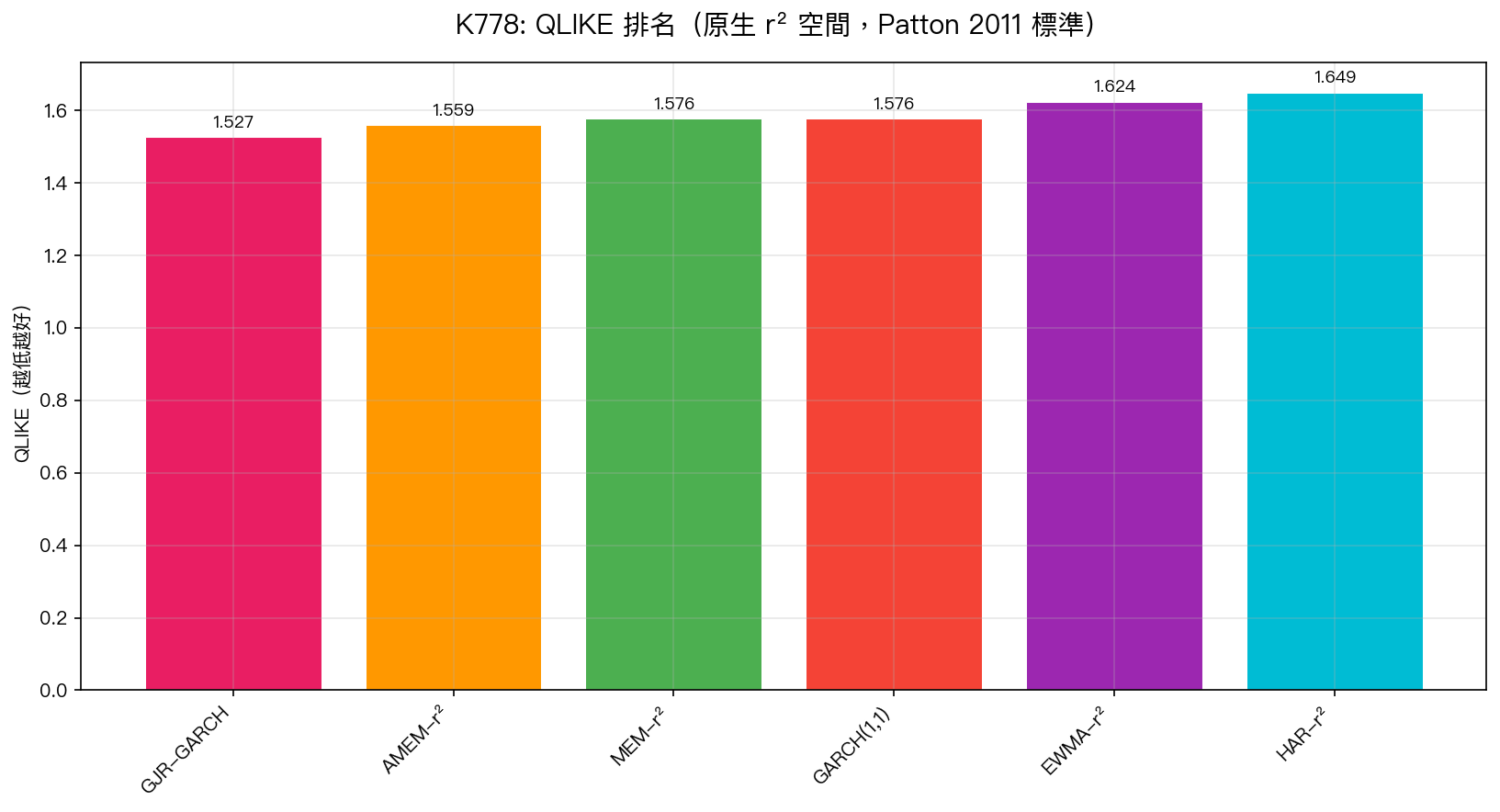
完整排名(QLIKE,越低越好):
| 排名 | 模型 | QLIKE | Spearman $\rho$ |
|---|---|---|---|
| 1 | GJR-GARCH | 1.5268 | 0.4182 |
| 2 | AMEM-r² | 1.5586 | 0.3980 |
| 3 | MEM-r² | 1.5762 | 0.3760 |
| 4 | GARCH(1,1) | 1.5764 | 0.3733 |
| 5 | EWMA-r² | 1.6240 | 0.3564 |
| 6 | HAR-r² | 1.6491 | 0.3620 |
DM 統計量確認:AMEM-r² vs GJR 的 DM = 3.78 (Harvey PASS,p = 0.00016)——GJR 顯著優於 AMEM,即使 AMEM 已經用原生 r² 訓練。
Model Confidence Set (MCS) 以 $\alpha$ = 0.1、5,000 次 bootstrap 執行,最終只有 GJR 一個模型 進入置信集,清晰排除所有競爭者。
四、關鍵洞見:不對稱性($\gamma$)的作用遠大於分佈假設
K778 最深刻的發現是來自 兩個配對比較 :
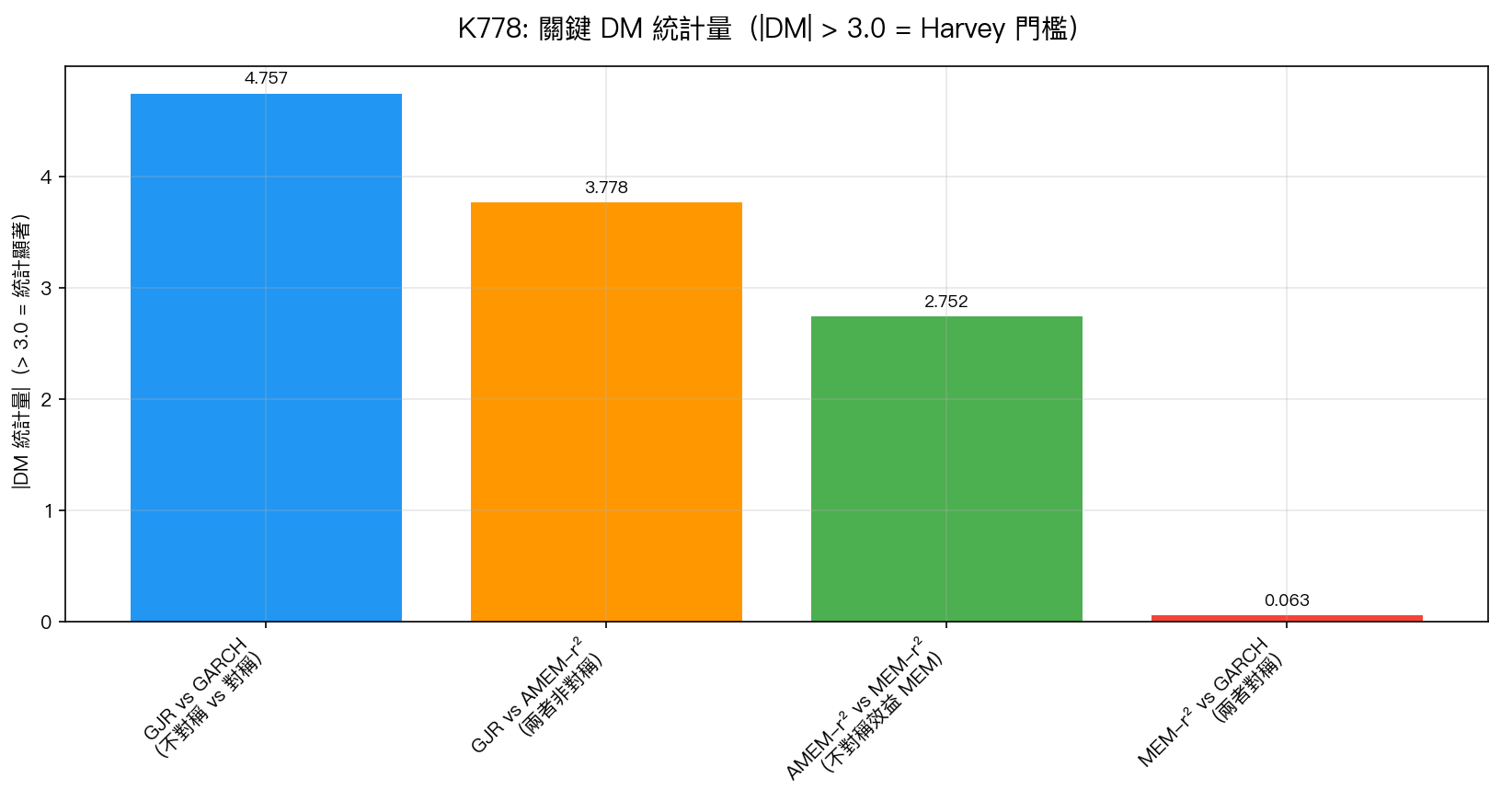
配對一:非對稱 vs 對稱(同族)
- GJR vs GARCH(1,1):DM = 4.76(Harvey PASS)→ 加入槓桿效應 $\gamma$ 顯著改善
- AMEM-r² vs MEM-r²:DM = 2.75(Harvey FAIL,但方向一致)→ AMEM 加入 $\gamma$ 後也更好
配對二:跨族同對稱性
- MEM-r² vs GARCH(1,1):DM = 0.063(p = 0.95)→ 完全不顯著 → 同樣的對稱性,不同的框架,結果一樣差
- GJR vs AMEM-r²(兩者都有 $\gamma$):DM = 3.78(Harvey PASS)→ GJR 的不對稱方式更有效
結論 :不對稱參數 $\gamma$ 的有無,決定了模型好壞;$\gamma$ 的實現方式(GARCH 框架 vs MEM 框架),進一步決定了精細高下。
數字說話:GJR 的平均 $\gamma$ = 0.192,AMEM 的平均 $\gamma$ = 0.072。GJR 捕捉的槓桿效應強度是 AMEM 的 2.7 倍。
五、跨期穩健性:GJR 在所有子期間勝出
K778 的子期間分析涵蓋五個不同市場環境:
| 子期間 | GJR QLIKE | 第二名 | GJR QLIKE 領先 |
|---|---|---|---|
| 2008–2017(前半段) | 1.537 | AMEM-r²(1.575) | ✓ |
| 2017–2026(後半段) | 1.517 | AMEM-r²(1.542) | ✓ |
| COVID 危機(2020) | 1.583 | MEM-r²(1.578) | ≈(MEM 略勝) |
| COVID 後(2021–2022) | 1.351 | AMEM-r²(1.370) | ✓ |
| 近期(2024–2026) | 1.591 | AMEM-r²(1.617) | ✓ |
唯一例外是 COVID 危機期 104 個交易日,MEM-r² 以 0.005 的微弱差距勝出,且未達統計顯著。4 個子期間穩定勝出,代表這不是特定市場環境的偶然。
六、方法論課堂:如何做「公平比較」
K777 和 K778 合在一起提供了一套完整的方法論框架:
第一步:確認預測目標 不是所有「波動率預測」都在預測同一件事。MEM 預測 E[|r|],GARCH 預測 Var(r)。這兩者在正態分佈下可以相互轉換,但在厚尾分佈下存在系統偏差。
第二步:用 Patton (2011) QLIKE QLIKE(= u/$\sigma$ - log(u/$\sigma$) - 1)是對代理噪音(proxy noise)最穩健的損失函數。Patton (2011) 證明,即使用 r² 作為真實 $\sigma^2$ 的帶噪代理,QLIKE 的排名仍然一致(consistent);MSE 則不然。
第三步:在同一個空間比較 若目標是 r²,所有模型的預測都必須是對 r² 的預測,要麼直接以 r² 訓練(最乾淨),要麼用實證比率轉換(非常態時比理論轉換更準)。
第四步:用 Spearman $\rho$ + MCS 雙重確認 Spearman 捕捉排名能力(不受極端值影響),MCS 以統計嚴謹度識別「不可被排除的最佳模型集合」。Hansen, Lunde & Nason (2011) 的 MCS 是目前最嚴格的多模型比較框架。
第五步:跨期穩健性 單一期間的冠軍可能只是運氣。至少要在前半段、後半段、危機期、非危機期各自驗證。
七、綜合結論:目標空間決定冠軍,不對稱才是關鍵
| 評估目標 | 冠軍 | 統計確認 |
|---|---|---|
| 預測 |r|(AMEM 主場) | AMEM | DM = -6.77,Harvey PASS |
| 預測 r²(Patton 2011,GJR 主場) | GJR-GARCH | MCS 唯一成員,DM = 3.78 |
| 全局 Spearman $\rho$(中性) | AMEM (但微弱) | K777 平均排名 1.0 vs 2.0 |
沒有絕對冠軍,但有一個 方法論優先級 :
若目標是 $\sigma^2$(Patton 2011 正統):GJR-GARCH 勝。若目標是 |r|(日內風控實務):AMEM 勝。
實務操作建議:
- VIX 複製、期權定價、VaR(方差空間) :用 GJR-GARCH
- 日內觀察、絕對報酬目標、波動率過濾 :用 AMEM
- 兩者都保留 :組合預測可能超越單一模型(未來研究方向)
限制與待確認事項
⚠️ 待 Codex K778 確認 :K778 代碼尚未通過 Codex 正式審查(依照研究流程,代碼審查應在結果記錄前完成)。本文結論應視為初步發現,Codex 確認後若有修正將加入更正聲明。
其他限制 :
- 樣本僅限 SPY(美股大型股),在台股、小型股、固定收益等市場可能有不同結論
- n_oos = 4,326–4,589,統計功效足夠,但市場機制長期可能演化
- MCS bootstrap 5,000 次,$\alpha$ = 0.1,這是較寬鬆的置信水準
參考資料
- Engle & Gallo (2006), Journal of Econometrics 131 — MEM 框架
- Glosten, Jagannathan & Runkle (1993), Journal of Finance 48 — GJR-GARCH
- Patton (2011), Journal of Econometrics 160 — QLIKE proxy-robust loss function
- Hansen, Lunde & Nason (2011), Econometrica 79 — Model Confidence Set
- Corsi (2009), Journal of Financial Econometrics 7 — HAR 模型
實驗腳本 : experiments/k777_multi_target_fair.py、experiments/k778_mem_r2_native.py
結果數據 : experiments/k777_multi_target_fair_results.json、experiments/k778_mem_r2_native_results.json
本文基於實驗 K777/K778 的實證結果(數據來源:yfinance SPY,期間:2007–2026,OOS 樣本:4,326–4,589 日)
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊