K940: ML vs 計量經濟學的波動率預測對決——MLP 為何災難性失敗?
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
[提出: Claude, 執行: Claude]
摘要
本研究(K940)系統性比較了機器學習模型(MLP 神經網路、Ridge 線性迴歸、Random Forest)與計量經濟學模型(GARCH、GJR、MF-GJR)在 SPY 日頻波動率預測上的表現。核心結論: MF-GJR(VIX) 以 QLIKE=1.4582 蟬聯最佳 ,MLP 神經網路災難性失敗(QLIKE=651,520),Random Forest 是唯一可行的 ML 模型但仍不勝。關鍵洞見:RF 的特徵重要性揭示 VIX 佔 35.1%,而 MF-GJR 的乘法結構已從結構上編碼了這個非線性關係。
研究背景
在 K889 確認 MF-GJR(VIX) 為最佳單模型(QLIKE=1.458)、K937 確認四種集成方法均無法超越之後,本實驗聚焦於一個自然的後續問題: 機器學習是否能發現計量模型遺漏的非線性關係?
理論上,ML 模型(特別是神經網路)可以擬合任意複雜函數,不受 GARCH 族的參數化限制。然而,日頻波動率預測面臨一個根本性挑戰:
日頻 的信噪比極低,偏態係數(skewness)= 15.7,峰態係數(kurtosis)= 347。這意味著絕大多數每日觀測都被噪音主導,只有少數極端事件攜帶真實訊號。
本實驗是本研究計畫 第一個正式 ML 實驗 。
方法與數據
| 項目 | 設定 |
|---|---|
| 資產 | SPY(S&P 500 ETF) |
| 訓練期 | 2004-01-01 ~ OOS 開始前(擴展窗口) |
| OOS 期間 | 2016-01-04 ~ 2025-12-31(2,514 個交易日) |
| 目標變數 | (Patton 2011 proxy-robust target) |
| 再訓練頻率 | 每 63 個交易日(季頻),共 40 次 refit |
| 特徵 | 11 個, 全部使用 或更早資訊 (無前視偏誤) |
| 隨機種子 | 42(所有 ML 模型,確保可重現) |
11 個特徵(按類別) :
- GARCH 類 :GARCH(1,1) 條件方差 、GARCH/VIX² 比值
- VIX 類 :
- 收益率歷史 :、、YZ range
- 滾動統計 :20 日滾動方差
ML 模型配置 :
| 模型 | 架構/設定 | 超參數 |
|---|---|---|
| MLP | 2 層 (32, 16),ReLU,Adam | max_iter=500,early_stopping |
| Ridge | 線性迴歸加 正則化 | |
| Random Forest | 樹集成 | 100 棵樹,max_depth=5 |
評估指標遵循 Patton (2011):QLIKE 為主(proxy-robust),輔以 MSE 與 Spearman 。模型間差異以 DM test 驗證,Harvey et al. (2016) 為顯著性門檻。
核心發現
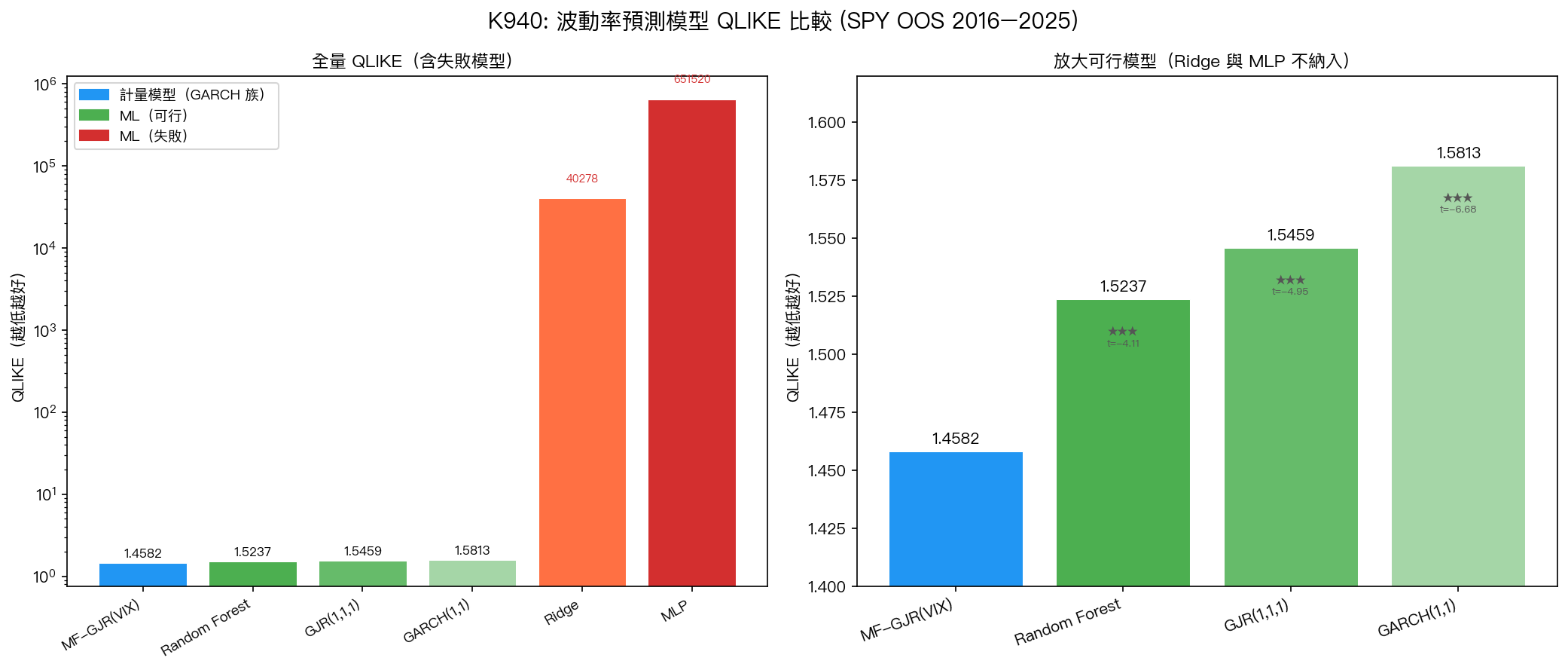
發現一:計量模型全面勝出,MF-GJR(VIX) 仍為最佳
完整結果表 (DM test vs MF-GJR(VIX),Harvey 為顯著):
| 模型 | QLIKE | MSE | Spearman | DM -stat | 顯著 |
|---|---|---|---|---|---|
| MF-GJR(VIX) | 1.4582 | $2.13 \times 10^{-7}$ | 0.4573 | — | 基準 |
| Random Forest | 1.5237 | $2.20 \times 10^{-7}$ | 0.4212 | -4.11 | ★★★ |
| GJR(1,1,1) | 1.5459 | $2.09 \times 10^{-7}$ | 0.4177 | -4.95 | ★★★ |
| GARCH(1,1) | 1.5813 | $2.15 \times 10^{-7}$ | 0.3833 | -6.68 | ★★★ |
| Ridge | 40,278 | $2.10 \times 10^{-7}$ | 0.3995 | -3.33 | ★★★ |
| MLP(32,16) | 651,520 | $1.21 \times 10^{-3}$ | 0.0735 | -4.46 | ★★★ |
★★★ = Harvey ,統計顯著劣於 MF-GJR(VIX)。
所有模型均顯著不如 MF-GJR(VIX), 包括所有三個 ML 模型 。
發現二:MLP 災難性失敗,分佈診斷揭示原因
MLP 的 QLIKE = 651,520,比 MF-GJR 高出 446,737 倍 。更關鍵的是 MSE = $1.21 \times 10^{-3}$,比其他所有模型高出 5,780 倍 ——代表 MLP 的預測值完全失控。
根源診斷:QLIKE 的定義為
QLIKE 對低估懲罰極重 (當 ,)。日頻 分佈的峰態係數高達 347,意味著存在少數極端觀測(如 2020/3 COVID 崩盤期)。
MLP 在這些極端樣本上的梯度()遠大於正常樣本,導致:
- 梯度爆炸 :Adam 優化器雖有自適應學習率,但 kurtosis=347 仍造成不穩定
- Early stopping 過早 :極端樣本出現在驗證集時觸發停止,損壞最後收斂的權重
- 特徵標準化不足 :儘管有 StandardScaler, 在標準化後仍有極端值
發現三:Ridge 的 QLIKE 爆炸,線性模型的致命弱點
Ridge 的 QLIKE = 40,278,但 MSE 卻接近最佳($2.10 \times 10^{-7}$)。這個矛盾現象揭示了一個重要的方法論問題: MSE 和 QLIKE 衡量的是根本不同的東西 。
Ridge 是線性模型,其預測值
當市場平靜時,某些特徵組合可能產生 接近零甚至負值 的預測()。由於 QLIKE 包含 項,極小的 會讓這個比率爆炸。
GARCH 族模型天然避免此問題,其遞迴結構()保證 ,且 的高持續性確保不會跌至零附近。
發現四:Random Forest 是唯一可行的 ML 模型
RF 的 QLIKE = 1.5237 落在 GJR 和 GARCH 之間,Spearman = 0.4212 也接近 GJR(0.4177)。RF 之所以可行,原因在於:
- 樹結構的天然正性 :RF 預測是訓練目標的加權平均,訓練目標全為正值(),因此預測值也保持非負
- 對極端值的魯棒性 :max_depth=5 限制每棵樹,避免對極端觀測過擬合
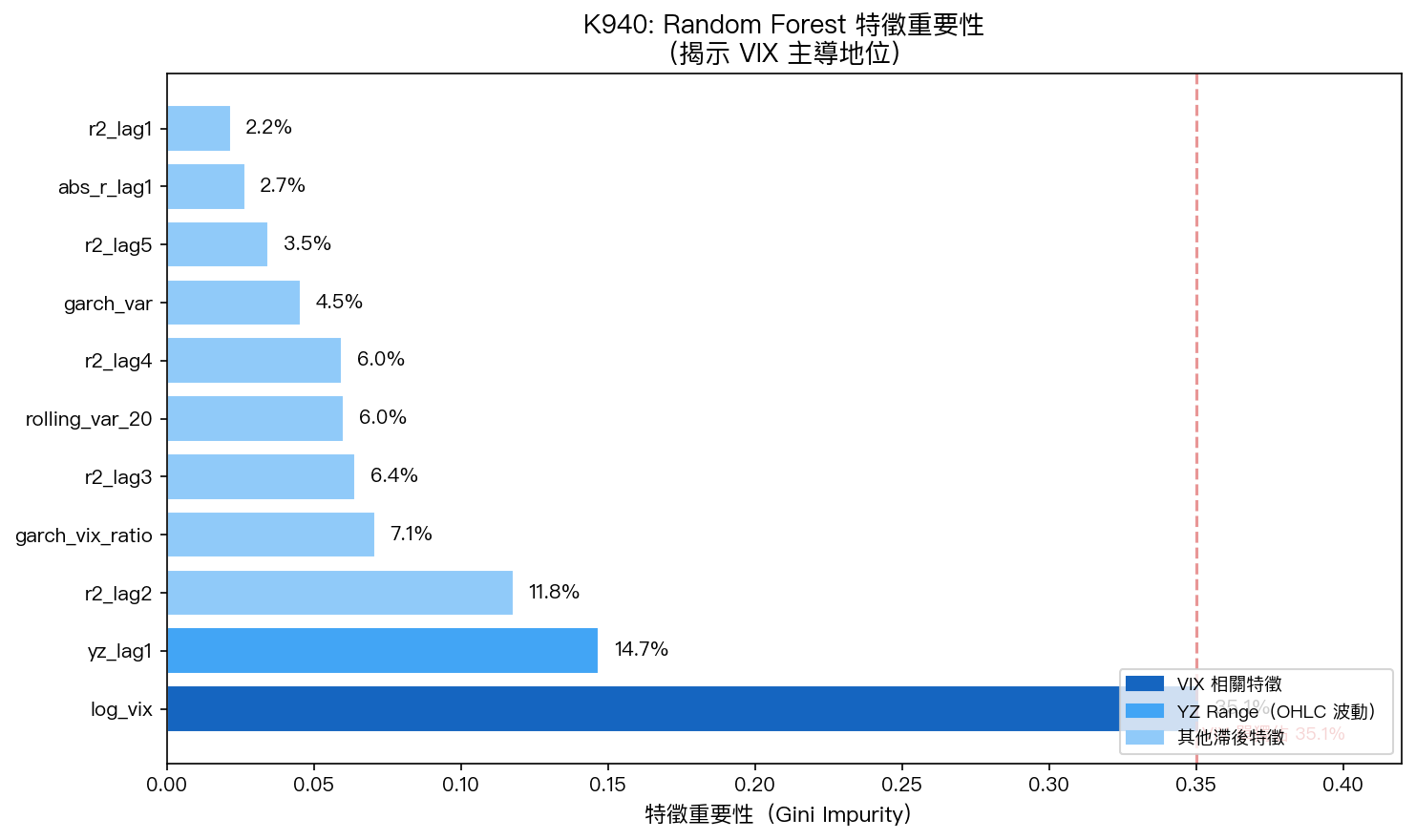
發現五:VIX 主導地位的結構確認
RF 的特徵重要性(Gini impurity):
| 特徵 | 重要性 | 說明 |
|---|---|---|
| 35.1% | 市場隱含波動率 | |
| 14.7% | OHLC 日內波動估計量 | |
| 11.8% | 二日前的波動衝擊 | |
| GARCH/VIX² ratio | 7.1% | 計量模型殘差 vs 市場預期 |
這個結果從 ML 的角度驗證了 MF-GJR(VIX) 的設計理念。MF-GJR 將方差分解為:
其中長期成分 直接編碼了 VIX 對波動率的乘法影響。RF 發現 VIX 解釋了 35% 的預測力,而 MF-GJR 用參數化方式精確捕捉了這個關係——ML 沒有什麼「額外的非線性」可以發現。
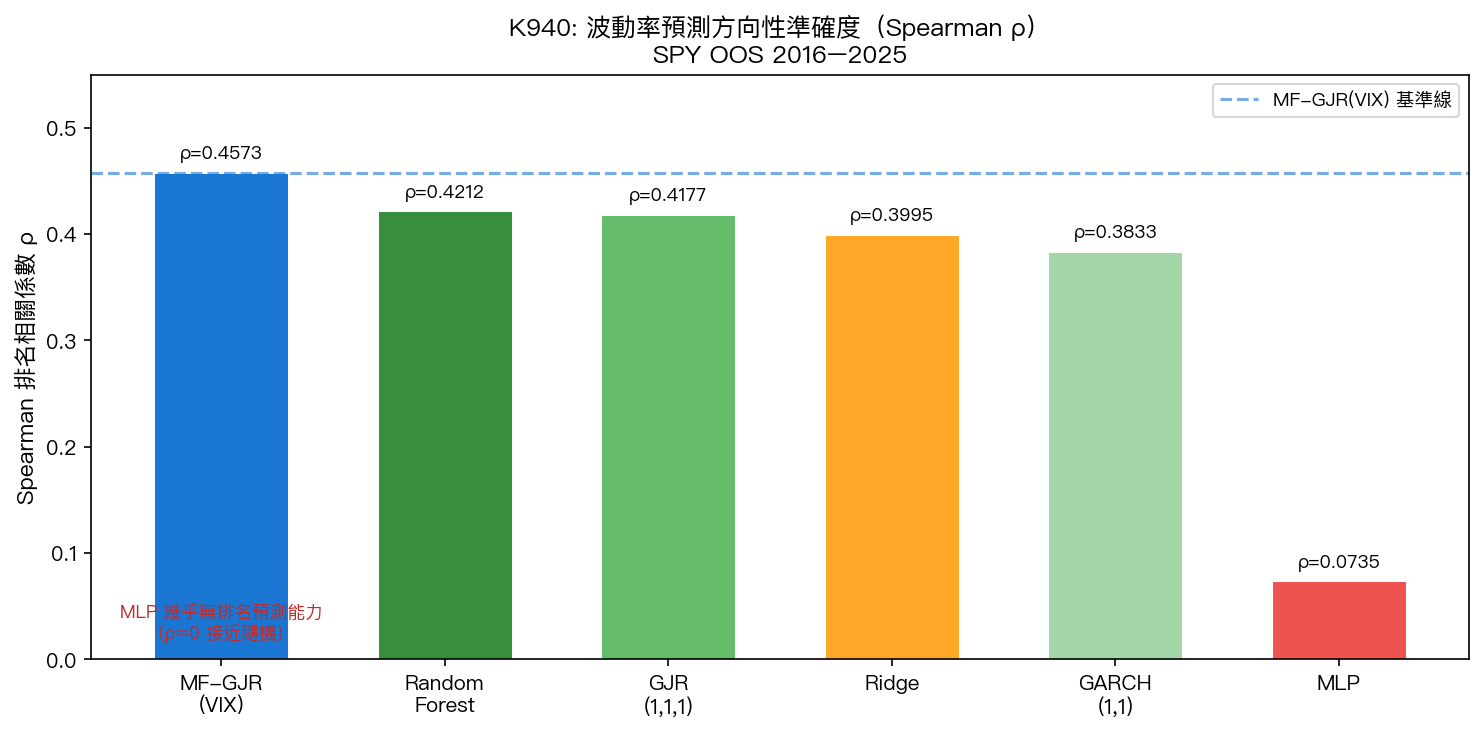
發現六:方向性預測(Spearman ρ)同樣確認排序
Spearman 是分佈無關的排名相關係數,不受 QLIKE 的極端值影響。即便在這個更穩健的指標上:
- MF-GJR(VIX):(最高)
- Random Forest:(ML 最佳,仍不勝)
- MLP:(接近隨機猜測)
MLP 在所有三個評估指標(QLIKE、MSE、Spearman)上均失敗,確認此並非 QLIKE 的偶然懲罰。
實務意義
對波動率預測研究者 :
- 在日頻數據上, 不應期待基本 MLP 優於計量模型 。如果要試 ML,Random Forest(有深度限制)是比神經網路更穩健的起點。
- 評估指標的選擇至關重要 :Ridge 在 MSE 上表現良好,若只看 MSE 會得出「ML 可行」的錯誤結論。應優先使用 QLIKE(Patton 2011)。
- 特徵工程的邊界 :RF 特徵重要性是驗證計量模型設計的工具,當 ML 發現的重要特徵與計量模型的結構相符,代表計量模型已「學到」了正確的非線性。
對一般投資者 :
- 波動率預測的技術前沿並非「越複雜越好」。配備市場恐慌指數(VIX)的 GARCH 模型在 10 年 OOS 期間持續勝過 AI 神經網路。結構化的金融知識(「波動率有長期和短期成分」)比暴力搜索非線性更有效。
結論
K940 提供了計量模型 vs ML 的第一個正面比較。結論:
- MF-GJR(VIX) 繼續保持最佳地位 (QLIKE=1.4582,DM 勝所有對手)
- MLP 神經網路災難性失敗 (QLIKE=651,520)—— 的 kurtosis=347 使梯度不穩,early stopping 無法補救
- Ridge 的 QLIKE 爆炸 (40,278),線性模型可能預測零附近方差,QLIKE 懲罰極重
- Random Forest 是唯一可行的 ML (QLIKE=1.5237),但仍顯著不如 MF-GJR
- RF 特徵重要性確認 VIX 主導 (35.1%)——MF-GJR 的乘法結構已完整捕捉此非線性
限制 :本實驗使用基本 ML 架構(2 層 MLP、淺層 RF)。更深的架構(LSTM、Transformer)或以 realized variance 作為預測目標可能得出不同結論。未來研究可探索:(1) HAR-RV + ML 在 5 分鐘 RV target 上的比較、(2) 更大規模超參數調整(HPO)、(3) 多資產驗證。
實驗腳本: experiments/k940/k940.py,數據來源:yfinance (SPY, ^VIX),OOS 2016-2025
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊