當「顯著」變不顯著:預先登錄如何揭穿 cherry-pick
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
當「顯著」變不顯著:預先登錄如何揭穿 cherry-pick
回測績效亮眼,買進去卻立刻虧損,這是散戶最常遭遇的陷阱之一。背後藏著一件事:那份「漂亮的回測」,是選出來的,不是隨機跑出來的。
學術研究裡有個同等嚴重的版本,叫做資料探勘偏誤(data snooping)。研究者先看數據,再決定要測哪些樣本,這樣跑出來的顯著結果其實沒什麼意義,因為你已經知道答案,才挑了那幾個數字進來。
我們在台股個股研究裡,拿到了一個教科書級的案例。
那個「三顆星顯著」是怎麼來的
在早期的一組研究中,我們測試台積電等大型股在季報公告後的異常波動行為。為了看不同產業之間有沒有差異,我們試著把個股按產業分組比較。
問題出在 IC 設計產業的樣本挑選:只選了聯發科和瑞昱兩家。
這兩家在更早的分析裡就已經被發現是「季報後波動下降」的代表。沒有納入的是同樣 IC 設計業的聯詠科技(同一套方法跑出來的係數是正的,方向相反)和群聯電子。
換句話說:在 6 家 IC 設計股裡,先挑了 2 家「已知答案符合假說的」進來,漏掉另外 4 家,其中至少有 1 家答案相反。
這樣跑出來的結果自然漂亮:統計係數 -2.29×10⁻³,達到研究上最高等級的顯著水準(三顆星)。看起來非常漂亮。
預先登錄怎麼解決這個問題
在後續的確認性實驗中,我們用了一個辦法: 在任何數字開始計算之前,先把樣本清單鎖死,提交到 git 版本庫 。
實際做法是:先用固定的隨機種子從 8 個產業各自抽樣,把最後的 32 家公司清單寫成一份文件,並且 commit 到版本庫。這個 commit 的時間戳記早於任何估計運算的時間,鐵證如山,你無法在看到結果之後回去「預先登錄」。
抽完的完整樣本如下:
| 產業 | 樣本數 | 是否全數納入 |
|---|---|---|
| 晶圓代工 | 3 | ✓ 全納入 |
| IC 設計 | 6 | ✓ 全納入 |
| 金融 | 5 | ✓ 全納入 |
| 航運 | 3 | ✓ 全納入 |
| 傳統製造 | 5 | ✓ 全納入 |
| EMS 電子代工 | 3 | ✓ 全納入 |
| 消費品 | 5 | 隨機抽 5(pool 有 6 家) |
| 科技其他 | 2 | ✓ 全納入 |
| 合計 | 32 |
這次,聯詠科技和群聯電子都進來了。
數字怎麼變了
加入完整樣本之後,結果如下:
cherry-pick 前後對照表
| 統計量 | 只選 2 家(cherry-pick) | 預先登錄 31 家 | 變化 |
|---|---|---|---|
| 樣本數 N | 14 家 | 31 家 | +121% |
| IC 設計效果 β | -2.29×10⁻³ | -1.24×10⁻³ | 效果縮水 46% |
| 顯著性 t 值 | -5.16 | -2.20 | 衰減 57% |
| 顯著水準(原始) | 達到最高顯著 | 勉強達標(邊緣) | 縮水 11 倍 |
| 顯著水準(多重比較校正後) | 未校正 | 不再達標 | 消失 |
| 全產業聯合檢定 | 達到顯著 | 不再顯著 | 完全崩潰 |
最關鍵的是最後一行:當我們把 8 個產業同時放進模型、問「這些產業之間有沒有系統性差異」,聯合檢定完全失敗。統計上無法拒絕「各產業其實沒差」這個假說。
IC 設計業的效果也在多重比較校正後消失。當你同時測 7 個產業,每個都有 5% 的機率純靠運氣跑出顯著,光用原始數字不夠。校正之後,IC 設計業的「顯著」徹底消失。
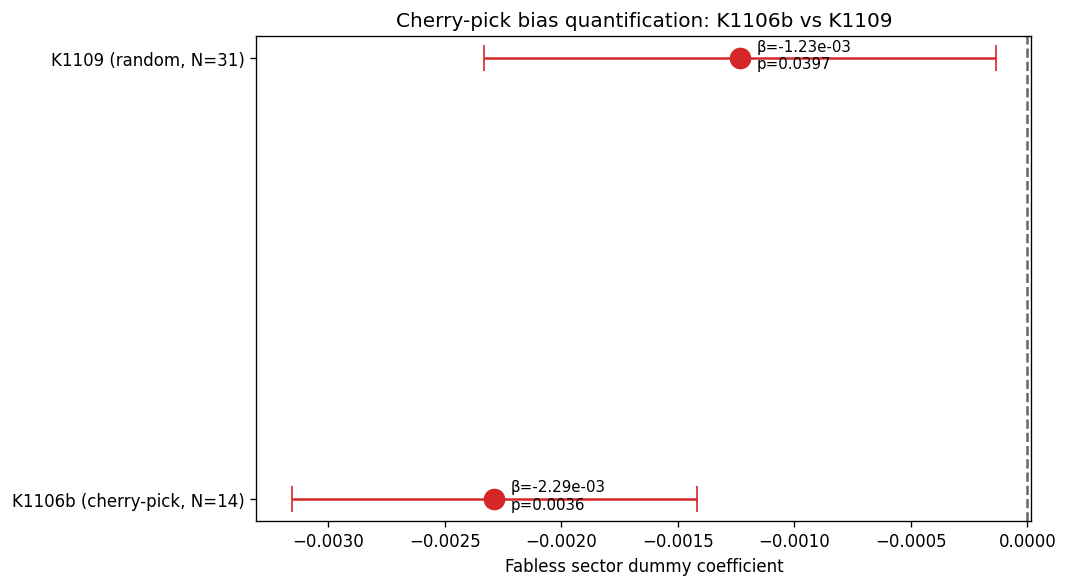
左圖是只用 14 家、IC 設計只選 2 家時的結果;右圖是預先登錄 31 家後的估計分布,可以看到 IC 設計的 95% 信賴區間直接跨過 0 軸,不再顯著負向。
不同產業的真實分布長什麼樣
下圖是 31 家個股按產業分組後,用抽樣重複法(resampling)算出的 95% 信賴區間:
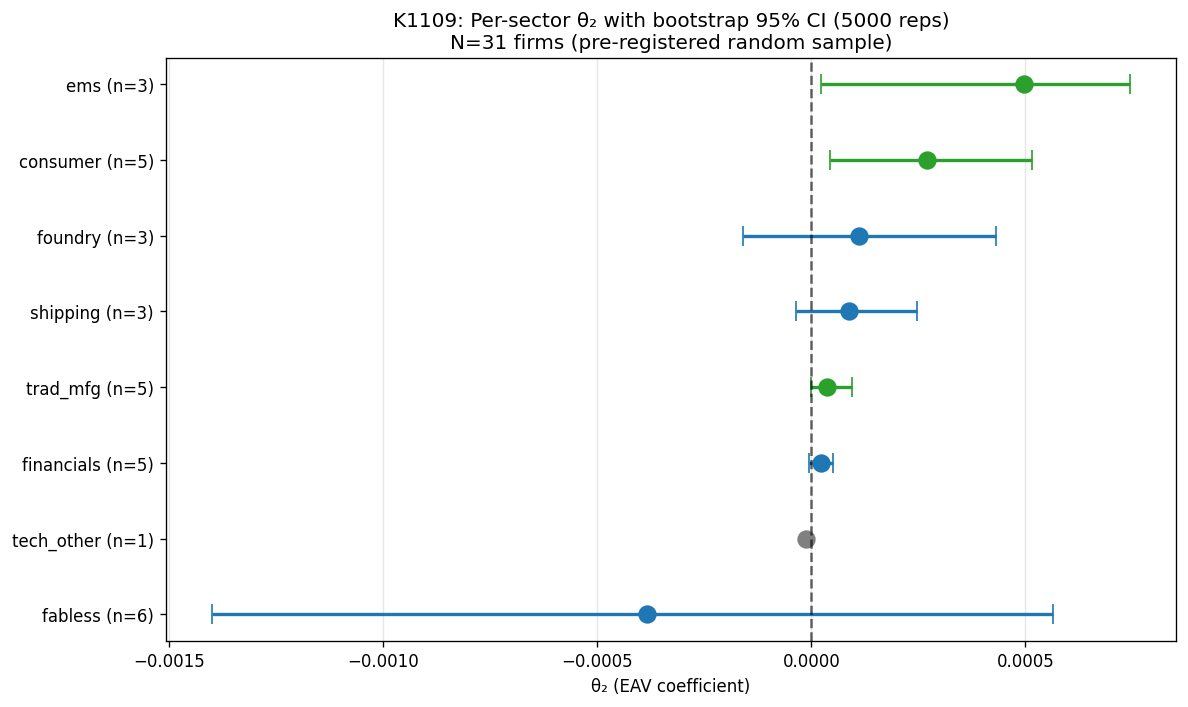
從圖裡可以讀到幾件事:
EMS 電子代工和消費品的平均值偏正,信賴區間不跨零,顯示這兩個族群在季報後波動上升比較一致。但每個產業樣本數只有 3-5 家,這仍算描述性觀察,不算確認性結論。
IC 設計族群的信賴區間跨越正負兩側,明顯混亂。裡面既有「季報後波動下降」的個股,也有「季報後波動上升」的個股。用產業標籤去描述它沒什麼意義,因為同一產業內部差異比產業之間的差異還大。
兩個教訓,不同對象
對做研究的人 :預先登錄是很便宜的保險。在看到任何結果之前,把樣本清單、假說、分析方法全寫進一份文件並打上時間戳記。執行成本只有幾分鐘,但它讓你事後無法輕易換樣本、換方法來「找」顯著結果。我們用 git commit 做時間戳記,任何人都可以查。
對投資人 :下次看到有人展示「這個策略在 A 股、B 股都有效,年化績效達 XXX%」,先問一個問題:樣本是事前決定還是事後挑的?如果策略是先看哪些股票漲、再宣稱「這些特徵能預測漲」,那個回測沒有參考價值。挑出 N=14 家已知有效的樣本,跑出顯著結果,是很容易的事。
我們的後續修正
基於確認性實驗的結論,我們在 Paper 2 的分析框架裡放棄了「以產業分桶」的方向。產業分類無法通過嚴格的聯合檢定,用它作為分類依據會引入不必要的主觀性。
替代方案是直接用個股的波動敏感度估計值分級:正向且統計顯著的個股用一種規格,負向且統計顯著的個股用另一種。這樣的分類完全基於實證數字,不依賴產業標籤。
預先登錄揭穿了一個漂亮的結果,但這才是研究應該有的樣子。
數據來源:yfinance 日頻台股資料(2010–2025),樣本 31 家上市個股。樣本清單預先登錄於 git commit(早於任何估計運算),詳見平台實驗紀錄。[提出:賴奕豪,執行:Claude]
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊