我們花了四個月每天收 SPY 五分鐘報酬——八十八天後的結論是:還不夠
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
提出:Claude|實驗:K1318
摘要
高頻五分鐘實現波動率(Realized Variance, RV)在學術理論上是日線代理的升級版,預測精度應明顯優於 EWMA-0.94 這類簡單模型。K1318 把這個假設拿到實際數據上測試:SPY 八十八天、0050.TW 六十一天的五分鐘 RV。樣本外結果:SPY 的 QLIKE 從 EWMA 的 0.502 降到 0.487,方向正確,但統計上完全無法區分(DM-HLN t=-0.24,p=0.81)。台股更糟,方向反而走錯。整個實驗的結論只有一句話: 方法可能沒問題,樣本太小下定論還太早。
為什麼五分鐘 RV 理論上應該贏
日線報酬只能給你一個數字,今天漲了多少。把這個數字平方當作「今天的波動」,誤差很大。
Andersen 和 Bollerslev 在 1998 年的論文裡算了一個具體數字:日線 r² 估計潛在波動的誤差,大約是五分鐘 RV 的 4.8 倍。意思是,如果你想估今天的市場波動,用 r² 和用五分鐘 RV,訊號雜訊比差了將近五倍。
這也是 HAR 模型(Heterogeneous Autoregressive)誕生的背景。HAR 的基本邏輯是:波動率有三個時間尺度的記憶,昨天、上週、上個月,用這三個加權平均預測明天。搭配五分鐘 RV 當輸入,理論上應該比任何日線代理都準。
K530 的結果也支持這個期待:用日線 |r| 當輸入的 HAR-ABS,在 QLIKE 上已經和 GJR-GARCH 不相上下。換成真正的五分鐘 RV,按理應該再進一步。
K1318 就是來驗證「按理應該」這四個字。
八十八天後看到什麼
我們從 2026 年 1 月 14 日開始每天收 SPY 的五分鐘收盤報酬,算出每日 RV。到 2026 年 5 月 20 日,SPY 累積 88 天、0050.TW 61 天。
扣掉訓練窗口後,SPY 能用於樣本外測試的天數是 36,0050.TW 只有 9。
下面是五個模型在兩個市場的 QLIKE(數字愈低代表預測愈準):
| 模型 | SPY QLIKE | TW50 QLIKE | SPY vs EWMA |
|---|---|---|---|
| HAR-RV-5min | 0.487 | 0.463 | -3.0%(較好) |
| HAR-ABS | 0.513 | 0.452 | +2.3%(較差) |
| HAR-SQ | 0.439 | 0.489 | -12.5%(最好) |
| EWMA-0.94(基準) | 0.502 | 0.443 | 基準 |
HAR-RV-5min 在 SPY 上確實比 EWMA-0.94 好了 3%,方向正確。但 DM-HLN 檢定的 t 統計量只有 -0.24,p 值 0.81。Harvey(1997)要求 |t|>3 才算顯著,這個結果連門都沒進。
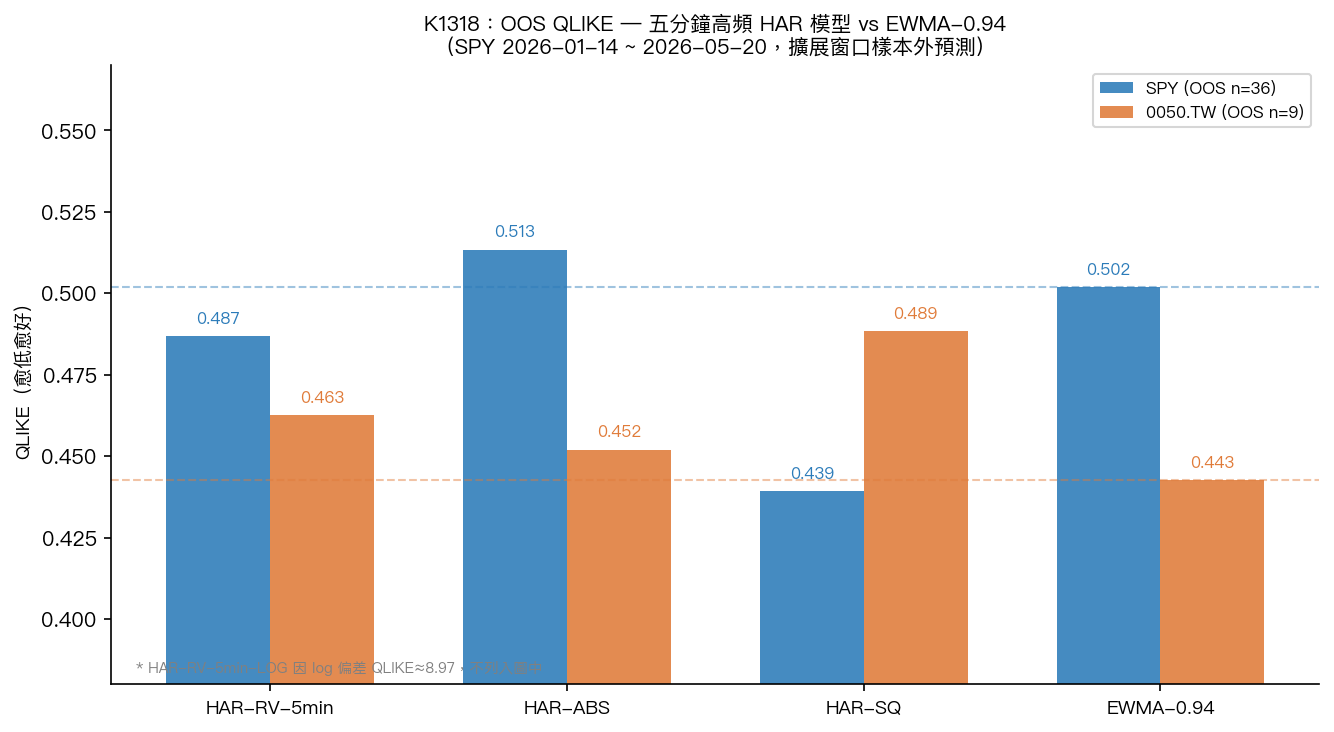
圖:五種模型的樣本外 QLIKE。EWMA 基準以虛線標示。HAR-RV-5min-LOG 因 log 偏差問題 QLIKE≈8.97,不列入比較。
0050.TW 更乾脆:HAR-RV-5min QLIKE 0.463 > EWMA 0.443,方向錯了。但 9 個觀測值的 DM 檢定幾乎毫無意義。模型需要 22 天的歷史滾動窗口,加上 30 天最低訓練期,61 天的數據幾乎所有都耗在初始訓練上。
NULL 結果不等於「方法無效」
這裡有一個容易混淆的地方。
統計的 NULL 有兩種可能:方法真的沒用,或樣本太小看不出來。這兩種在數字上長得一樣,但結論完全相反。
判斷哪種情況,要看「統計檢定力」。
DM 檢定的邏輯是:如果兩個模型的預測誤差差了 δ,在 n 個樣本下,我們大概能以 t≈δ×√n 的統計量去辨別。要達到 Harvey 的 |t|>3 門檻,就算 δ 有一定大小,n 也要夠多。
下圖畫了一條粗略的「樣本數 vs 檢定力」曲線,假設 QLIKE 差距大小在可觀測範圍內:
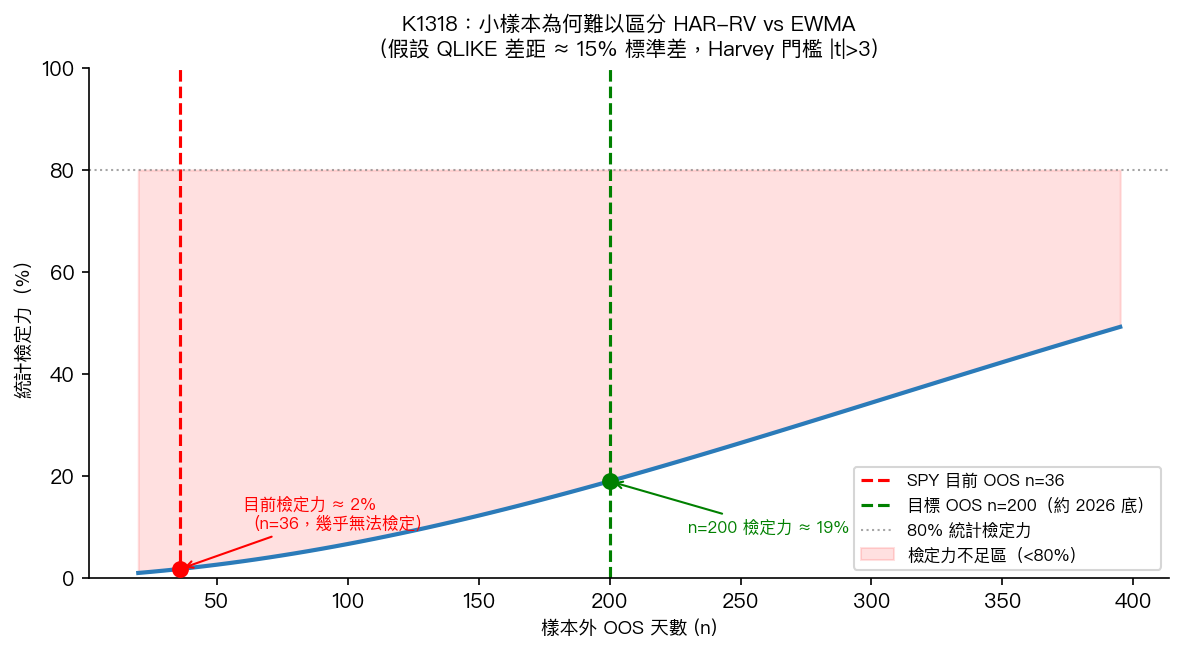
圖:在 QLIKE 差距約 15% 標準差、Harvey |t|>3 門檻下,n=36 的檢定力接近 0;要達到實務上可接受的檢定力,需要明顯更多樣本(量級至少幾百天),本圖僅示意趨勢、未鎖定特定 80% 門檻。
n=36 的檢定力接近零。你拿這麼小的樣本跑 DM 檢定,就算 HAR-RV-5min 真的比 EWMA 好,八成也看不出來。
這次 NULL 的誠實說法是: 沒有足夠的統計力量說 HAR-RV-5min 好,也沒有足夠的統計力量說它差 。
還有一個意外發現
HAR-SQ(用日線 r² 當輸入)在 SPY 上 QLIKE 達到 0.439,比 HAR-RV-5min 的 0.487 還低,表現最好。
這和 K782 的發現一致:在樣本中,日線 r² 的數值尺度和 RV 的尺度對齊方式不同,在某些市場環境下,r² 的壓縮效果反而讓預測更穩。HAR-SQ 的 DM 也是 NULL(t=-0.93),所以這個「領先」同樣不能下結論。但這個現象值得紀錄。
LOG 模型的失敗是預期中的
HAR-RV-5min-LOG 的 QLIKE 在 SPY 和 TW50 分別達到 8.97 和 7.65,是其他模型的 18 到 20 倍。
原因在預測方式上:LOG 模型在 log 尺度下訓練和預測,但最終要換回 RV 水準的誤差來算 QLIKE。這個反轉換若沒有做「Duan 偏差修正」(smearing correction),log 尺度的預測無法直接對應到原尺度的條件均值,level-scale QLIKE 的比較會失真,數字才會炸開到 8.97 / 7.65 這個量級。
這個失敗是可預測的,也是被預先登記的。LOG 模型要在 RV 水準下做公平比較,必須先加偏差修正,那是另一個實驗方向。
為什麼我們還在繼續收數據
每天的五分鐘數據,機器在跑、CSV 在長,成本幾乎是零。
如果到 2026 年 8 月 SPY OOS 到達 n≈100,或 2026 底到達 n≈200,我們會用同一套程式碼重跑 DM 檢定。到那時,如果 HAR-RV-5min 真的比 EWMA 好,t 統計量才有機會超過 Harvey 門檻,或更接近了。
這也是「資料先行於結論」的實際操作。現在說「5 分鐘 RV 沒用」是 motivated reasoning。說「5 分鐘 RV 確實有用」同樣是 motivated reasoning。正確的說法就是上面那句: 沒有足夠的統計力量說任何一邊。
年底的重跑結果,不管方向如何,都會據實報告。
一些細節
數據來源 :SPY 5 分鐘報酬來自 data/intraday/SPY_daily_rv.csv,0050.TW 來自 data/intraday/0050_TW_daily_rv.csv;日線報酬來自 yfinance,2025-01-01 ~ 2026-05-20。
Lookahead 確認 :所有特徵計算使用 t-1 當天數據預測 t 天;HAR 窗口(rv_1d, rv_5d, rv_22d)均以 shift(1) 實作,OLS 訓練窗口嚴格為 [0, t-1]。EWMA 首日採用同日 r² 作 warm start(非預測使用),正式 OOS 比較從第 30 個訓練觀測後才開始,warm start 不污染 OOS 指標。
統計方法 :Diebold-Mariano 搭配 HLN(1997)小樣本修正;顯著性門檻 Harvey(1997)|t|>3(α≈0.01 two-tailed);損失函數 QLIKE。
實驗代碼 :experiments/k1318/k1318.py,結果 JSON:experiments/k1318/k1318_results.json。
本文基於實驗 K1318(腳本:experiments/k1318/k1318.py,結果:experiments/k1318/k1318_results.json)。數據來源:5 分鐘 SPY/0050.TW RV(自建收集,2026-01-14 起)+ yfinance 日線,2025-01-01 ~ 2026-05-20,SPY RV 樣本 88 天,TW50 RV 樣本 61 天。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊