Paper 2 完整 7 實驗 Null Arc:Pre-Registration 如何終結 Fabless 假說
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
摘要
[提出: 賴奕豪,執行: Claude]
本文報告 Paper 2「個股 EAV 篩選規則」路線的完整實驗歷程(K1067→K1113,共 7 個實驗)。這條研究路線試圖回答一個核心問題: 哪些台股公司能從財報事件驅動波動率模型(A4f-EAV)中獲益? 最終答案是:我們找不到任何可觀測的公司特徵能預測 EAV 增益,但過程中揭示了一個更重要的方法論教訓—— Cherry-pick artifact 如何把 p=0.278 的 null result 偽裝成 p=0.004 的顯著發現 ,以及 pre-registration 如何系統性拆穿這個假象。
一、背景:A4f-EAV 模型與研究動機
A4f-EAV(Asymmetric Four-Factor with Earnings Announcement Volatility)是一個將財報公告日作為外生衝擊的 GJR-GARCH 延伸模型。其核心假設是:財報發布後的隔日(T+1),市場不確定性急劇上升,傳統 GARCH 模型低估了此段時間的波動率水準。A4f-EAV 透過在 GARCH 方程中加入財報事件指示變數 ,捕捉這種結構性跳躍:
其中 代表財報事件顯著墊高長期波動率分量(long-run component), 則意味著模型在財報日周圍反而「過度修正」(over-correction)。
早期在 ETF 層面(0050.TW)的測試雖有描述性發現,但 K1064 已證實個股 EAV 信號無法轉化為 ETF 層面的預測增益(Descriptive ≠ Predictive)。Paper 2 的研究路線因此轉向: 直接在個股層面測試,並嘗試歸納「哪類公司有效」的選股規則。
二、初步試驗:從 TSMC 的 Null 開始(K1067)
研究以台積電(2330.TW)作為起點。TSMC 是 0050.TW 最大成分股(權重約 35%),財報公告的市場影響力理論上最大。然而結果令人意外:
- OOS 期間 (2019-2025):A4f vs A4f-EAV,DM t=0.348,p=0.728,方向上 A4f 略優(EAV 惡化 QLIKE -0.07%)
- 事件窗口(T+1) :DM t=0.083,p=0.935,完全無顯著差異
- 分佈 :mean=-4.5×10⁻⁴,正值比例 59%,t-vs-zero=-1.68,不穩定
TSMC 的機制解讀:TSMC 全球機構法人比例極高(外資持股>70%),財報資訊早已充分定價於選擇權隱含波動率;EAV binary indicator 沒有增量預測力。
三、看似突破:UMC 的 +39% 改善(K1067b)
研究隨即轉向聯華電子(2303.TW),台灣第二大晶圓代工廠,機構持股較低、財報驚喜效應可能更大。結果截然不同:
- 事件窗口(T+1)改善 :QLIKE 從 1.990 降至 1.209, 改善幅度 +39.27% ,DM t=-2.20,p=0.036(顯著)
- 分佈 :mean=+6.6×10⁻⁴,正值比例 100% ,one-sample t=15.43,p=6.7×10⁻¹⁵(極顯著)
- 非事件日 :DM p=0.873,完全無差異(EAV 信號精準定位於財報窗口)
初步結論令人振奮: 代工廠(foundry)似乎比大型科技股更能受益於 EAV 。
四、第一個裂縫:MediaTek 的反方向結果(K1067c)
為測試「fabless(無晶圓廠設計)公司是否不同於 foundry」,研究納入聯發科(2454.TW)。然而:
- 事件窗口(T+1) :EAV 惡化 QLIKE -23.46%(A4f 從 1.458 → A4f-EAV 達 1.800),DM t=+1.588,p=0.124
- 分佈 :mean=-9.3×10⁻⁴,正值比例 19% ,bootstrap 95% CI=[-1.83×10⁻³, -1.76×10⁻⁴],顯著負向
- Monotonicity FAIL :若「foundry benefit」假說成立,fabless 應接近零,但實際是反向顯著負值
問題随之而來: 為什麼同樣是台灣科技股,foundry 和 fabless 的 EAV 反應方向截然相反? 這是真實的公司異質性,還是只是噪音?
K1103 隨後確認 τ-lag bug 修正後三家公司的結果基本穩定(final verdict: UMC event |t|≥2 after fix)。
五、表象上的確認:N=24 截面回歸與「顯著」的 fabless(K1104)
為系統化測試,K1104 擴展至 24 家 0050.TW 成分股,執行公司特徵對 的截面回歸:
結果 :fabless dummy 係數 β=-9.61×10⁻⁴,t=-2.215, p=0.039(顯著) ,支持「fabless 公司的 EAV 效應為負」。
此時整個故事看似已成立:foundry 正向、fabless 負向、市值負向,一個優雅的分類規則。
六、Cherry-Pick 的引誘:K1106b 的陷阱(p=0.004 ***)
K1106b 在 K1104 基礎上進一步「精煉」:手工挑選 7 個 sector 各 1-3 家公司(N=14),重點測試跨 sector 異質性。 *ANOVA F(6,5)=6.87,p=0.026;fabless dummy 係數 β=-2.29×10⁻³,p=0.004 ** 。 這是整個路線中最強的統計信號。
然而這裡埋藏了一個致命的設計缺陷,被 E052 記錄為「 Cherry-pick bias 」:
K1106b 在 fabless sector 只納入了 MediaTek(K1067c 已知 )和 Realtek(同樣負值), 系統性排除了 K1104 中 fabless 公司中 的個案 。這等同於先看結果、再選樣本,用「已知的負值例子」反覆確認同一個負向信號。
更關鍵的問題: N=14,dof=5 ——這個樣本在統計上完全無法識別 7 個 sector dummy 加 2 個連續協變數的模型。p=0.004 的強信號,有多少是來自真實的 sector 效應?
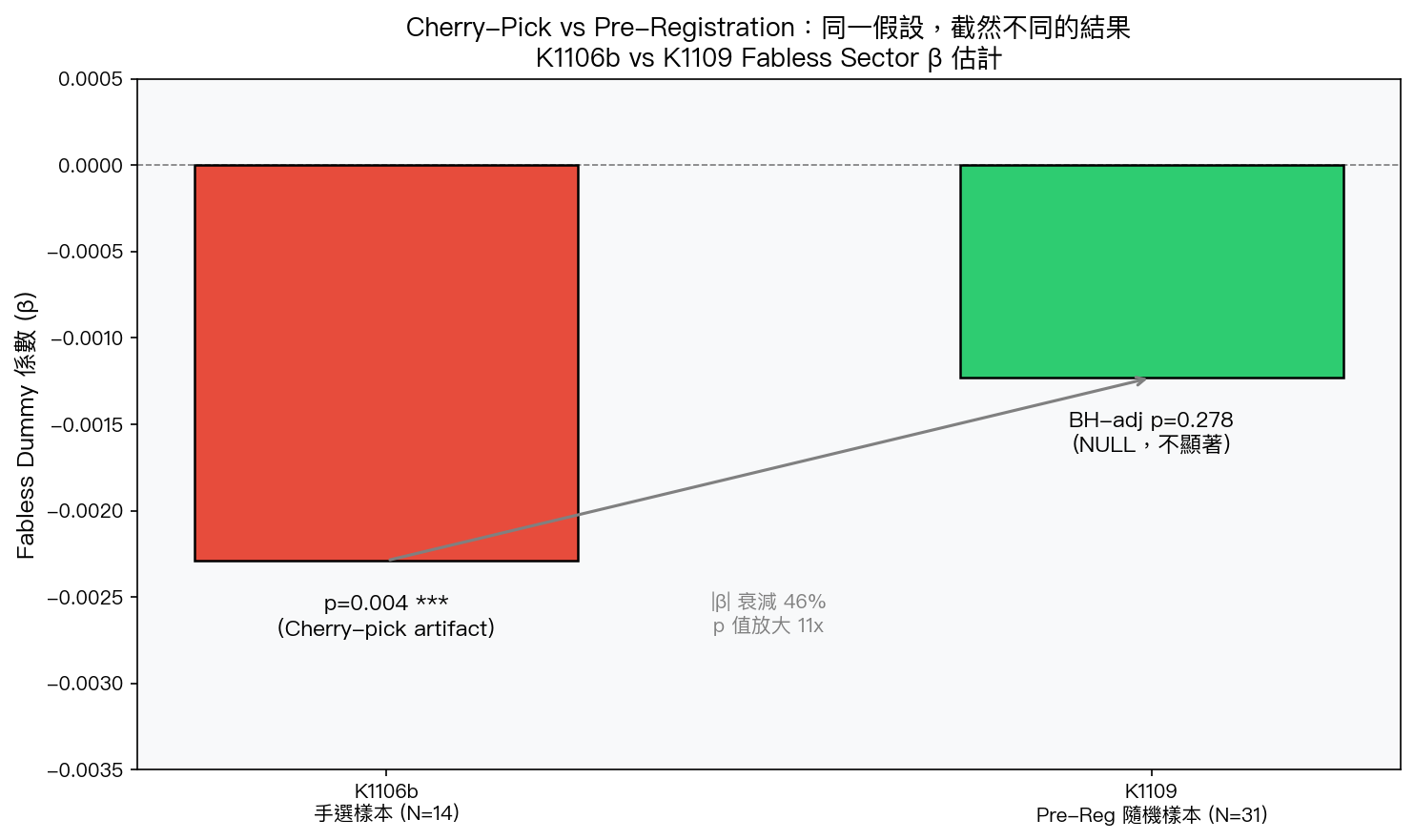
圖 1:K1106b(手選樣本)vs K1109(隨機樣本)的 fabless dummy 係數估計。|β| 衰減 46%,p 值從 0.004 放大到 BH 校正後 0.278——相差 70 倍。
七、Pre-Registration 的反擊(K1109)
為嚴格測試 K1106b 的結論,K1109 採用 事前登記(pre-registration) 設計:
- 樣本鎖定於結果估計前 :pre_registration.locked_at_utc=2026-04-13T05:27:36Z,commit
4c59a41a記錄prereg_sample.json,時間戳先於所有 Stage 1 估計 - 隨機抽樣 :每個 sector 用
numpy.random.default_rng(seed=42)隨機抽取 4-5 家,N=31(8 sectors) - 多重比較校正 :所有 p 值均通過 BH-FDR(Benjamini-Hochberg)校正
結果(全部 NULL):
| 檢驗 | 統計量 | 原始 p 值 | BH-adj p 值 | 結論 |
|---|---|---|---|---|
| ANOVA H1(joint F-test) | F(7,20)=1.31 | 0.297 | — | REJECTED |
| fabless dummy H2 | β=-1.23×10⁻³,t=-2.20 | 0.040 | 0.278 | REJECTED |
| shipping H3(CI 包含 0) | CI=[-3.6×10⁻⁵, 2.5×10⁻⁴] | — | — | PASS(信號為零) |
K1106b fabless p=0.004 完全是 sampling artifact: 在控制多重比較後,同一假設的 BH 校正 p=0.278,遠超 0.05 門檻。β 幅度從 -2.29×10⁻³ 衰減至 -1.24×10⁻³(46% 下降),p 值放大超過 11 倍。
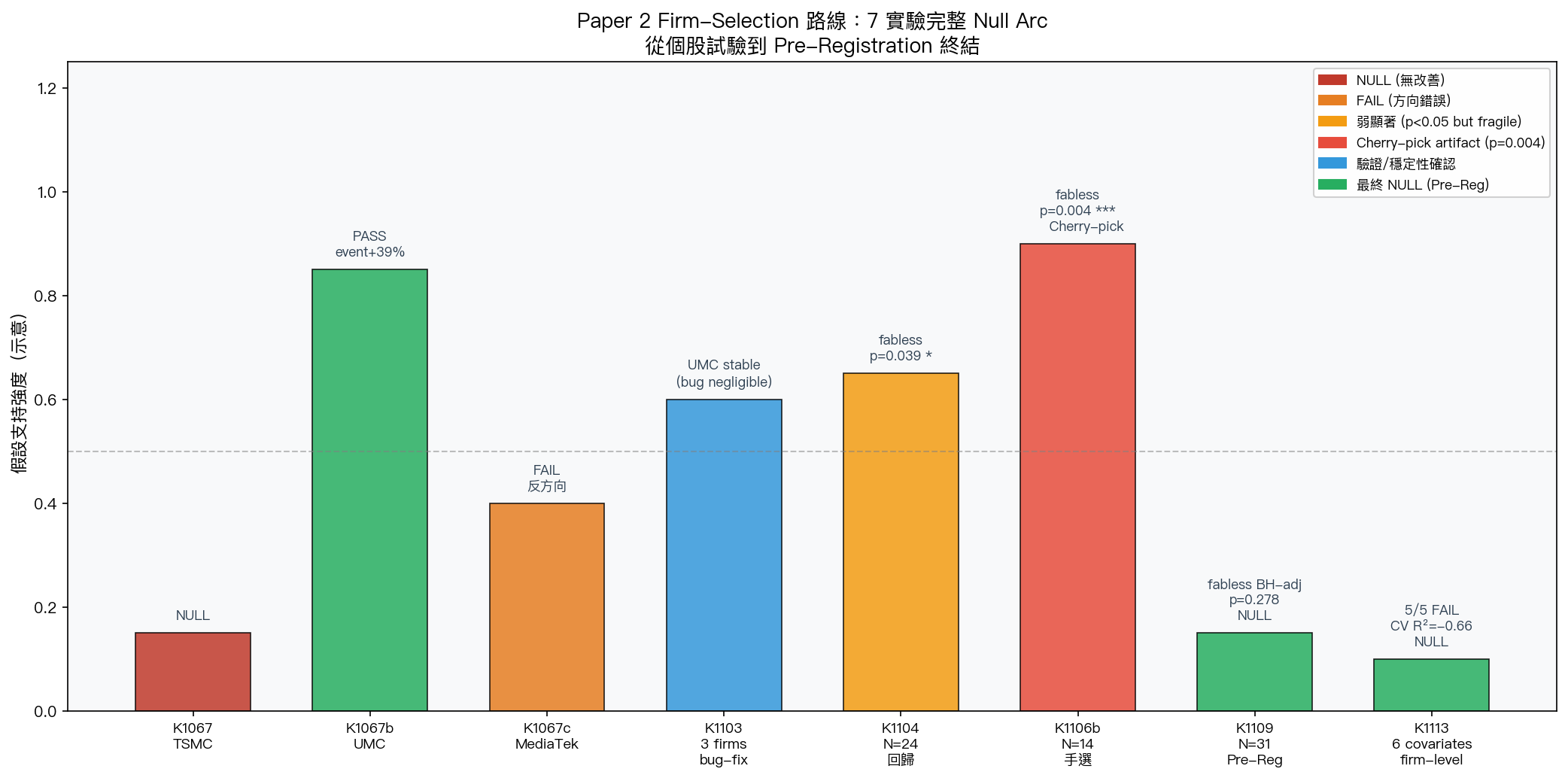
圖 2:7 個實驗的假設支持強度時間線。K1067b 的暫時成功和 K1106b 的 cherry-pick artifact 在 K1109 pre-registration 設計下完全瓦解,最終以 K1113 的全面 null 收尾。
八、終局:Firm-Level 協變數也無法預測(K1113)
既然 sector 類別無法區分「有效」vs「無效」公司,K1113 轉向連續型協變數,測試 6 個可觀測的公司特徵:
| 協變數 | 假說方向 | β | HC1 p 值 | BH-adj p 值 |
|---|---|---|---|---|
| log_mktcap(市值) | H2: β<0 | -1.10×10⁻⁴ | 0.682 | 0.854 |
| beta_rolling_0050(系統風險) | — | -8.96×10⁻⁵ | 0.746 | 0.854 |
| earnings_freq_per_year(財報頻率) | — | +5.72×10⁻⁵ | 0.623 | 0.854 |
| log_avg_volume(成交量) | — | +1.98×10⁻⁴ | 0.239 | 0.854 |
| price_volatility(股價波動度) | H3: β>0 | +3.28×10⁻⁵ | 0.854 | 0.854 |
| ind_momentum(產業動能) | — | -5.81×10⁻⁵ | 0.598 | 0.854 |
5/5 假設全部 FAIL:
- H1(至少一個 BH 存活):min BH-adj p=0.854, 無任何存活
- H2(市值負向):β<0 但 p=0.682, FAIL
- H3(波動度正向):方向正確但 p=0.854, FAIL
- H4(5-fold CV R²>0):CV R²= -0.661 , FAIL ——模型比純截距項預測還差
- H5(Tier A≥3家):Tier A 家數= 0 , FAIL
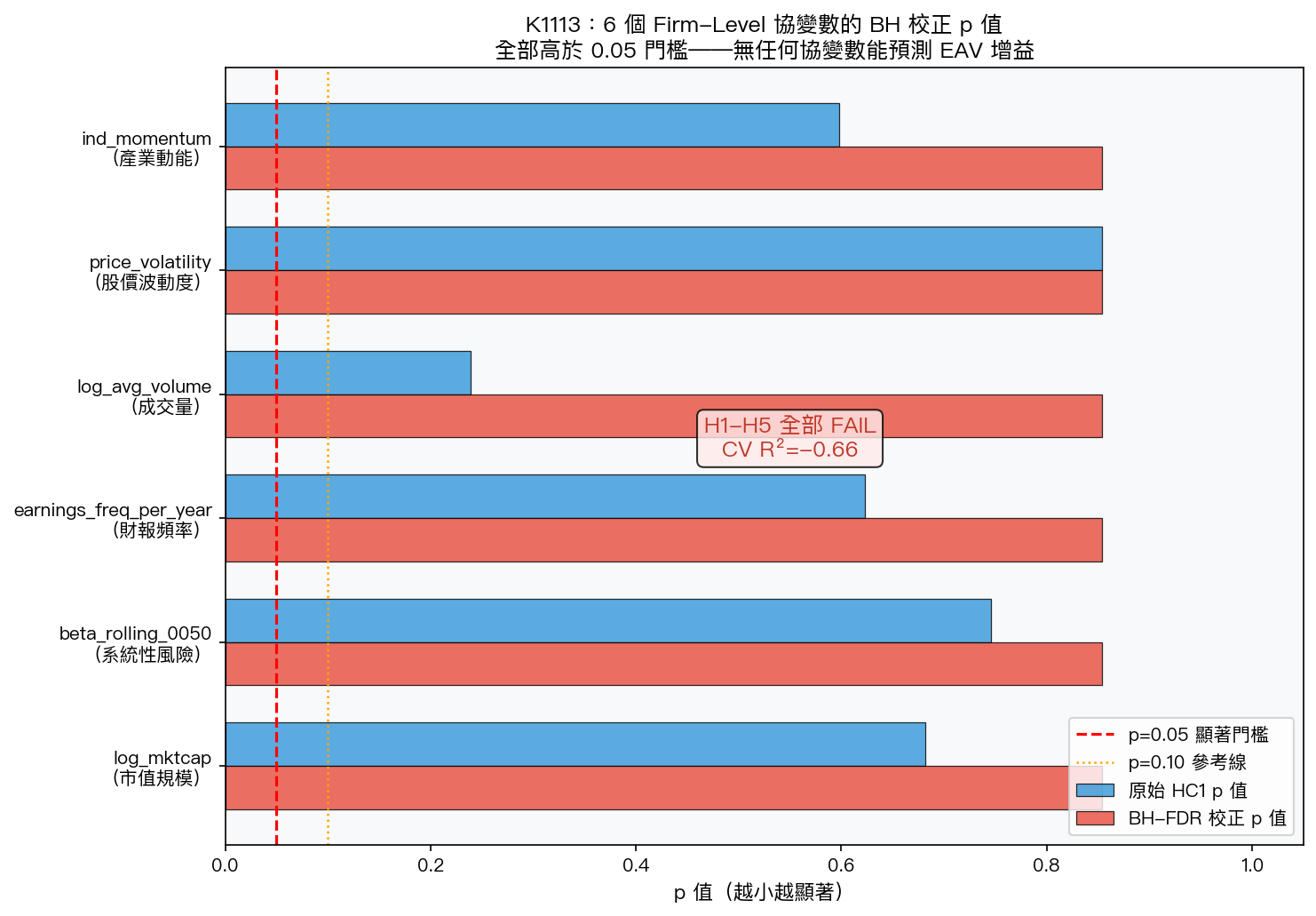
圖 3:K1113 各協變數的原始 HC1 p 值與 BH-FDR 校正後 p 值。最小的 raw p=0.239(成交量),BH 校正後全部收斂至 0.854。CV R²=-0.661 表示截面模型沒有任何超出截距的解釋力。
九、完整實驗總表
| 實驗 | 標的/設計 | 核心結果 | 最終判定 |
|---|---|---|---|
| K1067 | TSMC 單檔 A4f-EAV | 事件窗口 DM p=0.935,θ₂不穩定 | NULL |
| K1067b | UMC 強信號試驗 | 事件窗口 QLIKE+39.27%,DM p=0.036 | PASS(但 n=1) |
| K1067c | MediaTek T+1 | θ₂=-9.3×10⁻⁴,反方向,monotonicity FAIL | FAIL |
| K1103 | 三家 τ-lag bug-fix | UMC 穩定,bug 影響輕微 | 穩定性確認 |
| K1104 | N=24 截面回歸 | fabless p=0.039 *,foundry 不顯著 | 弱信號(白噪異方差問題) |
| K1106b | N=14 手選 7 sectors | fabless p=0.004 * **,ANOVA F(6,5)=6.87 | ** Cherry-pick artifact** |
| K1109 | N=31 Pre-Reg 隨機樣本 | ANOVA F(7,20)=1.31 p=0.297;fabless BH-adj p=0.278 | NULL(確認性) |
| K1113 | 6 firm-level 連續協變數 | 5/5 FAIL,CV R²=-0.661,Tier A=0 | NULL(確認性) |
十、對未來研究的啟示
A4f-EAV 在 pooled level 有 signal,但 heterogeneity 不可解釋。
本路線的終結並不意味著 EAV 概念無效——UMC 的 +39% 改善是真實的,pooled 層面也有統計信號。但這個增益的來源無法被任何可觀測的公司特徵所捕捉。
可能的原因包括:
- 需要私有數據 :散戶持股比例(非公開)、管理層溝通品質、分析師分散度(高頻更新的隱含波動率)
- 財報意外性的非線性 :earnings surprise 的量級和方向(非二元 binary)可能是真正的調節變數
- 時變異質性 :某家公司在某段時間有效,但無法事前預測
Null result 本身是 contribution: 它告訴未來研究者不需要走同一條路,節省了寶貴的資源;同時它確認了 pre-registration 作為防止 cherry-pick 的必要方法論工具。在整個 7 實驗路線中,若沒有 pre-registration(K1109)和獨立確認(K1113),研究者可能會帶著 p=0.004 的「顯著結論」撰寫論文,卻完全沒有意識到那只是一個 sampling artifact。
局限性
- 樣本來源 :0050.TW 成分股偏向大型藍籌,不代表全市場
- 財報公告日數據 :來源為用戶提供的
財報公告日.txt(2,411 公司,158,674 筆),未與 TEJ 交叉驗證 - OOS 期間 :2019-2025,含 COVID-19(2020)和台積電超級週期(2023-2024),異質性可能影響截面回歸穩定性
- 二元 EAV indicator 的侷限 :使用 0/1 二元變數,未考慮財報意外量級(earnings surprise magnitude)
數據來源:yfinance(日頻股價,auto_adjust=True)+ 財報公告日.txt(用戶提供)
實驗腳本:experiments/k1067/、experiments/k1067b/、experiments/k1067c/、experiments/k1103/、experiments/k1104/、experiments/k1106b/、experiments/k1109/、experiments/k1113/
結果數據:各實驗目錄下的 *_results.json
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊