把同一個模型算慢一點,答案真的會變嗎?
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
把同一個模型算慢一點,答案真的會變嗎?
做研究時,最麻煩的一種懷疑不是模型失敗,而是模型看起來有答案,但你不確定那個答案是不是靠運氣撐起來的。
這次檢查的就是這件事。前一版實驗為了把時間壓下來,把模型每次找答案時的搜尋範圍大幅縮小。速度快很多,可是也多一個合理疑問: 如果少算很多步,最後留下來的漂亮結果,會不會只是剛好?
所以這次沒有再談大方向,只做一件很實際的事。我們從前一版的 1000 次重跑裡,固定抽出 20 次,用完全相同的資料和設定,把原本的快版重新算成完整版,直接和舊版對照。
結果先看
答案很乾淨。
- 20 次裡, 最大差異只有 0.0918
- 平均差異只有 0.0049
- 中位數差異幾乎貼近 0
- 快版的核心數字中位數是 3.839
- 重新算成完整版之後,中位數還是 3.839
換句話說,前一版為了省時間做的近似,這次沒有被翻案。
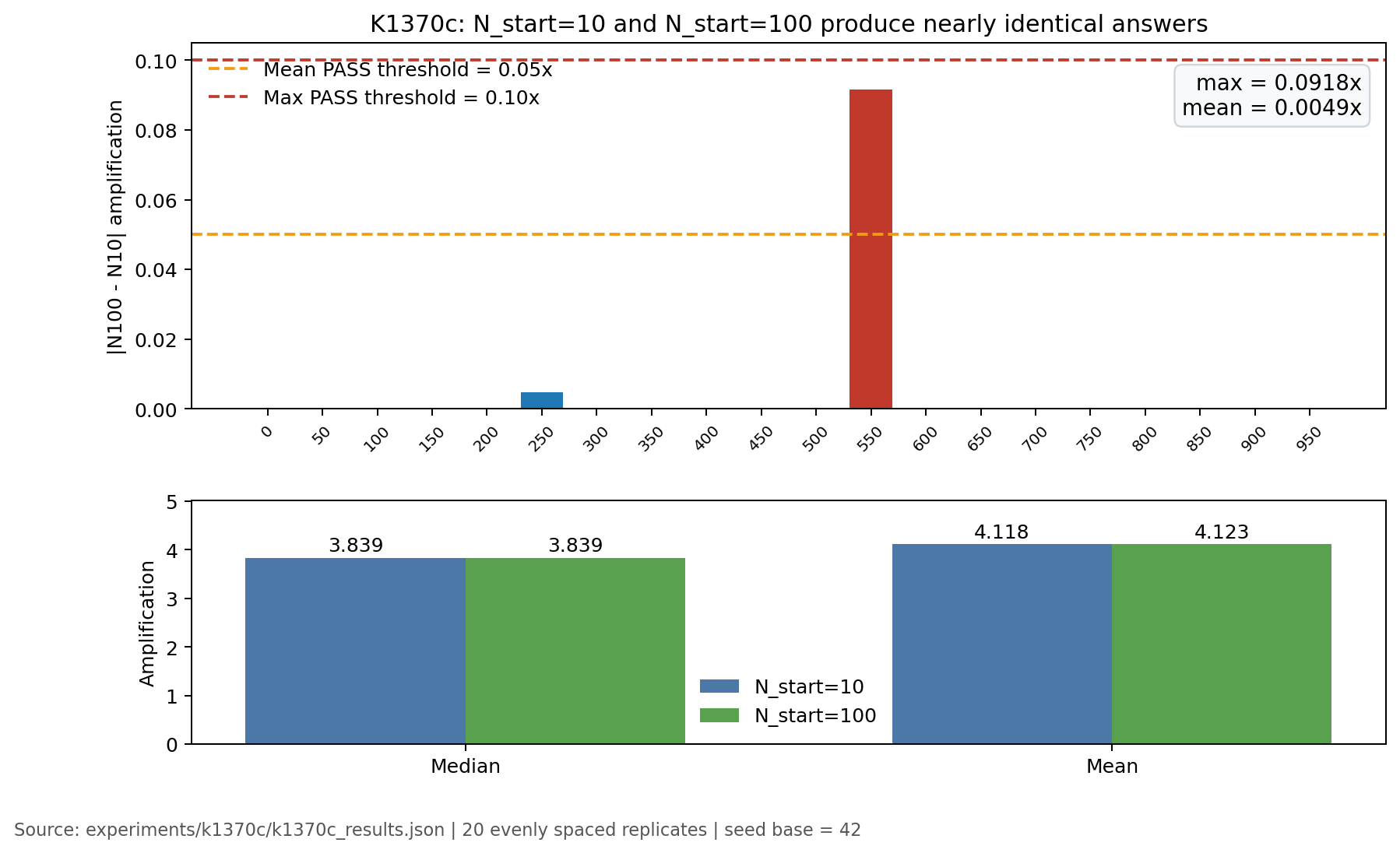
圖裡最值得看的是上半部。20 根柱子裡,只有 1 根接近容忍上限,其他幾乎都貼在地板上。這表示大多數情況下,快版和完整版最後得到的答案幾乎一樣。
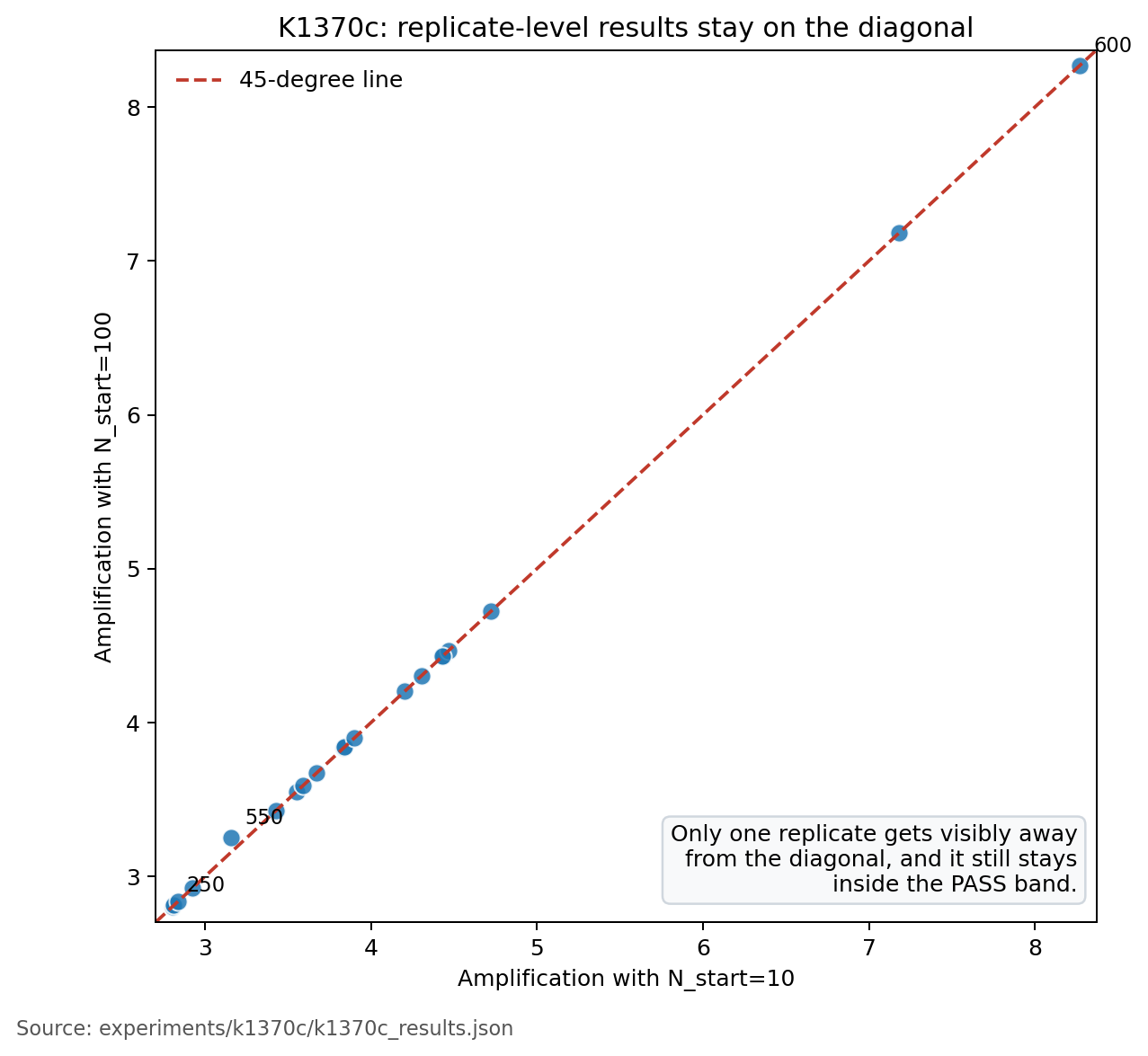
第二張圖更直白。每一個點都代表同一次重跑,橫軸放快版的結果,縱軸放完整版的結果。點如果貼著對角線,就代表兩邊幾乎沒差。這次大部分點都貼得很緊,只有一個點稍微偏開,但還沒有偏到需要改寫主結論。
這代表什麼
這種檢查的價值,不在於把結果再講一次,而是確認前一次的結果站不站得住。
如果快版真的偷吃步,重跑成完整版之後,理論上應該會常常出現明顯改寫。比如平均差拉大、最大差超標,或整體中位數被往上推一截。這次都沒有發生。
唯一比較突出的例子,是其中一次重跑差了 0.0918 。它還是留在原本設定的容忍範圍內,沒有把整個結論帶歪。其餘 19 次幾乎都只剩很小的差距。
對研究流程更重要的地方
這題其實在回答一個很常見的現實問題: 你到底要不要為了「更完美的重估」多等好幾個小時?
這次答案是,可以不用。
20 次重跑完整版花了大約 490 秒 。照這個速度線性外推,整批完整重跑會是數小時等級。既然結果幾乎不變,保留較快設定,比較像是理性的工程取捨,不是偷工減料。
對讀者來說,重點不是參數本身,而是研究團隊有沒有回頭驗證「省下來的時間,有沒有偷偷換掉答案」。這次的答案是,沒有。
本文基於實驗 K1370c(腳本:experiments/k1370c/k1370c_nstart_sensitivity.py;結果:experiments/k1370c/k1370c_results.json)。資料來源:K1370 v2 的重跑對照。設計:20 個等距樣本,固定 seed base=42,比較快版與完整版的核心數字差異。圖表來自 experiments/k1370c/k1370c_nstart_summary.png 與 experiments/k1370c/k1370c_diag_compare.png。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊