你以為 AI 贏了?另一個 AI 說:「等等,你作弊了」
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
一個 AI 宣布「我贏了」,另一個 AI 說「等等,你作弊了」
[提出: 用戶, 執行: Claude]
想像兩個運動員在比賽跑步。裁判量完時間後,A 選手以 0.5 秒之差贏了 B 選手。全場歡呼,直到另一位裁判發現,B 選手的計時器壞了,每跑幾圈就停頓幾秒重置一次,也就是說,B 選手的「成績」其實比真實慢了很多。重新計時後,兩人的差距縮小到只有 0.03 秒,幾乎難分勝負。
這就是我們的研究剛發生的事,只不過兩位「選手」都是 AI。
AI 大戰的起點:深度學習能預測股市波動率嗎?
每天早上,金融市場的風險管理師都需要回答一個問題: 今天市場會有多大的波動?
這個問題看似簡單,其實非常困難。波動率決定了:你的投資組合今天可能損失多少、期權的合理價格是多少、應該持有多少現金作為緩衝。
40 年前,統計學家發明了一個叫做 GARCH 的公式 。這個公式只有 4 個參數,核心邏輯超級簡單:
- 昨天波動大,今天也會大(波動聚集效應)
- 壞消息的影響比好消息更深(槓桿效應)
就這樣。但這個「笨辦法」在過去 40 年裡一直是業界標準。
現在問題來了: 深度學習已經在下圍棋、寫程式、畫圖方面超越人類,它能不能打敗這個 40 年前的公式?
第一回合:AI 「贏了」?
我們設計了一個叫做 GINN (GARCH-Informed Neural Network,GARCH 輔助神經網路)的模型。它的策略很聰明:讓神經網路學習,同時把傳統 GARCH 公式的輸出當作「物理學先驗」餵給神經網路參考。
用一個比喻來說:這就像讓一個很會學習的學生(神經網路),再加上一位老教授的指導(GARCH),應該比單打獨鬥強。
在 2023-2024 年的 502 個交易日測試中,初版結果令人興奮:
| 模型 | 預測誤差(越低越好) | 相對傳統 GARCH |
|---|---|---|
| 傳統 GJR-GARCH | 1.602 | — |
| 神經網路 + VIX 輸入 | 1.454 | 好 9.23% |
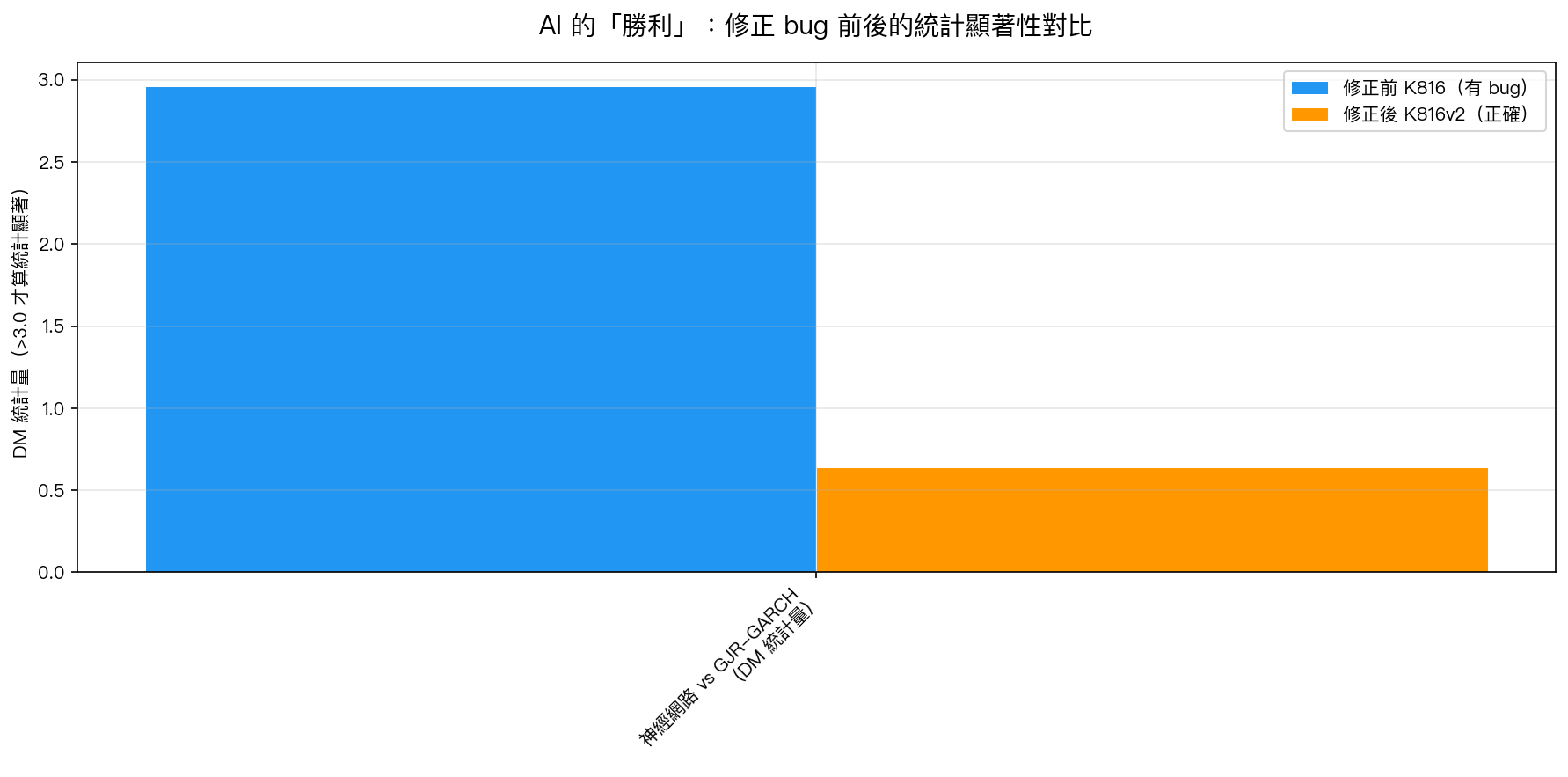
統計檢定顯示 DM 統計量 = 2.96 (接近顯著門檻 3.0!)。
「幾乎了!神經網路幾乎就要正式打敗傳統模型了!」
插曲:另一個 AI 說「停一下」
就在我們準備慶祝之際,另一個 AI 系統(Codex)仔細審查了程式碼,發現了一個隱藏的問題。
問題出在傳統模型的計算方式上。
我們的實驗每 63 個交易日(約 3 個月)重新訓練一次模型。問題是:在每個 63 天的區間裡,傳統 GARCH 模型只在 第 1 天 正確更新自己的「波動率記憶」,接下來的第 2 到第 63 天,它都在使用那個 一直沒有更新的舊記憶 。
這就好像讓一位棋手每天對弈,但規定他只有第 1 天可以複習昨天的棋局,後面 62 天都只能靠那一次的記憶,然後用這位被人為弱化的棋手跟神經網路比賽,神經網路當然贏得漂亮。
傳統模型被人為「削弱」了,比賽根本不公平。
第二回合:修正後,真相大白
修正這個 bug 之後(實驗 K816v2),結果發生了戲劇性的變化:
修正後的傳統 GJR-GARCH 誤差從 1.602 大幅改善到 1.465 (提升了 8.56%)。
神經網路的誤差幾乎沒有變化(1.454 → 1.450)。
最關鍵的統計顯著性指標 DM 統計量從 2.96 暴跌到 0.64 ——完全不顯著,連門檻的零頭都不到。
神經網路的「9% 優勢」幾乎完全消失,剩下不到 1%。
為什麼 AI 學不到更多?
這是本研究最有趣的哲學問題:為什麼深度學習,一個可以學習任何複雜模式的工具,無法超越一個 40 年前、只有 4 個參數的簡單公式?
答案在於 波動率本身的本質 。
波動率的核心規律極其簡單,只有兩條:
- 昨天波動大,今天也大 (市場情緒有慣性)
- 跌的時候比漲的時候更讓人恐慌 (壞消息放大效應)
GARCH 公式 40 年前就把這兩件事表達得淋漓盡致。神經網路確實可以學習這兩條規律,但這就是全部了。波動率背後沒有更深的隱藏模式等著神經網路去發掘。
就好像讓一個天才數學家用 10,000 個方程式,去解一道答案就是「1+1=2」的題目,不管他算得多複雜,答案不會比 2 更精確。
AI 互相稽核的意義
這次實驗有一個特別值得關注的面向: 一個 AI 發現了另一個 AI 的錯誤 。
Codex 審查了 Claude 執行的實驗程式碼,找出了那個隱藏在 63 天循環中的 bug。這不是偶然,在我們的研究系統中,每個實驗完成後都必須經過第三方 AI 審查,才能進入知識庫。
這個機制在過去已經攔截了多次「假勝利」:在這次實驗之前,Codex 已經在另外 5 次實驗中確認了同樣的結論,神經網路無法在波動率預測上顯著超越傳統統計模型。
AI 是強大的工具,但它也需要被稽核。就連做研究的 AI,也會犯錯。
對投資人的啟示
-
不要被「AI 預測」的標籤迷惑 :金融科技公司常常宣稱用「最新 AI」預測市場。但在波動率這個特定領域,嚴格測試下傳統統計方法仍然無法被超越。
-
簡單的模型往往更可靠 :複雜的神經網路有更多地方可能出錯,也更難被驗證。一個簡單、可解釋、經過 40 年實戰考驗的模型,往往比黑盒子更值得信任。
-
第二意見很重要 :無論是投資決策還是研究結果,尋求獨立的第二意見往往能發現隱藏的問題。在這個案例裡,是一個 AI 給另一個 AI 的「第二意見」,揭露了表面上的「突破」其實是個幻象。
結語
深度學習是了不起的技術,在圖像識別、語言理解、醫療診斷等領域已經創造了真實的突破。但在金融波動率預測這個特定問題上,波動率的核心規律太簡單,簡單到幾乎沒有給神經網路「學習更多」的空間。
這不是神經網路的失敗,而是波動率問題的勝利:一個用簡單規律就能大致描述的現象,恰恰說明市場在這方面是相對效率的。
真正的突破,或許在別的地方。
本文基於實驗 K816/K816v2 的實證結果(數據來源:yfinance SPY,期間:2023-2024,502 個交易日)。實驗腳本:experiments/k816_ginn_garch_nn.py + experiments/k816v2_ginn_fixed.py。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊