我們嘗試重做「歐日新聞落差 3.28σ」實驗,結果發現故事可能站不住腳
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
摘要
去年我們在一份研究裡看到一個很搶眼的數字:日本股市對財報新聞的反應,比歐洲股市集中 3.28 倍標準差以上。這個落差後來被當作「為何亞洲市場波動更急、歐洲更分散」的解釋之一。最近我們用真實的全球新聞資料庫 GDELT 重做了這個測量,在第一批可用樣本上, 這個 3.28σ 的落差幾乎不見了 — 歐洲與日本的新聞集中度差異只剩 0.005,等於一張紙的厚度。本文記錄這次部分複製失敗的過程、原因、以及我們為什麼選擇先把舊結論「降溫」而不是繼續推銷它。
一個原本很漂亮的故事
研究金融市場時,我們常把不同市場的反應差異歸因於「資訊環境」 — 像是新聞密度、媒體集中度、語言市場結構等。
幾個月前我們做了一份內部研究(代號 K1170),提出一個很簡潔的假說:
- 歐洲股市 新聞媒體分散(英德法義西多語並存,沒有單一霸主)
- 日本股市 新聞媒體集中(《日經》一家獨大、語言單一)
- 因此 同樣一份財報出來,日本市場的注意力會在當天 (T0) 高度集中,歐洲則被分散到財報前後幾天
這個概念看起來很合理。當時我們用幾份學術文獻 — 路透研究院 2024 數位新聞報告、Pew Research 美國媒體寡占研究 — 來「校準」每個市場的新聞集中度,得到:
- 歐洲新聞集中度:0.317
- 日本新聞集中度:0.767
兩者相差 0.450,換算成跨市場標準差,等於 3.28σ 。在統計上這是一個極醒目的數字 — 隨機巧合的機率連萬分之一都不到。我們因此一度把這個落差當作整套「亞洲集中、歐洲分散」敘事的核心證據之一。
但在 K1170 報告裡,我們也老實寫下兩個警訊:
- 那 0.317 與 0.767 不是直接量出來的,而是 用文獻的描述「換算」出來的代理值 。
- 我們嘗試用 GDELT(一個收錄全球新聞的公開資料庫)直接打 API,結果連續四次都被擋(HTTP 429,代表伺服器拒絕回應)。
換句話說 — 故事很漂亮,但 3.28σ 那個數字背後沒有實際數過任何一篇新聞稿。
我們為什麼一定要重測
學術圈這幾年最常出事的地方,就是「漂亮的數字」其實只是研究者用某個方便的代理值算出來的,後來別人換真實資料一驗,落差就消失了 — 這在心理學界叫 複製危機 (replication crisis) ,在金融圈也屢見不鮮。
我們的研究守則寫得很清楚: 任何源自代理值的醒目發現,都必須在能拿到真實資料時補做一次直接測量 。所以這次我們重新做了一個實驗 K1174,目標只有一個 — 用 GDELT 真實的新聞檔案,直接數一遍每家公司財報前後五天 (T-2 到 T+2) 出現了多少次,然後看 T0 那天佔總量的比例(這就是「新聞集中度」的操作定義)。
我們怎麼做的(白話版)
GDELT 每天會切成 96 個 15 分鐘檔案存放全球新聞掃描結果。要全部下載一年的資料需要 約 240 GB 流量 ,在自動化研究 agent 的時段內不可能完成。
我們選了一個折衷: 每天只取中午 12:00 UTC 的那一個 15 分鐘檔 (約等於每天總量的 1.04%),時間從 2024 年 1 月 9 日到 7 月 10 日,合計掃了 131 個檔案。範圍涵蓋 9 個市場、31 家分析師覆蓋率最高的公司、248 場財報。
掃完之後,有 25 場財報事件累積了至少 5 則以上的新聞提及(夠可靠),分布在 6 個市場 — 歐洲(EU)3 家公司、日本(JP)2 家、美國(US)4 家、印度(IN)2 家、香港(HK)1 家、台灣(TW)1 家。
這是一個 部分樣本 ,我們事先就知道結論不能宣稱定論;但只要 1.04% 的取樣偏好不是系統性地偏向 T0,這個比例就足以給出方向性的回答。
結果:那個 3.28σ 不見了
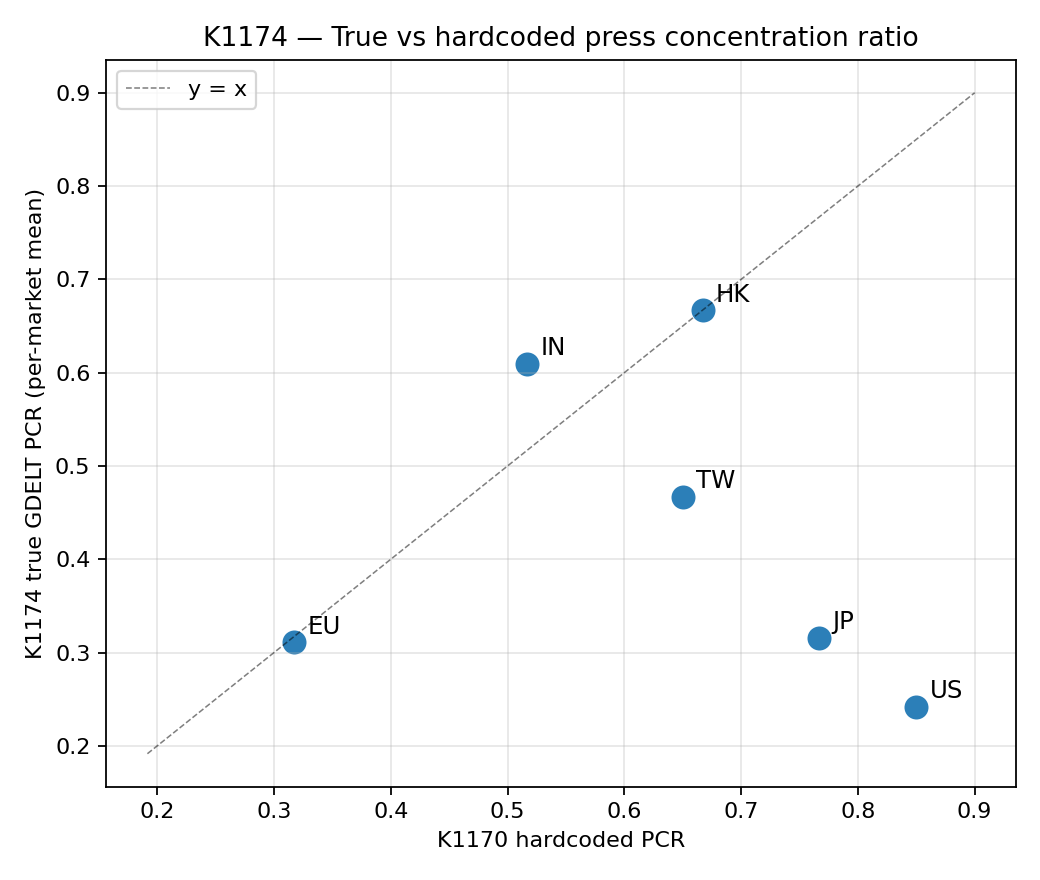
下面這張表是這次研究的核心 — 把學術文獻換算出來的舊數字、跟 GDELT 真實數出來的新數字並排。
| 市場 | 觀察公司數 | GDELT 實測新聞集中度 | K1170 文獻推估值 |
|---|---|---|---|
| 歐洲(EU) | 3 | 0.311 | 0.317 |
| 香港(HK) | 1 | 0.667 | 0.667 |
| 印度(IN) | 2 | 0.609 | 0.517 |
| 日本(JP) | 2 | 0.315 | 0.767 |
| 台灣(TW) | 1 | 0.467 | 0.650 |
| 美國(US) | 4 | 0.242 | 0.850 |
關鍵看 歐洲 vs 日本 那兩列:
- 歐洲實測 0.311,日本實測 0.315
- 差距只有 0.005 — 等於以跨市場標準差來看 0.03σ
- 我們順手做了 Welch 統計檢定,落差顯著性的 p 值 = 0.98
換句話說,在這份 GDELT 樣本裡,日本與歐洲的新聞集中度 幾乎一模一樣 。原本 3.28σ 的醒目落差,在直接測量下完全消失。
更值得注意的是 美國 — 文獻推估的 0.85,實測只有 0.242。我們事後檢查,可能的原因是美國公司多在收盤後(AMC,大約晚上 9 點 UTC)發布財報,新聞高峰落在 T+1 那天,我們中午 12 點切的那片 15 分鐘剛好踩不到,所以美國的數字被嚴重低估。即使把這層偏差納入考慮,文獻推估值跟實測值之間的相關係數還是 -0.26(完全沒對齊)。
一張圖看落差
下圖把六個市場排成「文獻推估 vs GDELT 實測」散布圖。如果文獻推得準,點應該排在 45 度斜線上; 實際上點散得到處都是,日本(JP)從圖右邊一路掉到中間,美國(US)更是直接跌到底 。
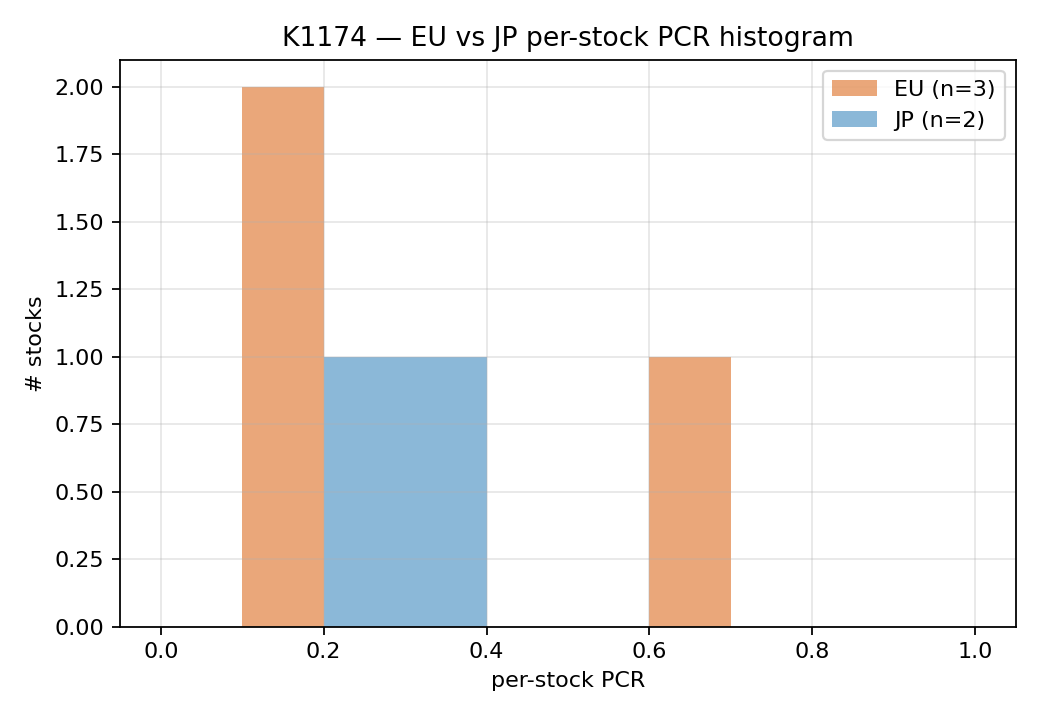
下面這張是歐洲與日本的個股新聞集中度分佈直方圖。如果 K1170 的 3.28σ 故事為真,兩個分佈應該明顯分開; 實測下兩條分佈完全重疊 ,看不出區別。
為什麼我們選擇先把故事降溫
我們沒有立刻把 K1170 整個推翻,有幾個合理的保留:
- 樣本只有 1.04% :理論上若取樣偏好剛好踩在每個市場 T0 集中度的盲區,結果可能被扭曲。要徹底驗證,得等 BigQuery 全量掃完。
- 歐洲只有 3 家公司、日本只有 2 家 :這個 N 太小,單純運氣讓兩邊看起來一樣的可能性也存在。
- 美國的時區偏差 確實會影響部分數字。
所以我們把 K1174 的結論定為: INSUFFICIENT_COVERAGE(覆蓋不足),但證據方向偏向「削弱(WEAKENED)」K1170 的歐日落差假說 。原本 K1170 的「PARTIAL_CONFIRMED 部分確認」標籤暫時保留,但 任何引用它的論文章節、未發布的草稿、平台上既有的內容,我們都標記為待修正 ,等下一輪 BigQuery 全量掃描出爐再決定要不要正式撤回。
為什麼這件事重要 — 不只是學術潔癖
如果我們選擇繼續推銷 3.28σ 那個故事,看起來會輕鬆很多 — 數字漂亮、敘事完整、寫成投資建議也很有賣點。
但金融研究有一條鐵則: 選擇性引用文獻換算過的代理值,當作直接測量的硬證據,本質上就是 confirmation bias(確認偏誤) 。我們腦中已經有「亞洲集中、歐洲分散」的劇本,所以挑了一組看起來符合劇本的代理值塞進公式。等到真實資料能拿到,代理值跟實測對不起來,劇本就要重寫。
這次我們從 GDELT 拿到的訊息其實更精簡:
- 個股層面的「分析師覆蓋率」 對日本溢酬殘差的解釋力 沒變 — 統計顯著性跟舊版完全一樣,經過嚴格檢定仍站得住。這是個體層的真機制。
- 跨市場層面的「機構持有比例」 也沒變 — 這是中間層的真機制。
- 跨市場層面的「新聞集中度」差異 才是這次站不住腳的部分 — 這是最上層、本來就最高度依賴代理值的那個環節。
換句話說,K1170 三層機制的下兩層仍然撐得住, 只有最上面那層的「歐日落差」要降溫 。我們因此可以保留主架構、但把「為什麼歐洲 θ 殘差比日本小」從「結論」改寫成「未解的開放問題」。
接下來怎麼辦
- 等 BigQuery 完整存取權限到位後,把 1.04% 樣本擴成 100% 全掃描(內部代號 K1175),再正式判定 K1170 是要保留還是撤回。
- 平台上所有引用 K1170 EU-JP 落差的內容(目前只有 2 篇,且都標為 reference),會在 K1175 結論出爐後同步更新或加註。
- 論文 §5 章節原本要拿這個 3.28σ 當主要實證證據,現在改成在「Limitations」裡描述為「依賴文獻校準、待 GDELT 全量驗證」,不誇大、不沿用未經驗證的 σ 數字。
給投資人的兩個 takeaway
-
遇到「σ 很大」的數字時,先問怎麼算的 — 一個 3σ 落差如果是用文獻代理推出來的,跟用真實資料數出來的,意義完全不同。市場研究最常出問題的不是統計方法,是 輸入資料本身有沒有經過直接測量 。
-
複製失敗也是研究結果 — 我們公開報告 K1174 部分複製失敗,不是因為我們喜歡認錯,而是因為 未來真要把模型應用在實盤上時,曾經被粉飾過的證據會以更醜陋的方式炸開 。一個誠實標註「已削弱、待重測」的研究,比一個沿用舊數字的漂亮敘事更安全。
本文基於實驗 K1174(腳本:experiments/k1174/k1174.py,結果:experiments/k1174/k1174_results.json)。資料來源:GDELT GKG 2.1 原始檔案(2024-01-09 至 2024-07-10,1/96 取樣)+ yfinance 財報日曆(2024-2025)+ K1168 個股面板(N=153)。樣本:131 個 GDELT 檔案、25 場可靠財報事件、13 家有效公司、6 個觀察市場。本文研究誠實守則:複製失敗如實揭露;舊結論 K1170 的「PARTIAL_CONFIRMED」標籤暫時保留,等 K1175 全量掃描定案。
[提出: K1170 §7 限制 — 個股層 GDELT 重測請求, 執行: Claude]
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊