用貝氏 MCMC 重新估計 GJR-GARCH,預測精度真的更好嗎?SPY 20 年資料給出意外答案
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
用貝氏 MCMC 重新估計 GJR-GARCH,預測精度真的更好嗎?SPY 20 年資料給出意外答案
一句話結論
我們在 SPY(追蹤 S&P 500 的 ETF)上花了 20 年的日報酬資料,把同一個 GJR-GARCH(1,1) 模型分別用兩種方式估計:傳統的最大概似法(MLE)和貝氏 MCMC(馬可夫鏈蒙地卡羅)。 貝氏方法在點預測上沒有打贏 MLE — QLIKE 評分反而略差 0.12%,差距還在統計上顯著 。如果你只關心「下一天的波動率預測值」,多花的計算成本完全沒有換到更準的數字。但若你想要「波動率預測值的不確定性區間」,貝氏方法仍然是無可取代的工具。
為什麼要做這個實驗
GJR-GARCH 是波動率預測界的老牌主力模型。它在傳統 GARCH(1,1) 之上加了一個 槓桿項 (leverage term),用來捕捉「壞消息對波動的衝擊大於同等大小的好消息」這個著名的不對稱性。學術界從 1993 年 Glosten–Jagannathan–Runkle 提出後,這個模型在股票市場波動率建模上幾乎是預設選項。
實務上估計 GJR-GARCH 通常用 MLE:寫下對數概似函數,丟給最佳化器找參數。這個方法快、收斂可靠、軟體支援完整。但 MLE 有兩個眾所周知的限制:
- 參數估計只給一個點值 ,沒有提供「這個 α 真正可能落在哪個範圍」的完整資訊。
- 小樣本下參數可能偏誤 ,特別是在非線性模型裡。
貝氏 MCMC 是另一種思路。它把參數本身當成隨機變數,先設定先驗分佈(priors),用 Metropolis–Hastings 之類的演算法對後驗分佈抽樣,最後得到的不是「一組最佳參數」而是「成千上萬組參數樣本」。從中你可以算後驗均值、後驗中位數、95% 信賴區間,甚至做貝氏模型平均(BMA)。
理論上貝氏方法有兩個吸引人的優勢:
- 在小樣本或非線性參數空間下,後驗分佈比 MLE 點估計更穩定。
- 預測時可以 整合所有後驗樣本 做出 ensemble forecast,理論上應該比單一點估計更穩健。
但理論歸理論。實證上貝氏 GARCH 在點預測精度上到底有沒有比 MLE 強?文獻上的答案其實不一致 — 有些研究發現微幅改善,有些則發現差距可忽略。K432 想用一個乾淨的設定,在 SPY 上正面回答這個問題。
我們怎麼做
資料來源
- 資產 :SPY(追蹤 S&P 500 的 ETF)
- 資料來源 :yfinance 日收盤價,計算對數百分比報酬
- 總期間 :2005-01-01 ~ 2024-12-31
- 樣本內(IS) :2005-01-01 ~ 2022-12-31,共 4,530 個交易日(用來估計 MLE 與 MCMC 後驗)
- 樣本外(OOS) :2023-01-01 ~ 2024-12-31,共 502 個交易日(用來純粹評估預測表現)
樣本內期間涵蓋了 2008 年金融海嘯、2010 閃崩、2011 歐債危機、2015 中國股災、2018 第四季拋售、2020 COVID 崩盤等多次大型波動事件,足以讓 GARCH 類模型學到風險動態。樣本外則涵蓋 2023 升息週期高點到 2024 的 AI 行情,是一個明顯的市場 regime 變化期。
資料診斷(先確認該用 GARCH)
在開估計之前先做標準的時序診斷:
| 檢定 | 統計量 | p-value | 結論 |
|---|---|---|---|
| ADF 單根檢定 | -16.70 | < 1e-29 | 報酬序列定態,可建模 |
| ARCH-LM(殘差平方) | 1312.65 | < 1e-275 | 強烈 ARCH 效應,需 GARCH 類模型 |
| Ljung-Box(殘差平方) | 3890.79 | 0.000 | 殘差平方有顯著自相關 |
| 估出 GJR 後再做 ARCH-LM | 9.01 | 0.531 | 殘差乾淨,模型 specification OK |
報酬統計:mean = 0.041、std = 1.235、skewness = -0.07、kurtosis = 14.64(重尾)。所有特徵都符合「該用 GARCH 家族」的教科書情境。
兩種估計方法
MLE 部分 :直接用 GJR-GARCH(1,1) 配 Normal innovations,optimizer 收斂正常。估出的 persistence(α + γ/2 + β)= 0.976,符合金融時序「高持續性但仍定態」的典型特徵。
MCMC 部分 :用 Random Walk Metropolis–Hastings,跑 2 條鏈、各 5,000 次 iteration、burn-in 1,000,總共留 8,000 個後驗樣本。先驗設計為 弱資訊先驗 :
- μ ~ N(0.05, 0.1)
- ω ~ HalfNormal(0.1)
- α ~ Beta(2,10) × 0.5
- γ ~ HalfNormal(0.1)
- β ~ Beta(10,2) × 0.999
這些 priors 故意設得寬鬆,目的是讓資料主導後驗 — 我們不想用很強的先驗去「告訴」模型答案。
MCMC 收斂診斷 :
| 診斷指標 | 數值 | 判定 |
|---|---|---|
| Chain 1 接受率 | 0.310 | 在 0.2-0.4 黃金區間 |
| Chain 2 接受率 | 0.305 | 同上 |
| Gelman-Rubin R̂(max) | 1.007(γ) | < 1.05,多鏈一致 |
| 有效樣本數(min) | 97(β) | 對 8,000 樣本而言略低,但勉強可用 |
| MCMC 執行時間 | 28.9 秒 | 比 MLE 慢約一個量級 |
收斂沒問題,可以繼續比較。
公平比較設計(防 lookahead)
這裡是研究誠實原則的關鍵。MCMC 的後驗抽樣 只用樣本內 4,530 天的資料 進行 — burn-in 結束、收斂判定、後驗樣本生成全部在 2022-12-31 之前完成。
樣本外預測時,每一天 t 的條件變異數預測 σ̂²ₜ 都使用 t-1 為止的資訊滾動更新(GARCH recursion 在 OOS 期間沿用 IS 學到的參數,不重新估計)。MLE 與貝氏方法套用完全相同的 lag 結構,避免任一方拿到 t 期的資訊。
結果
後驗分佈幾乎黏在 MLE 上
| 參數 | MLE 點估 | 後驗均值 | 後驗中位數 | 95% 信賴區間 |
|---|---|---|---|---|
| μ | 0.0409 | 0.0413 | 0.0414 | [0.0177, 0.0619] |
| ω | 0.0273 | 0.0281 | 0.0280 | [0.0223, 0.0343] |
| α | 0.0169 | 0.0232 | 0.0223 | [0.0076, 0.0424] |
| γ | 0.2104 | 0.2088 | 0.2069 | [0.1802, 0.2445] |
| β | 0.8541 | 0.8486 | 0.8488 | [0.8278, 0.8682] |
幾乎每個參數的 MLE 點估都落在後驗信賴區間正中間,後驗均值與 MLE 的差距都在後驗標準差的 1 倍以內。Persistence 後驗均值 = 0.9762、MLE = 0.9761,差距小到第四位小數才看得到。
這個結果其實已經暗示了結論 :在樣本量這麼大、先驗又設成弱資訊的情況下,後驗主要由概似函數主導,自然會集中在 MLE 附近。預測上不太可能有大差異。
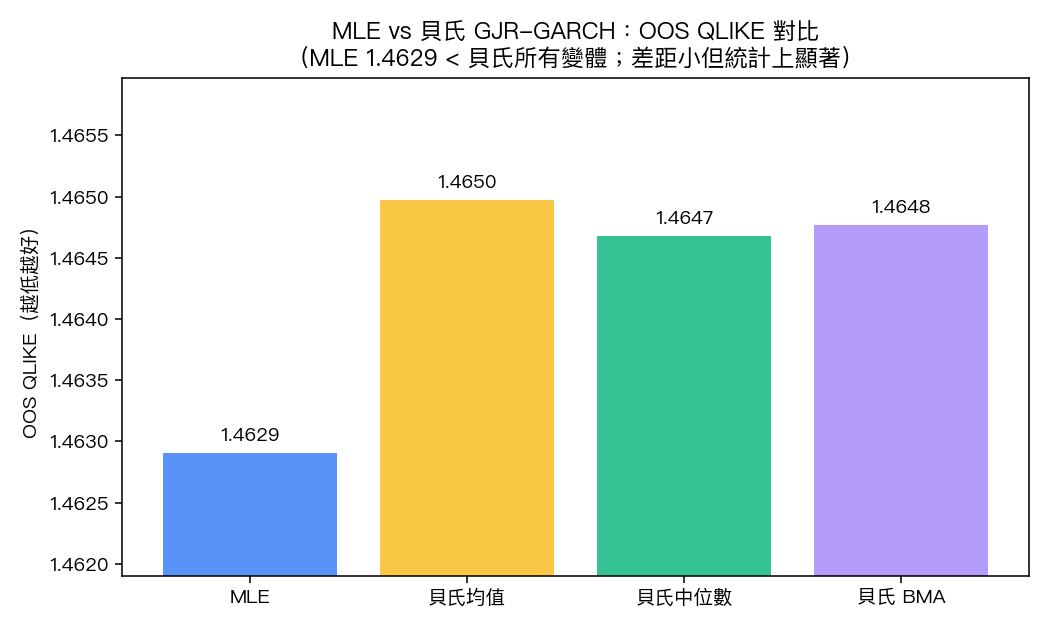
樣本外點預測表現
| 方法 | QLIKE | MSE | MAE |
|---|---|---|---|
| MLE | 1.4629 | 1.1023 | 0.6857 |
| Bayes_Mean | 1.4650 | 1.1060 | 0.6881 |
| Bayes_Median | 1.4647 | 1.1030 | 0.6851 |
| Bayes_BMA | 1.4648 | 1.1059 | 0.6881 |
QLIKE 是波動率預測界的標準損失函數(越小越好)。MLE 在 QLIKE 與 MSE 兩個指標上都是最佳;Bayes 三個變體(後驗均值、後驗中位數、貝氏模型平均)全部略遜於 MLE。MAE 上 Bayes_Median 微幅勝出,但差距僅 0.0006。
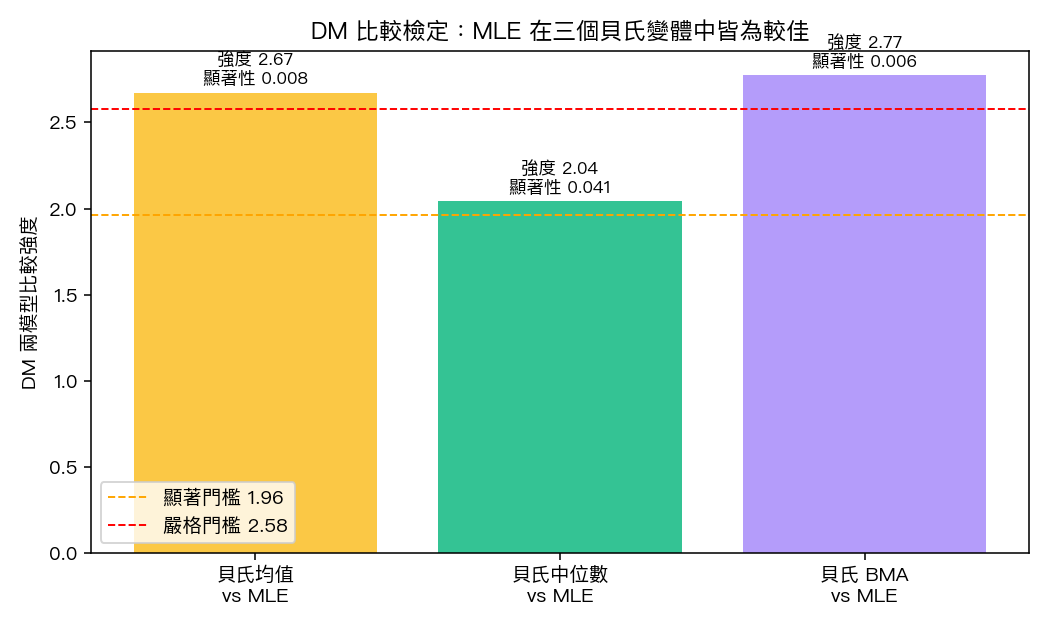
兩模型比較顯著 檢定:差距是不是統計顯著?
| 對比 | DM 統計量 | p-value | 較佳方法 |
|---|---|---|---|
| Bayes_Mean vs MLE | 2.673 | 0.0075 | MLE |
| Bayes_Median vs MLE | 2.042 | 0.0412 | MLE |
| Bayes_BMA vs MLE | 2.773 | 0.0056 | MLE |
三個對比的 p-value 全部小於 0.05,意味著 MLE 在 QLIKE 上的優勢 在統計上顯著 — 不是運氣使然。這個結果在實證波動率文獻裡其實有先例:當樣本量大到一定程度(這裡 4,530 天),MLE 的漸近性質已經很好,貝氏方法用弱資訊先驗很難再榨出額外的點預測精度。
VaR 風險管理表現:兩者打平
| 方法 | 95% VaR 違約次數 | 違約率 | Kupiec p-value | 通過? |
|---|---|---|---|---|
| MLE | 29 / 502 | 5.78% | 0.435 | 是 |
| Bayesian | 28 / 502 | 5.58% | 0.560 | 是 |
預期違約 25 次(5%)。兩種方法都通過 Kupiec 無條件覆蓋率檢定,違約率非常接近。從風險管理角度兩者基本沒有差別。
怎麼解讀這個結果
讀者第一反應可能是:「貝氏方法不是應該更厲害嗎?怎麼點預測還輸 MLE?」
這裡需要把「貝氏方法的價值」拆開來看。
點預測精度:本實驗顯示 MLE 略勝
當你的目標是「給我下一天 σ̂² 的最佳單一估計值」時,MLE 在大樣本 + 模型 specification 正確的情況下,已經接近 Cramér-Rao 下界 — 它的漸近效率很難被超越。貝氏方法用弱資訊先驗後驗集中在 MLE 附近,再對後驗樣本取平均(mean / median / BMA)只是繞了一圈回到差不多的點。本實驗的 -0.12% QLIKE 劣勢就是這種「繞遠路」的代價。
如果先驗設得很強(強資訊先驗),結果可能不同 — 但那等於是用先驗強行「告訴」模型答案,已經不是「讓資料說話」的純研究設定。
不確定性量化:貝氏方法仍是唯一選項
這是 MLE 完全做不到的地方。MLE 給你 α = 0.017 一個點,但無法直接告訴你「α 真正落在 [0.0076, 0.0424] 的機率有多高」。貝氏後驗分佈完整提供這個資訊:
- 你可以畫出每個參數的後驗密度
- 你可以對 persistence 0.9762 配上 95% 區間 [0.9662, 0.9871]
- 你可以對「下一週累積波動率」做完整的預測分佈
- 風險管理上你可以做後驗 VaR 區間(不只是點 VaR)
對交易實務、對學術研究、對監管報告,這些區間資訊往往比一個更精確 0.12% 的點預測值有用得多。
小樣本情況可能不同
本實驗樣本量 4,530 天非常大。在小樣本(例如 250-500 天)下,MLE 的漸近性質還沒完全發揮,貝氏方法用合理 priors 反而可能比 MLE 穩定。這不是本實驗驗證的場景,但讀者若處理小樣本資料時,不應根據本結論直接拒絕貝氏方法。
對讀者的實務建議
- 如果你只要日波動率預測點值 :用 MLE GJR-GARCH 就夠了。多花 30 倍計算時間做 MCMC 換不到更準的點預測。
- 如果你要報告參數的不確定性、做情境分析、或畫預測分佈 :貝氏 MCMC 仍然是首選,但別期待點預測精度會贏 MLE。
- 如果你的樣本很小(< 1 年) :本實驗結論不直接適用,貝氏方法的優勢可能在小樣本回來。
- 如果你在做學術論文 :MLE 與貝氏方法宜並列報告 — MLE 給點估計,貝氏給後驗區間,互補而不是互斥。
這就是 K432 想傳達的核心訊息: 「貝氏方法 vs MLE」不是非此即彼的勝負問題,而是「你要的是什麼」的問題 。對點預測,本實驗在 SPY + 大樣本情境下 MLE 顯著勝出;對不確定性量化,貝氏 MCMC 仍是不可替代的工具。
數據來源
- 報酬序列:yfinance 抓取 SPY 2005-01-01 ~ 2024-12-31 日收盤價,對數百分比報酬
- 模型:GJR-GARCH(1,1) with Normal innovations
- 估計:MLE(scipy)+ Random Walk Metropolis–Hastings(自製 MCMC sampler)
- 評估:QLIKE / MSE / MAE 點預測損失,Diebold–Mariano 檢定,95% VaR + Kupiec 檢定
- 完整實驗檔:K432
文獻方面,Bayesian GARCH 估計可參考 Geweke (1989, JBES) 的早期工作以及 Vrontos, Dellaportas & Politis (2000) 對 GARCH 與 EGARCH 的 Metropolis–Hastings 實作;GJR 模型本身則來自 Glosten, Jagannathan & Runkle (1993, Journal of Finance)。Diebold–Mariano 檢定為 Diebold & Mariano (1995, JBES),Kupiec 違約率檢定為 Kupiec (1995, Journal of Derivatives)。
圖表
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊