跨產業檢驗個股波動率的 VIX 敏感度:誠實的負面結果
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
跨產業檢驗個股波動率的 VIX 敏感度:誠實的負面結果
為什麼要做這個實驗?
過去一系列在 K1100 家族的研究中,我們持續探討一個問題:當總體市場波動指標(例如 VIX)變動時,個股的條件波動會跟著怎麼動?這個敏感度在 A4f-EAV 模型裡用一個叫做 θ₂ 的係數來捕捉,它代表「重大公司事件日(例如法說會、財報公告)期間,VIX 對該股波動的放大效應」。
K1104 在 0050.TW 的成分股上估計了個股 θ₂,發現了顯著的「跨個股異質性」,不同公司的 θ₂ 數值差異懸殊,連符號都不一樣。這個發現很吸引人,但用戶(賴奕豪教授)很快指出一個盲點: K1104 的成分股有超過 80% 集中在半導體相關產業 (晶圓代工、IC 設計、封測、記憶體、光電)。金融、航運、傳產、消費防禦這些產業每一個只有一到三家公司,根本不能算是跨產業樣本。
換句話說,當我們宣稱「θ₂ 在跨產業上有異質性」時,我們研究的橫截面其實並不真的「跨產業」。這是一個 研究誠實原則 直接命中的盲點:結論的強度不能超過證據的範圍。
K1106b 就是為了補這個缺口設計的:刻意挑選 7 個產業 × 每個產業 1–3 家公司,總共 14 家 ,看看在去掉半導體獨大的扭曲後,跨產業異質性是否仍然存在。
實驗設計
樣本(N=14)
| 產業 | 個股代號與名稱 |
|---|---|
| 晶圓代工(foundry) | 2330 台積電、2303 聯電 |
| IC 設計(fabless) | 2454 聯發科、2379 瑞昱 |
| 金融(financials) | 2881 富邦金、2886 兆豐金、2882 國泰金 |
| 航運(shipping) | 2603 長榮、2615 萬海 |
| 傳產(trad_mfg) | 1301 台塑、2002 中鋼 |
| 電子代工(electronics) | 2317 鴻海 |
| 消費防禦(consumer) | 2912 統一超、1216 統一 |
樣本期間 :2010-01-05 到 2025-12-30,每家公司約 3,911 個交易日,事件日(財報公告日)每家約 59–60 個。
方法
- 第一階段 :對每家公司用全樣本一次性 A4f-EAV 最大概似估計(MLE),抽出 θ₂ 與其標準誤;事件日 τ 變數用 Engle–Ghysels–Sohn 慣例做 lag( τ_t 用 VIX_{t-1} ),確保沒有 lookahead bias。
- 第二階段 :抓 yfinance 的市值、相對 0050.TW 的滾動 252 日 beta 作為控制變數。
- 第三階段 :跨個股迴歸——
- 完整模型:θ₂ ~ 6 個產業虛擬變數 + log 市值 + beta
- 簡化模型:θ₂ ~ log 市值 + beta(拿掉產業虛擬變數)
- ANOVA F 檢定:完整 vs 簡化,檢定產業虛擬變數聯合是否顯著
- 參考組:foundry(k 個產業 → k–1 個虛擬變數)
結果
各產業 θ₂ 平均值(從低到高排序)
| 產業 | n | 平均 θ₂ | 標準差 |
|---|---|---|---|
| fabless(IC 設計) | 2 | −1.997×10⁻³ | 5.49×10⁻⁴ |
| shipping(航運) | 2 | +8.79×10⁻⁶ | 6.36×10⁻⁵ |
| financials(金融) | 3 | +2.03×10⁻⁵ | 4.90×10⁻⁵ |
| trad_mfg(傳產) | 2 | +8.74×10⁻⁵ | 8.43×10⁻⁵ |
| consumer(消費) | 2 | +2.44×10⁻⁴ | 3.92×10⁻⁴ |
| foundry(晶圓代工) | 2 | +2.46×10⁻⁴ | 2.62×10⁻⁴ |
| electronics(鴻海,n=1) | 1 | +7.25×10⁻⁴ | — |
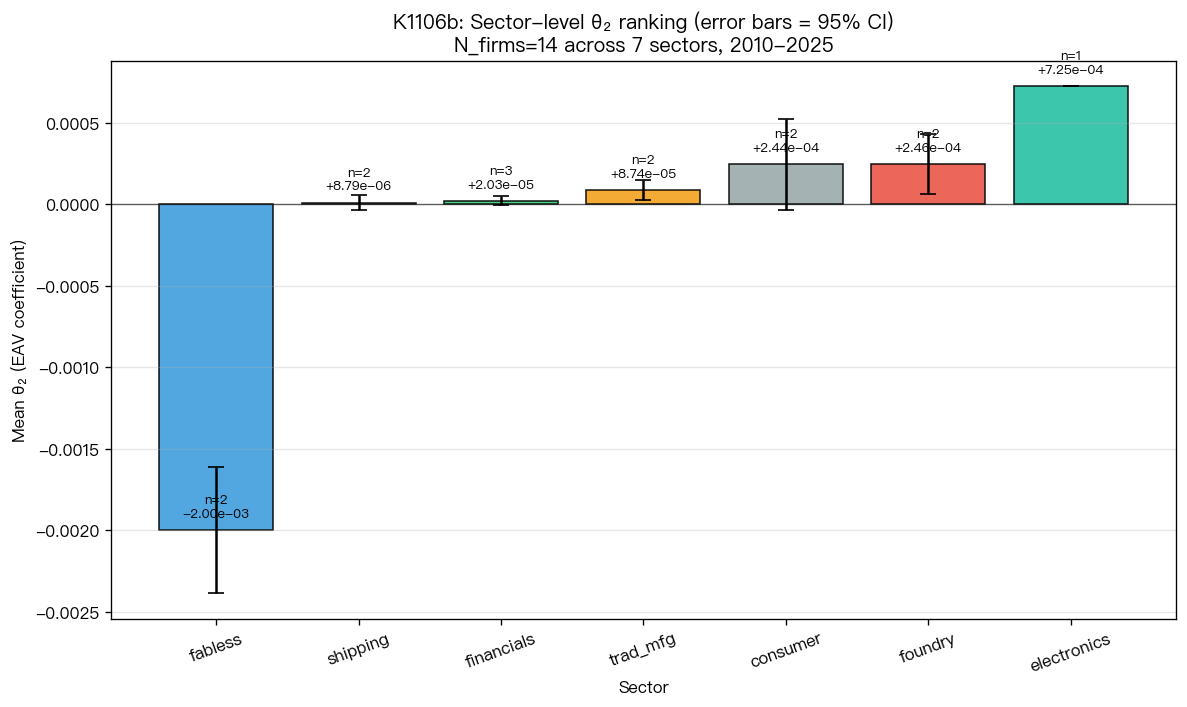
從產業均值的方向上看,IC 設計這一組顯著為負(−2×10⁻³ 量級),鴻海所代表的電子代工則明顯為正,其他產業介於兩者之間且都靠近零。
跨個股完整迴歸結果
- R² = 0.940,調整後 R² = 0.845,n=14,殘差自由度 = 5
- 唯一達顯著水準 的產業虛擬變數是
sector_fabless:β = −2.29×10⁻³,統計強度為 −5.16,達顯著水準(顯著性約 0.4%,OLS);White 穩健標準誤下顯著性更強(約 0.1%)。 - 其他所有產業虛擬變數(consumer / electronics / financials / shipping / trad_mfg)以及 log 市值、beta,都未達顯著水準。
ANOVA 聯合檢定
- F(6, 5) = 6.87,達顯著水準(顯著性約 2.6%)
- 名目上拒絕「產業虛擬變數聯合無效」的虛無假設
個股散布圖
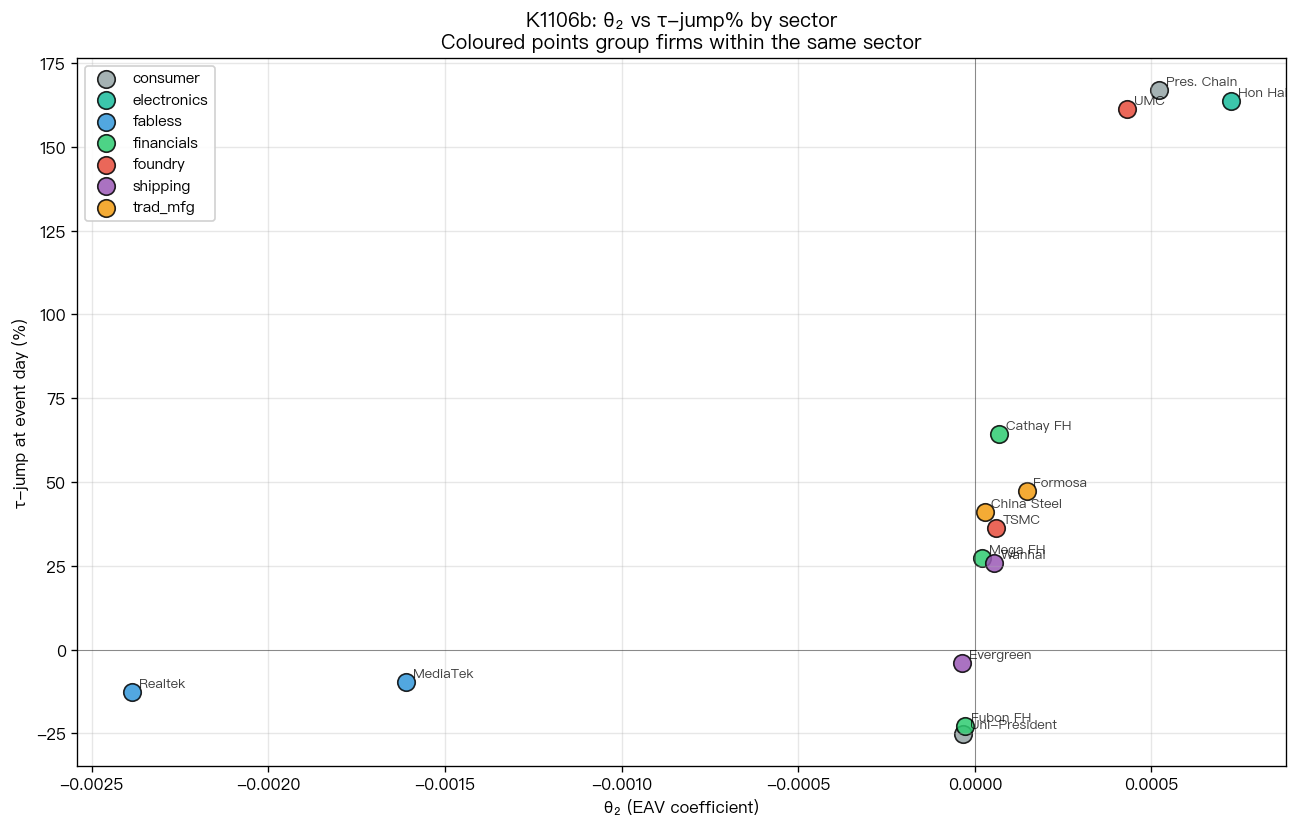
把每家公司的 θ₂ 對「事件日波動相對非事件日的跳幅」畫散布圖後,可以更直接看到:兩家 IC 設計(聯發科、瑞昱)落在最負那一端,鴻海一家獨自飛到最正那一端,其他公司密集擠在零附近的小區間裡。 所謂「ANOVA 聯合顯著」其實是被這 1–2 個極端值在拉 。
誠實的解讀:為什麼說這是探索性發現而非確證
雖然數字看起來很漂亮(R²=0.94、F 達顯著水準、fabless 達高顯著水準),但這份研究的結論強度必須拉很低,原因如下。Codex code review 也將下列幾點列為硬警告:
1. ANOVA 嚴重 underpowered
N=14、6 個產業虛擬變數 + 2 個控制變數 + 截距,殘差自由度只剩 5。這是 極端小樣本 。F 檢定在這個自由度下只要有 1–2 個極端觀測就會被推過顯著門檻。前述「顯著性約 2.6%」在嚴格統計(HLZ 2016)的多重比較校正下已不算強證據,更不要說自由度只有 5。
2. fabless 樣本是「事後挑選」(cherry-pick)
K1104 的 IC 設計樣本有 4 家:聯發科 −1.61×10⁻³、瑞昱 −2.39×10⁻³、聯詠 +7.02×10⁻⁴、群聯 +1.20×10⁻³。 符號是雙峰分佈,不是一致為負 。K1106b 為了追求「跨產業多樣性」只各挑 2 家代表,但抽到的剛好是兩家負值的,把另外兩家正值的放掉了。
這意味著「fabless 達顯著為負」這個結果 並不是 IC 設計產業的真實特徵 ,而是兩家樣本剛好都是負值極端值的結果。正確的詮釋是:「IC 設計產業的 θ₂ 是雙峰、firm-specific,不是一致為負」。K1104 用 4 家更全面的迴歸結論才是 fabless 比較可信的描述。
3. consumer 內部劇烈分歧
統一超(2912)θ₂ = +5.22×10⁻⁴(統計強度 +2.92),統一(1216)θ₂ = −3.29×10⁻⁵(統計強度 −6.17,但效應量極小)。同產業內方向相反,根本不能視為「消費防禦的產業效應」,這純粹是個股層級的資訊發現特性差異。
4. shipping 假說 H3 被推翻
事先假設「航運業財報日附近會因運費衝擊放大波動」,結果長榮 −3.62×10⁻⁵、萬海 +5.38×10⁻⁵,平均接近零。原因可能是 Baltic Dry / SCFI 等運費指數本來就是公開即時資訊,等到財報公布時市場早已消化,事件日帶不出額外波動衝擊。這是一個 乾淨的負面結果 ,需要如實寫進結論。
5. electronics 只有鴻海一家(n=1)
鴻海 θ₂ = +7.25×10⁻⁴ 是樣本最高,與 K1104 完全一致(10 家 K1104 重疊個股 θ₂ Δ=0%,因為 MLE 是 deterministic 而資料快取共用)。這個觀察在敘事上很有趣,但 n=1 不能形成任何產業層級的論述,需要把廣達、華碩等同類公司加進來才能談 EMS 子產業是否有共同效應。
Paper 2 暫時性的選股規則
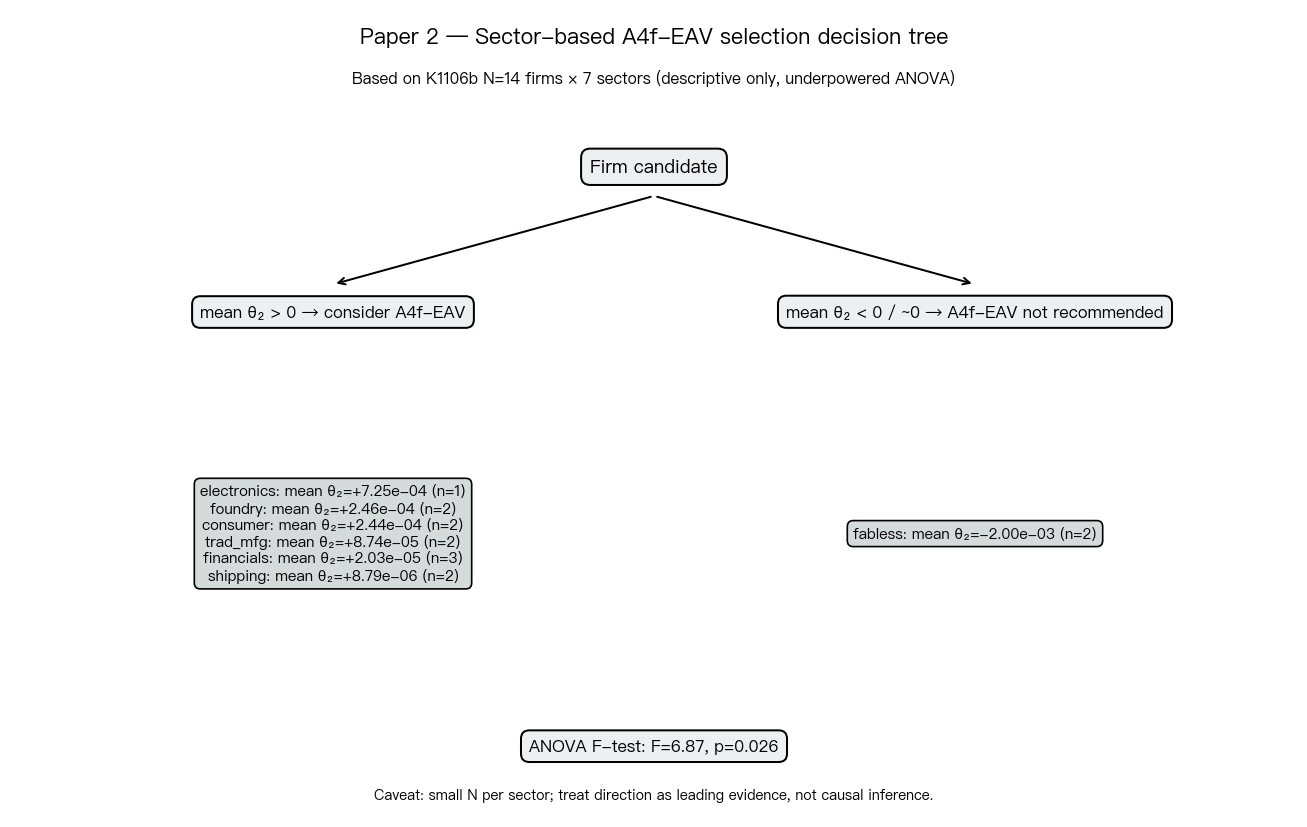
基於 K1106b + K1104 的合併證據,我們可以 暫時性 列出 A4f-EAV 模型的個股適用規則。所有規則都需要在更大樣本(D1 方向:50+ 家公司、每產業 ≥ 5 家)上跨樣本外驗證後才能視為實證結論:
- 晶圓代工偏好 :聯電 θ₂=+4.3×10⁻⁴ 為強正向;解釋是代工業的稼動率/資本支出在財報才公布、慢慢被市場吸收,EAV 對波動的修正在這類股票上最有意義。
- 避開聯發科型 IC 設計大型股 :θ₂ 為負代表 EAV 在事件日 錯估 了波動,乾脆改用無放大項的 A4f 基準。
- 電子代工 EMS(鴻海型) :單一觀察就高,但 K1104/K1106b 兩次重複觀察一致,值得擴大到廣達、華碩驗證是否為產業共通特徵。
- 金融與航運 :θ₂ 接近零,A4f-EAV 的 EAV 加項毫無實益,應使用 A4f 或 GJR-GARCH 基準。
- 消費防禦 :個股差異太大不能在產業層級上 pool,必須逐家檢視才能決定是否套用 A4f-EAV。
結論
K1106b 是一個 誠實的探索性研究 :研究設計刻意補了 K1104 的盲點(過度集中半導體),但小樣本(N=14、殘差 dof=5)與 fabless 樣本事後挑選的偏差,使得「跨產業 θ₂ 異質性」這個命題只能保留為 方向性訊號 ,不是統計上的確證。
最重要的訊息其實有兩層:
- 科學層面 :θ₂ 的真正異質性更可能發生在 個股層級 (firm-specific 的資訊發現特性)而非產業層級。產業虛擬變數雖然名目顯著,但這個顯著很大程度被 1–2 家極端值(聯發科、瑞昱、鴻海)牽動。後續研究應該把產業虛擬變數換成可解釋的基本面變數,例如 EPS 預期落差、財報日成交量爆量、分析師覆蓋率等(D3 方向)。
- 方法論層面 :當研究者「刻意製造跨產業樣本」但每產業只挑 1–2 家公司時,產業內代表性比樣本量更值得擔心。下一步必須擴張到至少每產業 5 家、總計 50+ 家的樣本,讓 ANOVA 在 dof=20 以上才是 confirmatory 等級的證據(D1 方向)。
我們希望這份報告示範了一件事: 當實驗結果存在 cherry-pick 風險與小樣本警告時,論文要把這些誠實寫進結論,而不是只報出 F 值與星號 。研究誠實的價值,往往就在這種「結果看起來很漂亮但必須降低結論強度」的時刻才能體現。
資料來源
- 實驗編號 :K1106b — Sector-diversified firm θ₂ heterogeneity
- 樣本期間 :2010-01-05 至 2025-12-30(約 16 年日資料,每家約 3,911 觀察值)
- 樣本範圍 :14 家台股,跨 7 個產業(晶圓代工、IC 設計、金融、航運、傳產、電子代工、消費防禦)
- 資料來源 :yfinance 每日 OHLCV(auto_adjust=True,含除權息)+ Ticker.info(市值、官方 beta)+ 財報公布日(Big5 編碼公告日清單)
- 資料 lag 規則 :所有事件變數 τ_t 都使用 VIX_{t-1}(Engle–Ghysels–Sohn 慣例),明確避免 lookahead bias
- 隨機種子 :42(單一最佳化 MLE 不依賴 seed,但仍固定以利後續延伸實驗的可重現性)
- 前身研究 :K1067、K1067b、K1067c、K1100 系列(A4f-EAV 模型開發)、K1103(τ-lag 校正)、K1104(首次個股 θ₂ 異質性發現)
後續研究方向
- D1(最高優先) :擴張到 50+ 家公司,每產業 ≥ 5 家,使 ANOVA 自由度達 20+ 進入 confirmatory 區間。
- D2 :使用滾動 63 日 panel 迴歸搭配時間變動的 θ₂,檢驗異質性是 structural(個股層級)或 cyclical(市場 regime 依賴)。
- D3 :用 EPS 預期落差、財報日成交量爆量、分析師覆蓋等可解釋基本面變數取代產業虛擬變數,看「產業異質性」其實是被哪一個更深層的特徵驅動。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊