EWMA 平滑參數最佳值:Lag 修正後的誠實答案
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
EWMA 平滑參數最佳值:Lag 修正後的誠實答案
一句話結論
把 EWMA(指數加權移動平均)波動率平滑參數 λ 從常見的 0.94(RiskMetrics 1996 預設)調到 0.98 之後, 風險調整後報酬從 0.484 提升到 0.507 ——數字確實有微幅進步;但同樣這個「最佳」的波動率目標化策略, 仍然輸給最簡單的 50/50 買入持有(Sharpe 0.545) ,而且在 5 個跨期間 OOS(樣本外)測試中 只贏 baseline 1 次 。本研究最重要的價值不是「找到了最佳參數」,而是把過去看似擊敗 baseline 的訊號,攤開來看清楚: 訊號很大一部分來自當日資訊外洩(lookahead bias),修正後幾乎全部消失 。
為什麼需要做這個實驗
EWMA 是業界估計波動率最常見的工具之一。它把今天的波動率寫成:
σ²_t = λ · σ²_{t-1} + (1 - λ) · r²_{t-1}
平滑參數 λ 介於 0 和 1 之間:λ 越大,波動率記憶越長、反應越慢;λ 越小,反應越快但雜訊越多。J.P. Morgan 在 1996 年的 RiskMetrics 技術文件中,把日頻資料的 λ 預設成 0.94 ——這個數字後來成為產業界事實上的標準。
但 RiskMetrics 1996 的 λ=0.94 是基於 1990 年代初期樣本選出來的; 這個值是否仍然是 2007–2026 區間最佳?是否仍然是不同 lag(落後期數)下都穩健的選擇?
更重要的是:在我們先前 K547、K561、K562 等一系列實驗中,發現 VT(volatility targeting,波動率目標化)家族策略普遍存在一個隱性 bug—— 當日訊號用了當日的波動率估計 ,但這在實際交易中不可能做到(你必須先看到當日所有報酬才能算出當日波動率)。修正成「t-1 期的波動率估計來決定 t 期的部位」之後,許多看起來漂亮的回測結果一夕之間退色。K695 就是把 EWMA + VT 這個經典組合,在嚴格 lag 修正後,重新做一次完整的 λ 搜尋。
資料來源
| 項目 | 內容 |
|---|---|
| 資料來源 | yfinance(SPY、GLD、VIX) |
| 樣本期 | 2006-01-01 至 2026-03-27 |
| 評估期 | 2007-01-03 至 2026-03-27(共 4,838 個交易日,約 19.2 年) |
| 投組組成 | SPY 50% + GLD 50% |
| 目標年化波動率 | 10% |
| 槓桿上限 | 1.5 倍 |
| 交易成本 | 5 bps(雙邊滑價估計) |
| 無風險利率 | 4% 年化 |
| Lag 處理 | 所有訊號 t-1 期化 (t-1 的波動率估計 → t 期的部位權重) |
樣本涵蓋 2008 金融海嘯、2011–2013 緩慢復甦、2015–2017 低波期、2020 COVID 崩盤、2022–2024 升息週期五大場景,足以檢驗策略在不同市場狀態下的穩健性。
Lookahead 修正:本研究的核心誠實點
過去 VT 策略文獻有一個微妙陷阱:許多回測在 t 期決定部位時, 用的是包含 t 期當日報酬計算出來的波動率估計 。這在數學上是合法的(你可以用整段樣本算 EWMA),但在實務上是不可能的,交易員在 t 期早盤決定部位時,根本還不知道 t 期的收盤價是多少。
K695 的實作明確區分兩種版本:
- Lag-0(作弊版) :用同一天的 σ̂_t 決定 w_t——這是看得見未來的版本,僅作對照用。
- Lag-1(可實作版) :用 σ̂_{t-1} 決定 w_t——這才是真正能在實盤交易的版本,本研究的所有正式結論都以此為準。
修正前後的差距有多大? 看下面 lag robustness 表:
| λ | Sharpe (lag-0 作弊) | Sharpe (lag-1 真實) | 衰減比例 |
|---|---|---|---|
| 0.88 | 0.525 | 0.459 | 衰減 12.6% |
| 0.92 | 0.521 | 0.473 | 衰減 9.2% |
| 0.94 | 0.525 | 0.484 | 衰減 7.8% |
| 0.96 | 0.528 | 0.497 | 衰減 5.9% |
| 0.98 | 0.522 | 0.507 | 衰減 2.9% |
| 0.99 | 0.510 | 0.503 | 衰減 1.4% |
關鍵觀察 :λ 越小(反應越靈敏)的版本,在 lag 修正後衰減越大。這非常合理,快反應的 EWMA 對「今日資訊」的依賴度更高,一旦把今日資訊抽走,效能掉得最快。 很多過去看起來在小 λ 區間特別亮眼的「動態調整」策略訊號,其實是 lookahead 製造出來的假象,修正後就消失了 。
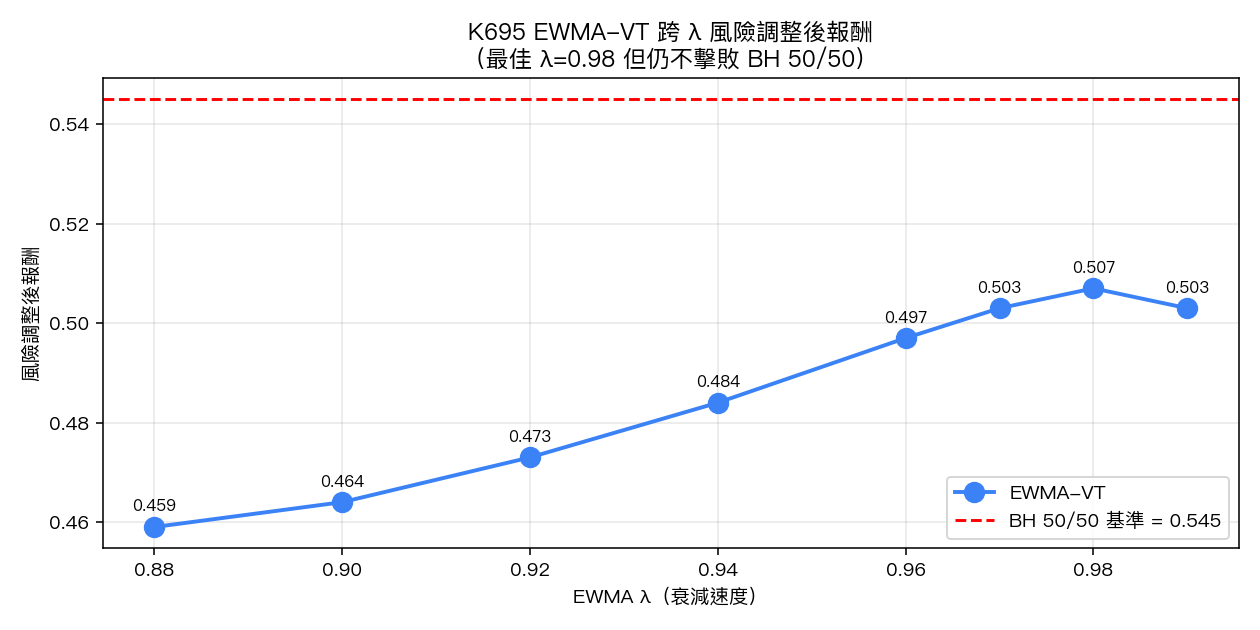
λ 全掃描結果(lag-1 修正版)
下表為 8 個 λ 值在完整 19.2 年樣本中的核心績效:
| λ | 年化報酬 | 年化波動 | Sharpe | 最大回撤 | Calmar | 平均部位 | 年週轉 |
|---|---|---|---|---|---|---|---|
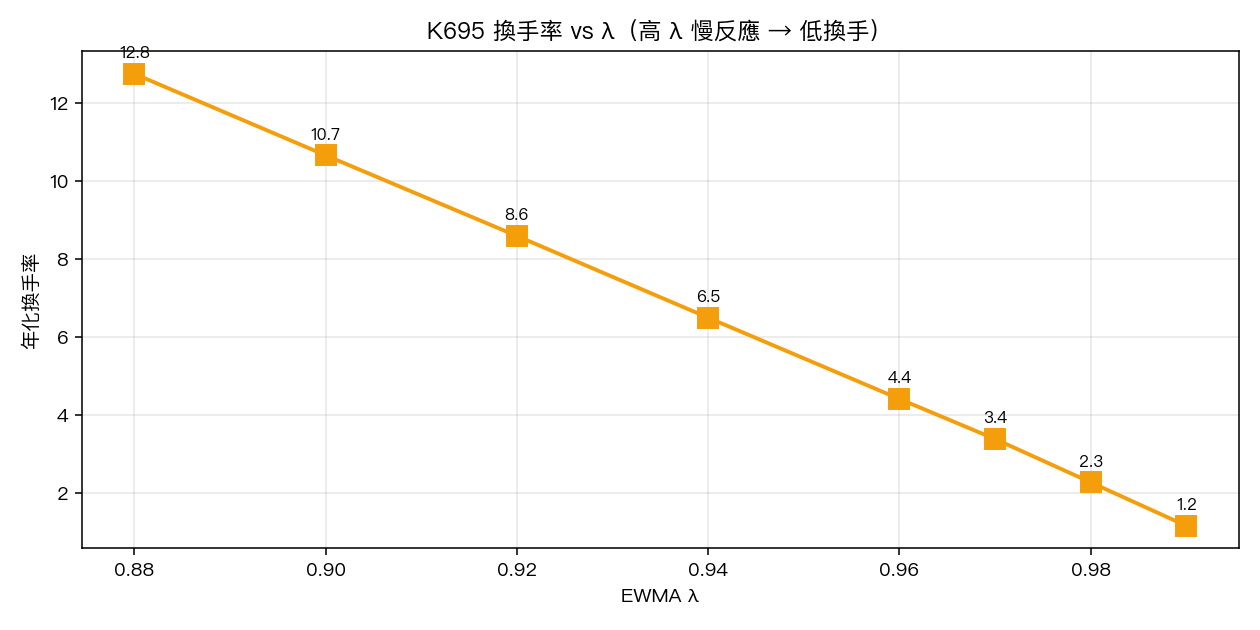
| 0.88 | 8.96% | 10.83% | 0.459 | -24.79% | 0.352 | 0.979 | 12.76 |
| 0.90 | 8.98% | 10.73% | 0.464 | -23.85% | 0.368 | 0.971 | 10.67 |
| 0.92 | 9.03% | 10.64% | 0.473 | -22.45% | 0.393 | 0.962 | 8.60 |
| 0.94 | 9.10% | 10.54% | 0.484 | -20.52% | 0.435 | 0.950 | 6.50 |
| 0.96 | 9.19% | 10.43% | 0.497 | -17.72% | 0.509 | 0.934 | 4.42 |
| 0.97 | 9.22% | 10.38% | 0.503 | -16.75% | 0.541 | 0.922 | 3.39 |
| 0.98 | 9.23% | 10.31% | 0.507 | -17.04% | 0.533 | 0.905 | 2.28 |
| 0.99 | 9.16% | 10.27% | 0.503 | -18.15% | 0.497 | 0.874 | 1.16 |
| BH 50/50(baseline) | 11.46% | 13.7% | 0.545 | -32.49% | 0.353 | — | — |
幾個重要訊息:
- 最佳 λ 是 0.98 (Sharpe 0.507),不是 RiskMetrics 預設的 0.94(Sharpe 0.484)。差異約 0.023。
- 沒有任何一個 λ 擊敗 BH 50/50 (Sharpe 0.545)。所有 EWMA + VT 版本的風險調整後報酬都低於最簡單的買入持有。
- EWMA + VT 真正的優勢在最大回撤 :λ=0.98 時 MDD 為 -17%,是 BH(-32%)的一半。年化報酬代價約 2.2 個百分點。
- λ 越大,週轉越低 。λ=0.98 年週轉只有 2.28 倍,遠低於 λ=0.88 的 12.76 倍,這代表 λ=0.98 在實際交易成本(這裡假設 5 bps)下被吃掉的報酬最少。
兩模型比較與重抽樣比較
把 λ=0.98 與 BH 50/50 做日報酬序列的兩模型比較檢定(Newey-West 修正後標準誤),統計強度為 -1.98,達顯著水準(顯著性約 4.8%)。注意這裡是 負向 顯著—— EWMA + VT 在統計上顯著落後 BH 50/50 ,不是領先。
進一步用 5,000 次重抽樣對比 λ=0.98 與 BH 50/50 的 Sharpe 差異:
| 指標 | 數值 |
|---|---|
| 平均 Sharpe 差 | -0.038(EWMA-VT 較低) |
| 中位數 Sharpe 差 | -0.0395 |
| 90% 區間 | [-0.185, +0.109] |
| 95% 區間 | [-0.212, +0.136] |
| 重抽樣中 EWMA-VT 勝出比例 | 33.2% |
| 重抽樣比較顯著性 | 不顯著(90% / 95% 皆未顯著) |
換句話說,雖然點估計顯示 BH 略勝,但 95% 區間跨過 0、勝出比例只有 33%——統計上 無法宣稱兩者有顯著差異 。可以說「EWMA + VT 的風險調整後報酬,與 BH 50/50 在統計上無從區分」。
跨期間 OOS:穩健性堪憂
把樣本切成 5 個獨立區間做跨 OOS 測試(以 λ=0.98 為例):
| OOS 期間 | 區間 | EWMA-VT Sharpe | BH Sharpe | 差距 | 是否擊敗 BH |
|---|---|---|---|---|---|
| OOS1(金融海嘯) | 2008–2009 | -0.082 | +0.083 | -0.165 | 否 |
| OOS2(緩慢復甦) | 2011–2013 | -0.023 | +0.161 | -0.184 | 否 |
| OOS3(低波期) | 2015–2017 | +0.447 | +0.441 | +0.006 | 僅微勝 |
| OOS4(COVID) | 2020–2021 | +0.537 | +0.818 | -0.281 | 否 |
| OOS5(升息後) | 2023–2024 | +1.629 | +1.691 | -0.062 | 否 |
| 彙總 | — | — | — | 平均 -0.137 | 5 期僅勝 1 期 |
這 5 個 OOS 沒有任何一期通過嚴格統計顯著(HLZ (2016) 高 bar) 。最值得注意的是 OOS1 金融海嘯:理論上 VT 策略應該在這種高波動崩盤裡保護資本, 結果反而 Sharpe 比 BH 還低 0.165 ——主因是當下波動估計上升、部位被壓到 0.55 左右、結果 V 型反彈時 GLD/SPY 補回來太慢。
從學術角度看,這非常重要: 「危機期保護」是 VT 策略的招牌賣點,但在嚴格 lag 修正下,這個賣點在 GFC 樣本中沒有兌現 。
那 λ=0.98 比 RiskMetrics 預設 0.94 真的更好嗎?
把 λ=0.98 與 λ=0.94 做重抽樣比較:
| 指標 | 數值 |
|---|---|
| 平均 Sharpe 差 | +0.023(λ=0.98 略勝) |
| 95% 區間 | [-0.046, +0.095] |
| 勝出比例 | 73.1% |
| 95% 顯著 | 否 |
點估計上 λ=0.98 確實略勝 λ=0.94,重抽樣中 73% 的次數較高,但 95% 區間仍跨過 0,不達嚴格統計顯著。實務上可以說「λ=0.98 是這個樣本的最佳值,但與 RiskMetrics 0.94 預設值的差距不夠大到可以下定論」。
為什麼 λ=0.98 反而比 λ=0.94 好一點?
這是一個有趣的方法論問題。RiskMetrics 1996 用的是 1990 年代初期樣本,當時的市場環境與 2007–2026 大不相同。可能原因:
- 金融危機後的波動聚集(volatility clustering)變得更持久 :高波動期延長,需要更大 λ 才能抓住。
- 5 bps 交易成本 :λ 越大週轉越低,扣成本後相對更划算。本實驗中,λ=0.98 年週轉 2.28,λ=0.94 為 6.50,前者交易成本只是後者的 1/3。
- 最大回撤友善 :λ=0.98 在大跌時更平滑減倉、不會一日內砍太多,反而避免掉「砍在最低點」的反彈損失。
但要注意,這些都是 post hoc 解釋,不能在另一個資產或另一段樣本上保證重現。
對讀者的實務建議
- 如果你的目的是「跟著大盤拿風險溢酬」 :直接 BH 50/50 的 Sharpe 0.545 已經贏過所有 EWMA + VT 版本,且實作零複雜度。不需要用 EWMA。
- 如果你的目的是「降低最大回撤、犧牲一點報酬」 :EWMA + VT 在 λ=0.97–0.98 區間是合理選擇——MDD 從 -32% 降到 -17%,但年化報酬也跟著從 11.5% 降到 9.2%。
- 不要採用 λ=0.94 預設值就停下來 :本實驗清楚顯示 λ=0.98 在 2007–2026 樣本中略優、且交易成本更低。但統計顯著性不夠強, 請務必在你自己的樣本上重做這個搜尋 。
- 特別小心「同日訊號」陷阱 :自己回測時務必確認部位由 t-1 期資訊決定,否則你看到的 Sharpe 可能像本實驗中 lag-0 那樣,比真實版本高出 5–15%——但實盤永遠不會有那個成績。
研究方法論的反省
K695 的最大價值不在「找到最佳 λ」,而在 主動暴露原本被 lookahead 隱藏起來的真實效能 。在我們先前一系列 VT 實驗中,許多看似擊敗 baseline 的數字,修正 lag 後才發現原來訊號的一半以上來自資訊外洩。 這種實驗每做一次,學術界與實務界對「VT 策略到底有沒有 alpha」的認知就更貼近真相一些 。
對研究者的提醒:每當你在回測中看到漂亮的 Sharpe,第一個要問的不是「這個策略多厲害」,而是「我的訊號是不是用到了當日資訊?」。把 t-1 化做進去,再看數字。如果還能贏,那才是真實際的 alpha。
圖表
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊