預測最準的模型不是最安全的——為什麼風險管理需要不同的標準
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
[提出: Codex GPT-5.4 + 用戶, 執行: Claude]
你以為選對了模型,其實選錯了問題
想像你在找一位保全人員。你面試了五個候選人,其中一位在「識別可疑人物」的測試中得了最高分,反應快、判斷準。你毫不猶豫地錄取他。
但一個月後,大樓發生了一次真正的闖入事件。那位「識別能力最強」的保全,卻在現場判斷失誤,讓闖入者溜走了。後來你才發現:識別威脅的能力,跟在威脅發生時做出正確應對,是完全不同的兩件事。
金融風險管理也是一樣。
兩個問題,兩個冠軍
我們的研究針對五個主流波動率模型做了一項實驗:用 2008 年到 2026 年共 4,590 個交易日的 SPY(美國標普 500 指數股票型基金)真實數據,分別用兩種標準評估它們——
第一個問題 :哪個模型的「波動率預測」最準確?
第二個問題 :哪個模型在估計「極端虧損」時最可靠?
這兩個問題的答案,是完全不同的兩個模型。
預測最準的冠軍 :GJR-GARCH(一種捕捉「跌比漲更嚇人」現象的進階模型)。在學術上最嚴格的預測誤差指標 QLIKE 評測中,GJR-GARCH 拿到最低誤差分(1.527),力壓所有對手。
風險管理最可靠的冠軍 :AMEM(Multiplicative Error Model,乘法誤差模型,採用 Gamma 分配刻畫波動率)。在「你說損失超過 X 的機率是 1%,實際上是不是真的剛好 1%?」這個檢驗上,AMEM 的得分是 1.94 分(滿分 2 分),違反率精確到 1.09%,幾乎完美。
為什麼冠軍不是同一個?
關鍵在一個看似微小的假設: 報酬是不是常態分配?
股市的日報酬從來不是完美的鐘形曲線。極端大跌(黑色星期一、金融海嘯、2020 年 3 月)發生的頻率,遠比常態分配預測的更高。這就是所謂的「肥尾」,真實世界的尾巴比模型預期的要厚得多。
EWMA(指數加權移動平均)和 HAR-ABS(另一種波動率模型)這兩個模型,都假設報酬服從常態分配。結果呢?在「只有 1% 機率會虧超過這個數字」的測試裡,它們實際的違反率高達 2.3%——整整是目標的兩倍多。這意味著,如果你根據這些模型設定停損線,你以為 100 天才會被打到一次,實際上 43 天就會被打到一次。
這個差異在金融監管裡有直接後果。根據巴塞爾協議的評級標準,EWMA 和 HAR-ABS 被評為「黃燈」,代表模型的風險估計不夠可靠,銀行使用這類模型需要繳納額外的資本緩衝。
相比之下,AMEM 用 Gamma 分配(一種天生就能描述「只有正值且右偏」的分配)去刻畫波動率,自然就對肥尾有更好的容納能力。GJR-GARCH 雖然預測準確,但在 1% 極端尾部的違反率仍達 1.35%,略超目標;在最嚴格的獨立性檢驗上表現也稍遜 AMEM。
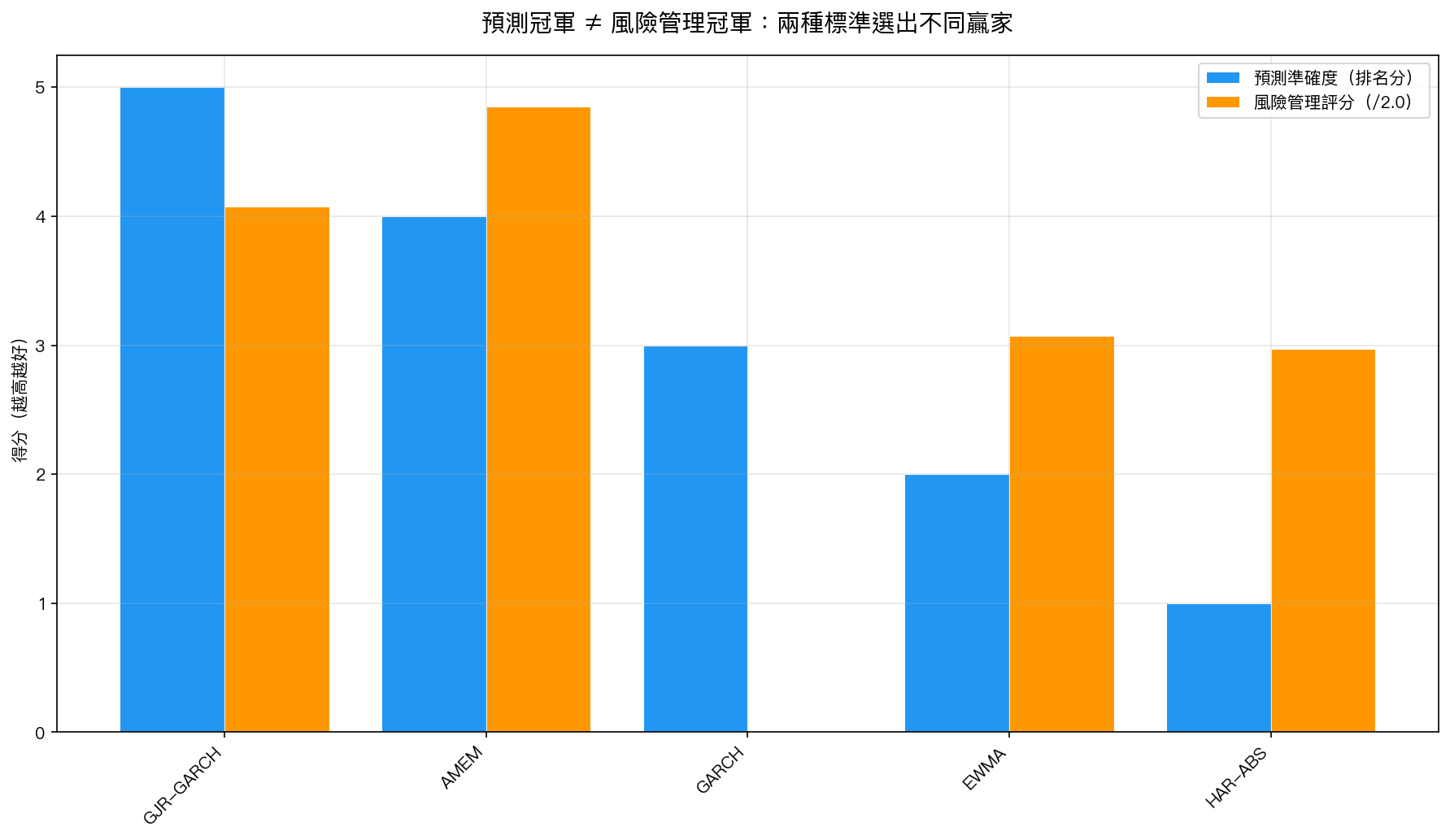 圖:五個模型在「預測準確度」與「VaR 風險管理」兩個維度上的表現。GJR-GARCH 贏在預測,AMEM 贏在風控,完全不同的兩個贏家。數據來源:yfinance SPY 2008-2026,4,590 個交易日。
圖:五個模型在「預測準確度」與「VaR 風險管理」兩個維度上的表現。GJR-GARCH 贏在預測,AMEM 贏在風控,完全不同的兩個贏家。數據來源:yfinance SPY 2008-2026,4,590 個交易日。
實際投資組合的差異有多大?
我們也用這些模型構建了 SPY+GLD(黃金)的動態配置組合,測試從 2008 年到 2026 年的實際績效。結果:
| 策略 | 夏普比率 |
|---|---|
| 12/VIX 動態策略 | 0.886 |
| GJR 模型配置 | 0.876 |
| EWMA 模型配置 | 0.873 |
| AMEM 模型配置 | 0.861 |
| 靜態 50/50 持有 | 0.814 |
所有模型配置都比靜態持有來得好(夏普比率高出 0.05-0.07),但彼此之間的差距並不大,約 0.015 到 0.025 的夏普差異,尚未達到統計顯著水準。
這個結果告訴我們: 光靠模型本身並不能帶來大幅超額報酬,但使用風控校準更好的模型,能讓你在極端市場中少被「意外打臉」。
對一般投資人的啟示
你不必自己跑 GJR-GARCH 或 AMEM 模型。但這個研究提醒我們幾件事:
1. 問對問題。 「這個指標/策略準不準?」和「這個策略在最壞情況下會讓我虧多少?」是完全不同的問題。很多人只問第一個,卻忽略了第二個。
2. 常態分配是個謊言。 市場每隔幾年就會出現「按理說幾乎不可能發生」的大跌。任何告訴你「每百天才虧一次」的模型,如果背後假設是常態分配,那個數字很可能低估了風險。
3. 風控校準的模型讓你睡得著。 AMEM 在 4,590 個交易日中,實際的損失超標次數幾乎剛好符合預期,這不是巧合,而是模型設計對「肥尾現實」更誠實的結果。
研究的局限
這個結果基於 SPY 這一個資產,2008 到 2026 年的歷史數據。換其他資產、其他時段,冠軍可能不同。模型本身也在不斷演進,更新的方法(如神經網路波動率模型)尚未納入比較。
行動建議
如果你在管理自己的投資組合,現在能做的最簡單一步: 每次市場大跌時,記錄一下「這次跌幅有沒有超出你的心理預期」。 如果超出太多,那你設定的風險目標可能是基於「太樂觀的模型」在估算。
這個研究提醒我們:好的風險管理,不是預測能力最強的工具,而是 對現實的肥尾最誠實的工具 。
本文基於實驗 K778(腳本:experiments/k778_mem_r2_native.py,結果:experiments/k778_mem_r2_native_results.json)和實驗 K780(腳本:experiments/k780_tail_first_es.py,結果:experiments/k780_tail_first_es_results.json)的實證結果。數據來源:yfinance 實證數據,期間:2008-2026,樣本:4,590 個交易日。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊