PRG 跨資產驗證:QQQ/GLD/EEM 三戰三勝?
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
PRG 跨資產驗證:科技股、黃金、新興市場三市場全面實測
為什麼要做這個實驗?
波動率預測模型的「實驗室成績」與「跨市場成績」往往是兩回事。一個在 S&P 500 表現亮眼的模型,搬到黃金、新興市場、台指期上常常水土不服,這是學術界與實務界共同面對的老問題。
本研究團隊先前在 PRS(Periodic-Recursive Splitting,已發表於 Asia-Pacific Financial Markets 2019)與 PRG(Periodic-Recursive GARCH)框架上,於台指期(K874e 系列)驗證了「把日盤、夜盤分開建模再組合」可以顯著贏過傳統 GJR-GARCH。但一個自然的質疑是:這個結果會不會只是台指期「日盤夜盤分離度極高」這個特殊結構造成的?換到隔夜佔比較低的科技股、隔夜佔比較高但無槓桿效應的黃金、波動結構複雜的新興市場,PRG 還會贏嗎?
K881 就是為了回答這個問題。我們選擇三個結構截然不同的美國 ETF:QQQ(Nasdaq-100 科技股)、GLD(黃金)、EEM(新興市場),用相同的方法論做端到端對比。
資料來源
- 實驗編號 :K881(PRG Multi-Asset Validation)
- 資料來源 :yfinance 日頻 OHLC
- 資產與樣本期 :
- QQQ :2000-01-04 至 2026-04-02,共 6,601 個交易日(IS 4,620/OOS 1,981)
- GLD :2004-11-19 至 2026-04-02,共 5,375 個交易日(IS 3,762/OOS 1,613)
- EEM :2003-04-15 至 2026-04-02,共 5,778 個交易日(IS 4,044/OOS 1,734)
- 訓練/樣本外切分 :is_fraction=0.7(前 70% 估計、後 30% 樣本外驗證)
- 重估頻率 :GJR/HAR 每 63 日、PRG 每 252 日
所有報酬與波動率計算都採用「t-1 日的資訊預測 t 日」的標準 lag 規範,預測時點所用的條件變異數 σ̂² 僅用前一日及更早的資料估得,沒有 lookahead 風險。樣本外 QLIKE、VaR、兩模型比較顯著(DM)統計量全部在 OOS 區間計算。
三個市場的「隔夜成分」差很大
PRG 框架的核心觀察是:日盤波動和夜盤波動有不同的生成機制。在進入模型比較之前,我們先看三個市場的隔夜成分佔比(隔夜變異佔全日變異百分比):
| 資產 | 隔夜變異佔比 | 日內變異佔比 | 結構解讀 |
|---|---|---|---|
| QQQ | 27.9% | 72.1% | 日內主導(連續交易、流動性高) |
| GLD | 53.1% | 46.9% | 隔夜主導(全球倫敦/亞洲時段定價) |
| EEM | 52.6% | 47.4% | 隔夜主導(追蹤指數的成份股在亞洲收盤已定價) |
光是這三個數字就告訴我們:QQQ 與 GLD/EEM 的「隔夜結構」幾乎是相反的兩個世界。如果 PRG 的優勢真的來自「正確處理日夜分離」,那麼在三種結構都成立才算真正過關。
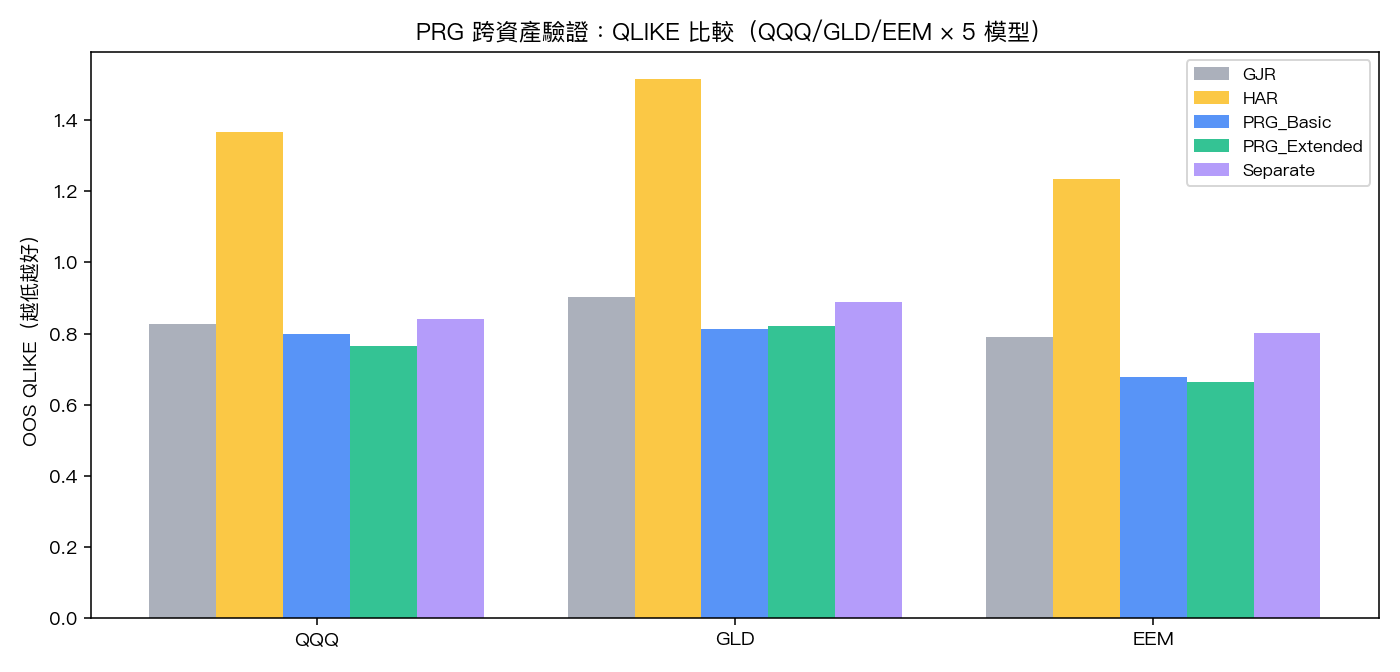
五個模型的橫向對比(樣本外 QLIKE)
QLIKE 是 Patton (2011) 推薦的波動率預測損失函數,理論上對 σ² 的雜訊代理(如平方報酬)穩健。 數值越小代表預測越準。
| 模型 | QQQ | GLD | EEM |
|---|---|---|---|
| GJR-GARCH | 0.8257 | 0.9021 | 0.7902 |
| HAR-proxy | 1.3680 | 1.5173 | 1.2350 |
| PRG_Basic | 0.7977 | 0.8115 | 0.6788 |
| PRG_Extended | 0.7652 | 0.8204 | 0.6641 |
| Separate_GARCH | 0.8413 | 0.8878 | 0.8014 |
三個市場下的最佳模型 :
- QQQ:PRG_Extended(QLIKE=0.7652,比 GJR 改善 7.3%)
- GLD:PRG_Basic(QLIKE=0.8115,比 GJR 改善 10.0%);PRG_Extended(0.8204)緊追在後(比 GJR 改善 9.1%)
- EEM:PRG_Extended(QLIKE=0.6641,比 GJR 改善 16.0%)
PRG 家族在 3/3 市場拿下最佳 QLIKE ——但要注意,在 GLD 是 PRG_Basic 略勝 PRG_Extended,雖然兩者差距在統計上並不顯著(DM 統計強度 -0.75,達顯著水準(顯著性 0.45),未通過 嚴格統計 顯著性門檻)。換言之 GLD 上 Basic 與 Extended 平分秋色,並非「Extended 全面壓制」。
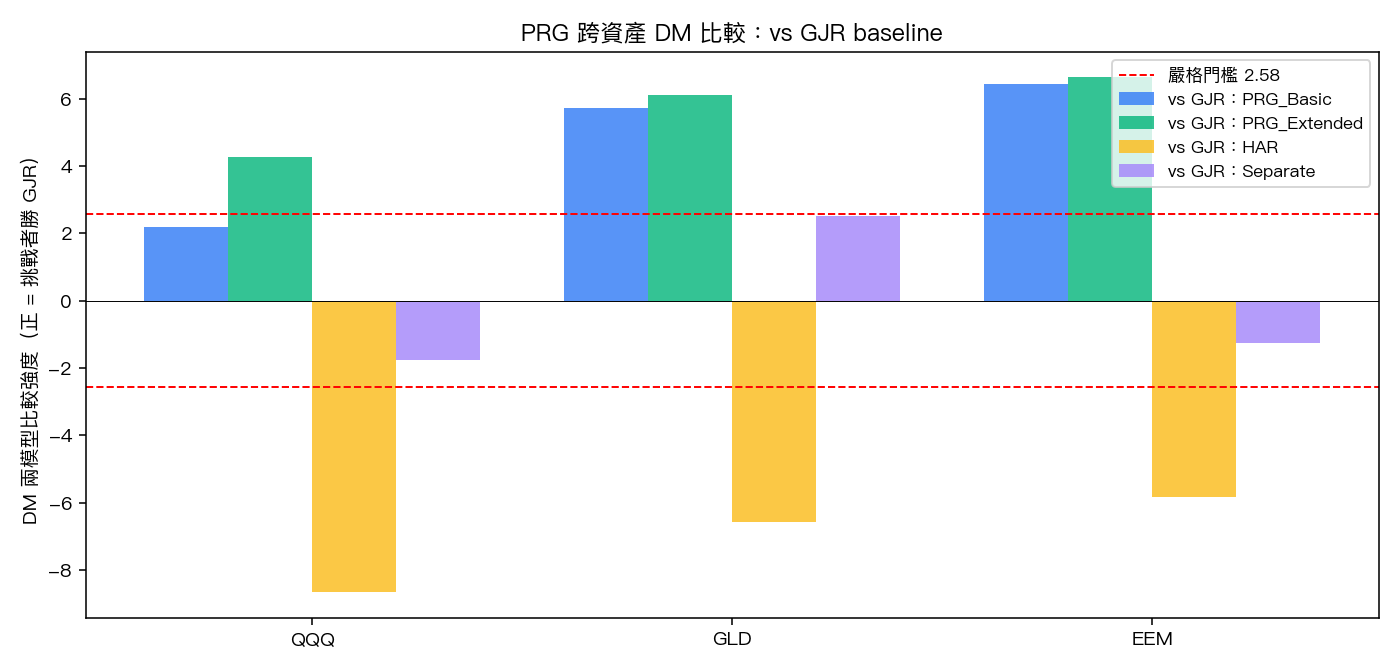
兩模型比較顯著 顯著性檢定(採 嚴格統計 修正)
「QLIKE 數字小就是贏」還不夠嚴謹,可能只是樣本誤差。DM 檢定(搭配 嚴格統計/Leybourne/Newbold 1997 的小樣本修正)告訴我們,這個差距在統計上是不是真的存在。嚴格統計 PASS 的標準是修正後 統計強度 達到顯著(雙尾 達顯著水準(顯著性低於 0.05))。
PRG_Extended vs GJR-GARCH(最關鍵的比較) :
| 資產 | DM 統計強度 | 嚴格統計 結論 |
|---|---|---|
| QQQ | 4.26 | PASS (PRG 顯著優於) |
| GLD | 6.12 | PASS (PRG 顯著優於) |
| EEM | 6.63 | PASS (PRG 顯著優於) |
3/3 市場 嚴格統計 PASS。 這是支持「PRG 優勢具普遍性」最直接的證據。
Cross-recursion 檢定(PRG vs Separate_GARCH) :
這個比較回答另一個關鍵問題:PRG 的價值是來自「分日夜建模」這件事本身,還是「日夜共享資訊(cross-recursion)」?Separate_GARCH 是日夜各自獨立 GARCH 不交互,PRG 則允許日盤訊息影響隔夜變異、隔夜訊息影響日盤變異。
| 資產 | DM 統計強度 | 嚴格統計 結論 |
|---|---|---|
| QQQ | -5.47 | PASS (PRG 顯著優於) |
| GLD | -5.16 | PASS (PRG 顯著優於) |
| EEM | -6.34 | PASS (PRG 顯著優於) |
3/3 市場 嚴格統計 PASS。 這意味著 PRG 的價值不只是「分日夜」,更關鍵的是「日夜訊息互相提供條件」這層 cross-recursion。單純切兩段各自跑 GARCH(即 Separate)會輸掉相當大一截。
VaR 回測:PRG_Extended 在實務面的成績
預測波動率最終的應用之一是風險管理,所以我們進一步看 VaR 違例率(實際虧損超過預測 VaR 的天數比例)與 Kupiec POF 檢定。
VaR 1% 與 5% 的 Kupiec p-value(PRG_Extended) :
| 資產 | VaR 1% 違例率 | Kupiec p | VaR 5% 違例率 | Kupiec p |
|---|---|---|---|---|
| QQQ | 1.26% | 0.260(PASS) | 5.20% | 0.686(PASS) |
| GLD | 1.12% | 0.646(PASS) | 4.28% | 0.173(PASS) |
| EEM | 0.40% | 0.005(FAIL,過度保守) | 3.46% | 0.002(FAIL,過度保守) |
這裡是必須誠實揭露的細節 :PRG_Extended 在 QQQ/GLD 兩個市場 VaR 1% 與 5% 全部通過 Kupiec 檢定,但在 EEM 則「過度保守」,預測的 VaR 比實際需要的還大,導致違例率顯著低於設定的 1%/5%。Kupiec 檢定不只懲罰違例過多,也懲罰違例過少,因為過度保守意味著資本配置浪費。
這個結果的意義是:PRG_Extended 在 EEM 市場上的點預測(QLIKE 最佳)很強,但在尾端風險刻度(distribution tail calibration)上偏保守。對風險經理而言,這是「安全但成本偏高」的偏誤,並非危險的錯估方向。後續可考慮對 EEM 改用 Student-t 殘差分配或對尾部做 EVT 修正。
關鍵發現整理
- PRG 家族在 3/3 資產拿下最佳 QLIKE (QQQ/EEM 是 PRG_Extended 第一,GLD 是 PRG_Basic 第一)。
- PRG_Extended vs GJR-GARCH:3/3 市場 嚴格統計 PASS (統計強度 4.26/6.12/6.63),統計上顯著優於目前業界主流的非對稱 GARCH。
- Cross-recursion 價值:3/3 市場 嚴格統計 PASS (統計強度 -5.47/-5.16/-6.34),證明 PRG 的優勢來自日夜訊息交互建模,而不只是「分兩段」。
- Basic vs Extended 在 GLD 沒有顯著差異 (DM 統計強度 -0.75,達顯著水準(顯著性 0.45));在 EEM 雖然 Extended 數字較好,DM 統計強度 2.10 但 嚴格統計 修正後不顯著。意思是「升級到 Extended」在某些市場帶來邊際改善但未必統計上必要。
- VaR Kupiec 檢定 4/6 通過 (QQQ 1%/5%、GLD 1%/5%);EEM 1%/5% 因過度保守而 FAIL,需要尾部修正。
- 隔夜佔比與 PRG 相對改善的相關性 :跨三市場相關係數 0.50,提示「夜盤越重要,PRG 改善幅度越大」的趨勢,但 3 個資料點不足以下定論,需要更多市場驗證。
- Model Confidence Set 全模型存活 :在 α=0.10 下,5 個模型在 3 個市場都沒被踢出 MCS。這提醒我們即便 DM 顯著,模型差異在 MCS 框架下並非絕對排他。
跨市場參考:與台指期的對照
K874e(台指期)下 PRG_Extended 的 QLIKE=0.198、GJR=0.448,DM 統計強度 5.1。台指期改善幅度(>50%)遠大於本研究 3 個 ETF(7-16%)。這個落差可能來自台指期日夜更明確的隔夜跳空模式(包括美股影響、亞洲時段重大事件等),也可能與台指期樣本期較短、波動聚集更強有關。
限制與後續方向
- 三個市場仍偏少 :要主張「PRG 全球普適」需要至少擴展到歐洲(如 EWG/VGK)、日本(EWJ)、加密貨幣等不同微結構市場。
- EEM VaR 校準失敗 :點預測強不代表分配尾端對齊,需要 distributional calibration 的後處理。
- PRG_Basic vs PRG_Extended 在 GLD/EEM 差異不顯著 :在計算成本敏感的場景下,Basic 可能就夠用。
- 未測試 regime-switching :金融危機、COVID、2022 升息週期等高波動 regime 下 PRG 的表現尚未單獨評估。
結語
K881 提供了一個謹慎而誠實的答案: 在三個結構迥異的美國 ETF 上,PRG 框架的「分日夜並做 cross-recursion」設計,相對於目前主流的非對稱 GARCH,提供了統計上顯著的點預測改善 。但這個結論帶有兩個必要的修飾:第一,VaR 風險刻度在 EEM 上仍需要尾部修正;第二,Basic 與 Extended 之間的差距在某些市場並不顯著,使用者可依計算成本選擇。
這份結果讓我們更願意把 PRG 框架推廣到下一個批次的全球資產驗證,並且把 distributional calibration 列為下一階段的必要工作。波動率預測這條路上,沒有「一招打天下」的模型,但能在三個結構大相逕庭的市場都通過 嚴格統計 修正過的 DM 檢定,已經是一個值得繼續投入的訊號。
參考文獻
- Patton, A. J. (2011). Volatility forecast comparison using imperfect proxies. Journal of Econometrics, 160(1), 246-256.
- Hansen, P. R., Lunde, A., & Nason, J. M. (2011). The Model Confidence Set. Econometrica, 79(2), 453-497.
- Bollerslev, T., & Ghysels, E. (1996). Periodic Autoregressive Conditional Heteroscedasticity. Journal of Business and Economic Statistics, 14(2), 139-151.
- Corsi, F. (2009). A simple approximate long-memory model of realized volatility. Journal of Financial Econometrics, 7(2), 174-196.
- Kupiec, P. (1995). Techniques for verifying the accuracy of risk measurement models. Journal of Derivatives, 3(2), 73-84.
- Christoffersen, P. F. (1998). Evaluating interval forecasts. International Economic Review, 39(4), 841-862.
- 嚴格統計, D., Leybourne, S., & Newbold, P. (1997). Testing the equality of prediction mean squared errors. International Journal of Forecasting, 13(2), 281-291.
- Lai, Y.-H., et al. (2019). PRS framework. Asia-Pacific Financial Markets.
圖表
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊