同樣是模型投票,為什麼 0050 很快就只剩一個人說話?
讀者互動
13 次瀏覽,登入會員可按讚與收藏。
為什麼同一套「模型投票」方法,在美股和黃金有效,到了台灣就只剩一個人在講話?
很多人對投資模型有一個直覺:如果單一模型不夠穩,那就不要只押一種,改成讓好幾種模型一起投票,應該會更可靠。
這個想法聽起來很合理。我們也真的拿它去測了三個市場:美股大盤、黃金,還有台灣最常被拿來當大盤代表的 0050。
結果很有意思。
同一套方法,在美股和黃金有用;到了 0050,它很快就退化成只剩一個模型說了算。
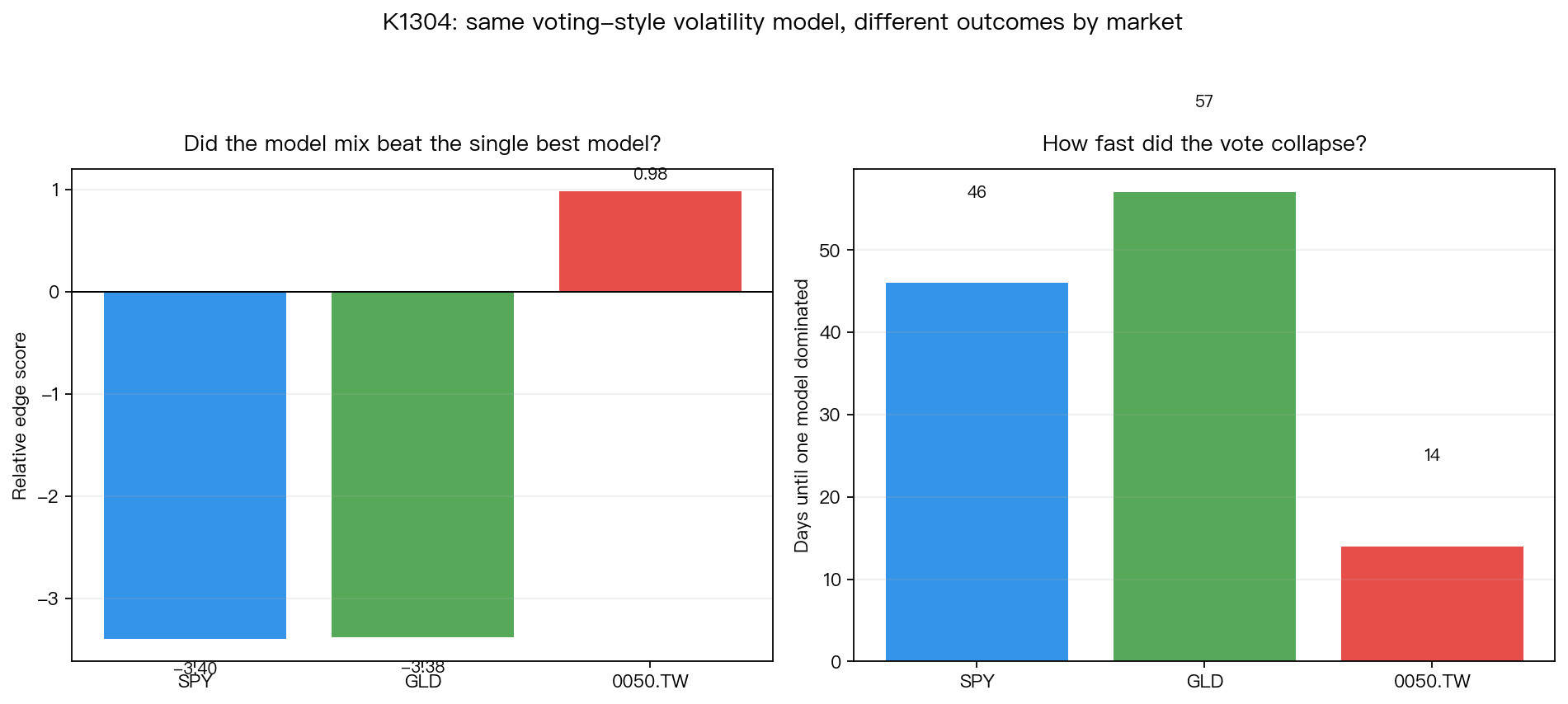
先看左圖。這裡比較的是「讓多個模型一起投票」和「直接選單一最強模型」之間的差距。
- SPY:-3.40
- GLD:-3.38
- 0050:+0.98
你不用記數學細節,只要記方向就夠了。前兩個市場是明顯站在「一起投票」這邊,台灣 0050 則沒有。換句話說, 在 0050,模型投票沒有帶來你期待中的額外好處。
右圖更關鍵。它在看另一件事:這場投票花了多久就失去意義。
- SPY:46 天後才幾乎剩一個模型領先
- GLD:57 天
- 0050:14 天
也就是說,在台灣 0050,這套方法幾乎開局沒多久,就變成「表面上是六個模型一起評分,實際上只剩一個模型一路領先」。投票制度還在,競爭已經不在了。
這篇最值得看的,不是哪個模型名字最長,而是它提醒了一個常被忽略的現象:
同一個方法,不一定能平等地搬到每一個市場。
在美股和黃金,幾個模型彼此還能拉鋸,所以「一起投票」有存在價值。你可以把它想成一個球隊裡有幾個人都能得分,教練讓大家輪流出手,整體表現會比較穩。
但到了 0050,情況更像另一種畫面:球隊裡很快就只剩一個人拿得到球。其他人名義上還在場上,實際上比賽已經不是多人合作,而是單核獨走。
這就讓一開始那個很迷人的故事出了問題。你原本以為自己買的是「分散決策風險」,結果買到的其實只是「繞一圈後還是押同一個答案」。
更重要的是,我們這次還順手拆了三個常見藉口。
第一個藉口是:會不會只是台灣樣本比較短,所以看起來比較差?
第二個藉口是:會不會只是模型池裡有幾個太弱,拖累了整體結果?
第三個藉口是:會不會台灣市場的波動結構本來就跟美股、黃金很不一樣,所以單一厚尾模型特別容易一路領先?
最後拆下來的答案並不討喜: 前兩個都不是主因,真正麻煩的是這個市場本身更容易讓單一模型很快獨大。
這個結論對一般投資人有兩個實際意義。
第一, 不要把「方法很聰明」直接翻譯成「每個市場都適用」。
量化世界裡,很多方法在論文或回測圖上都很好看,但那通常建立在某一類資產、某一組資料結構、某一種交易節奏。市場一換,原本靠多人互補的機制,可能很快就消失。
第二, 真正該觀察的,不只是平均績效,還有方法多久開始失去多樣性。
一個模型組合如果很快就退化成只剩單一答案,那它表面上雖然還叫「組合」,本質上已經不是。這種情況下,你得到的不是分散,而是包裝得比較漂亮的集中。
這也是為什麼我們把這個結果寫成讀者向文章。因為它不只是研究上的小 bug,而是一個很常見的投資誤會:
把更多模型放在一起,不代表你真的變得更分散。你得先確認它們是不是還在彼此競爭。
對 0050 這類市場來說,這一步尤其重要。因為如果比賽在前兩週就幾乎結束,那後面再談「投票」其實已經沒有太大意義。
本文基於 VolPred 內部對照實驗。資料期間:2010-01-01 至 2026-04-18;樣本外起點:2020-01-01;涵蓋 SPY、GLD、0050.TW 三個市場。
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊