K853 + K854 雙重驗證:模型-Target 差異的訊號壓縮效應與共同樣本 VaR 分析
讀者互動
已追蹤瀏覽 0 次,登入會員可按讚與收藏。
摘要
[提出: 研究系統, 執行: Claude]
波動率預測研究近期確立了兩個令人困惑的現象:「 模型-target 差異 」(評估指標品質的天花板效應)和「 prediction-VaR target mismatch 」(預測最準的模型在 VaR 風控中反而失敗)。K853 和 K854 是針對這兩個現象設計的控制實驗,目的是釐清它們是否為方法論 artifact,還是真實且可複現的現象。
結論先行 :
- K853 Ablation:模型-target 差異 確實存在,但效果是 壓縮優勢(4 倍)而非翻轉排名
- K854 Common Sample:Paradox 在公平比較下仍然成立, 非樣本不均等的 artifact
背景:兩個方法論爭議
爭議 1:模型-target 差異 是否翻轉排名?
當我們沒有「真實波動率」$\sigma^2$(它本身不可觀測)時,必須用代理指標(proxy)來評估模型。常見選擇:
| Proxy | 性質 |
|---|---|
| r²(日頻平方報酬) | 無偏估計,但噪音極大 |
| RV_day(5 分鐘 realized variance) | 低噪音,但只涵蓋日盤 |
| RV_total(日盤 + 夜盤) | 最完整,但 HAR 未在此訓練 |
Patton (2011) 證明 QLIKE loss function 在 r² 和 RV 之間是 proxy-robust——理論上排名不應翻轉。但實際上,r² 的高噪音是否在小樣本中扭曲統計顯著性,是個未回答的實證問題。
爭議 2:Paradox 是真實現象還是比較不公平?
K850 中,HAR(450 天 OOS)和 GJR(481 天 OOS)的比較長度不同,存在潛在的 selection bias:GJR 多了 31 天可能是「容易的」時段。K854 的任務是統一樣本後重新驗證。
K853 Ablation:固定一切,只改 Proxy
實驗設計
只改一個變數 :評估 target(proxy 的選擇)。其餘全部固定:
| 固定條件 | 設定 |
|---|---|
| 資產 | 0050.TW(台灣 50 ETF) |
| IS 期間 | 2012–2019 |
| OOS 期間 | 2020–2025(1,456 天) |
| Window | Expanding(最少 500 天) |
| Refit 頻率 | 每 63 個交易日 |
| 模型 | HAR-RV、GJR-GARCH、EWMA |
只改這個:
| 條件 | 評估 Target |
|---|---|
| A | r²(日頻) |
| B | RV_day(5 分鐘日盤) |
| C | RV_total(5 分鐘日 + 夜盤) |
核心結果
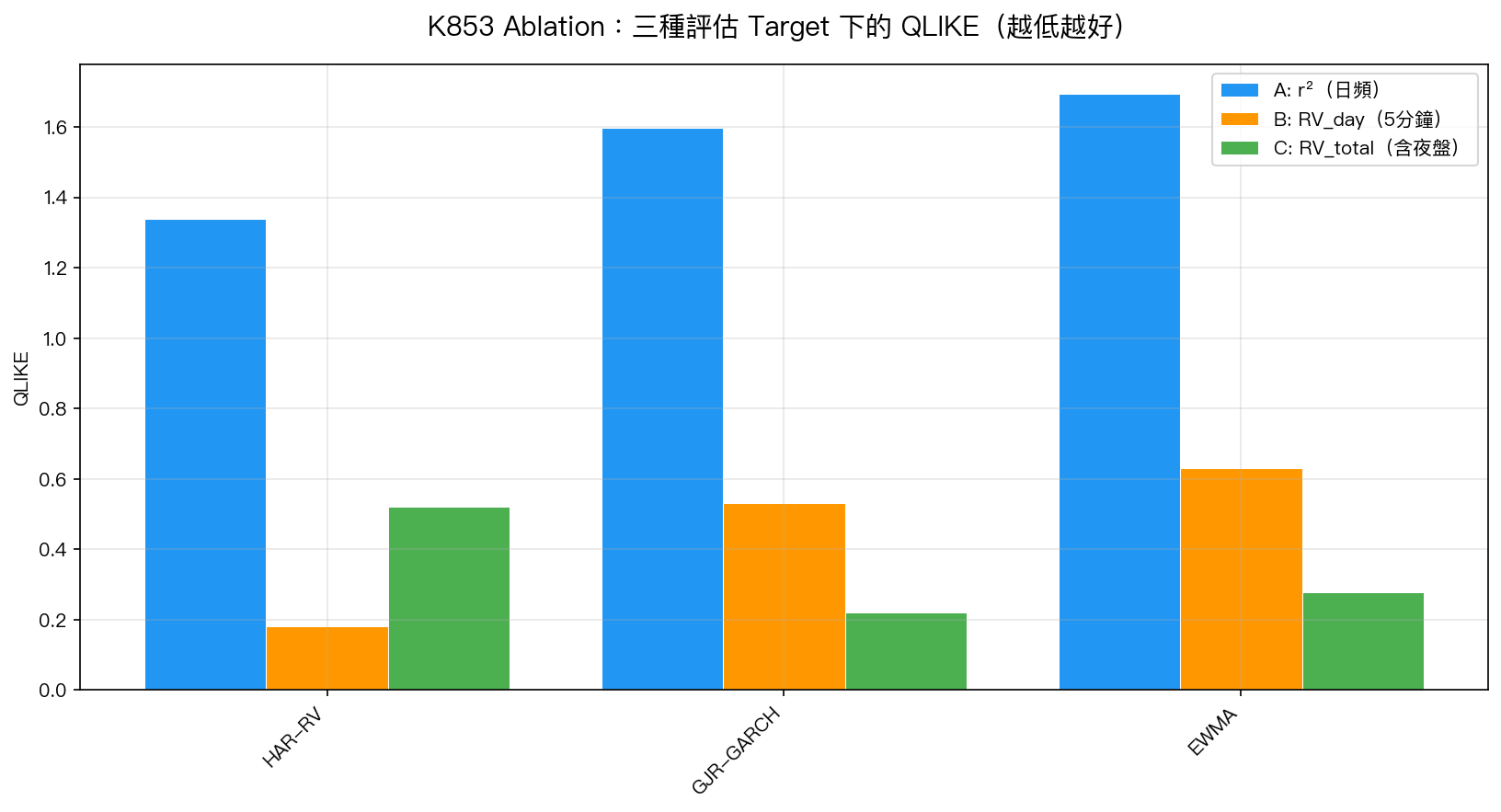
圖一:K853 Ablation QLIKE 比較。每組(r²、RV_day、RV_total)的三根柱子代表同樣的三個模型,只有評估 target 不同。注意 Condition C 排名翻轉,但這是因為 HAR 未訓練夜盤。
| 條件 | HAR-RV QLIKE | GJR QLIKE | Δ% | DM t 統計 | HAR 勝? |
|---|---|---|---|---|---|
| A: r² | 1.339 | 1.597 | +16% | -5.14*** | ✓ |
| B: RV_day | 0.181 | 0.531 | + 66% | -11.14*** | ✓ |
| C: RV_total | 0.521 | 0.222 | -135% | +4.02*** | ✗ |
**** Harvey (2016) t > 3.0 顯著性門檻*
結論:模型-target 差異 = 壓縮,非翻轉
Condition A vs B 的對比 是這個實驗最關鍵的發現:
- 用 r² 評估:HAR-RV 領先 GJR 16% (DM t=-5.14,仍顯著)
- 用 RV_day 評估:HAR-RV 領先 GJR 66% (DM t=-11.14)
- 兩者都顯著,排名相同—— Patton 2011 的 proxy-robustness 在此成立
但 r² 的高噪音將 HAR-RV 的真實優勢 壓縮了 4 倍 (66% → 16%)。這就是「模型-target 差異」的精確含義:代理指標的品質設定了可觀測優勢的上限,不是翻轉,而是壓制。
Condition C 的排名翻轉是另一回事:HAR-RV 只在 RV_day 上訓練,對 RV_total(包含夜盤)的預測能力較差,這是 target mismatch (訓練目標與評估目標不一致),不是 模型-target 差異。
K854 Common Sample:統一樣本後的公平比較
實驗設計修正
K850 中的不公平:GJR 類模型有 481 天 OOS,HAR 類只有 450 天(因 RV 數據起始較晚)。K854 將所有 7 個模型都對齊到 同 450 天 (2023-03-01 至 2024-12-31)。
7 個模型 :GJR+Normal、GJR+CF、GJR+Skewed-t、HAR+Normal、HAR+CF、HAR+HistSim、RGL+CF(Realized GARCH-Log)
QLIKE 結果(仍是 HAR 優)
| 模型族 | QLIKE | 對比 |
|---|---|---|
| HAR-RV | 0.1004 | 基準 |
| GJR-GARCH | 0.2046 | HAR 好 51% |
| Realized GARCH-Log | 0.2093 | HAR 好 52% |
DM 檢定:HAR vs GJR t=-4.98(p<0.001);HAR vs RGL t=-9.72(p<0.001),顯著性不受樣本縮短影響。
VaR 結果(Paradox 持續)
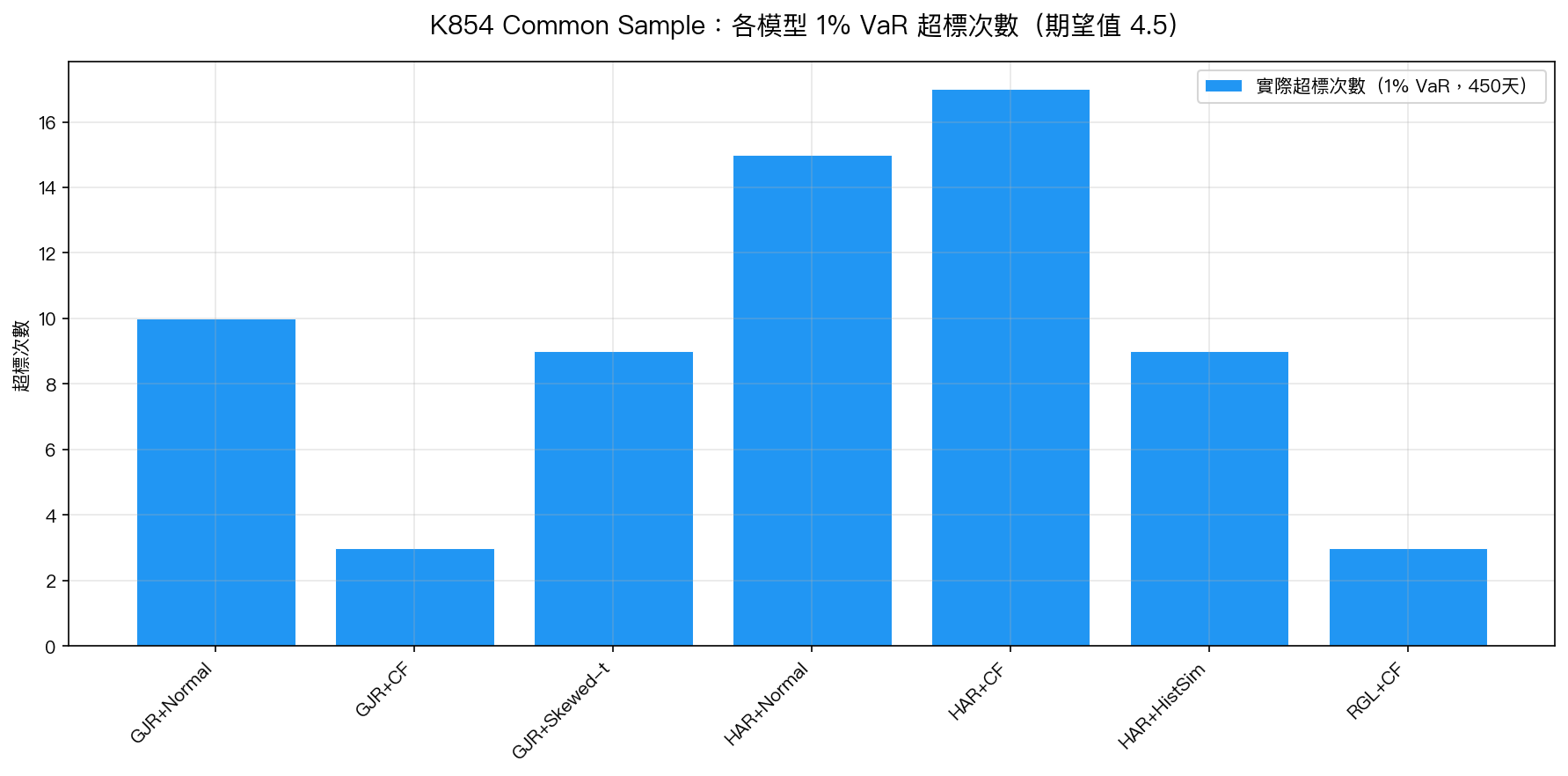
圖二:K854 Common Sample(450 天)各模型 1% VaR 超標次數。期望值為 4.5 次(1% × 450)。GJR+CF 和 RGL+CF 以 3 次 Trinity PASS;HAR 族全部 FAIL(9–17 次)。
| 模型 | 1% 超標次數 | 超標率 | Kupiec | Christoffersen | Basel | Trinity |
|---|---|---|---|---|---|---|
| GJR+Normal | 10 | 2.22% | FAIL | PASS | 黃燈 | FAIL |
| GJR+CF | 3 | 0.67% | PASS | PASS | 綠燈 | PASS |
| GJR+Skewed-t | 9 | 2.00% | PASS | PASS | 黃燈 | FAIL |
| HAR+Normal | 15 | 3.33% | FAIL | PASS | 紅燈 | FAIL |
| HAR+CF | 17 | 3.78% | FAIL | PASS | 紅燈 | FAIL |
| HAR+HistSim | 9 | 2.00% | PASS | PASS | 黃燈 | FAIL |
| RGL+CF | 3 | 0.67% | PASS | PASS | 綠燈 | PASS |
Trinity PASS(三關全過) :只有 GJR+CF 和 RGL+CF。
K854 vs K850 比較
| K850(不公平) | K854(公平) | |
|---|---|---|
| GJR+CF OOS 天數 | 481 | 450 |
| HAR OOS 天數 | 450 | 450 |
| GJR+CF 1% 超標 | 2/481 | 3/450 |
| HAR+HistSim 1% 超標 | 9/450 | 9/450 |
| Paradox 成立? | 疑似 | 確認 |
結論 :多給 GJR 的 31 天微調沒有關鍵作用。統一後 GJR+CF 超標從 2 升至 3(仍 PASS),HAR 維持 9(FAIL)。Paradox 的成因是方法論差異,不是比較不公平。
機制解釋:為什麼「預測更好」但「VaR 更差」?
HAR-RV 的 VaR 轉換問題
HAR-RV 預測的是 $\hat{\sigma}^2 = E[RV_{t}]$,要轉換成 VaR 需要假設:
\text{VaR}{1%} = \hat{$\sigma$} \cdot z{0.01}^{(\text{HAR residual})}
問題在於 HAR 殘差(RV_t / E[RV_t])的分配非常 fat-tailed(kurtosis > 10),且 log-normal 假設在極端事件時大幅低估尾部。三種 HAR VaR 方法(Normal、CF、HistSim)都無法完全修復這個問題。
GJR+CF 的優勢在哪?
GJR-GARCH 直接對標準化殘差 $z_t = r_t / \sigma_t$ 建模,這些殘差的 kurtosis 遠比 HAR 殘差小(~3-5 vs ~10+)。Cornish-Fisher 修正只需校正「輕微的」fat tail,效果穩定。
根本差異 :HAR 預測方差的路徑是「RV 測量 → 聚合 → 日波動率」,而 GJR 的路徑是「直接對日頻報酬的條件方差建模」。後者的殘差結構更接近 VaR 所需的「左尾特性」。
Realized GARCH 的雙重優勢
RGL+CF(Realized GARCH-Log + Cornish-Fisher)能同時通過兩個測試,原因是:
- RV 測量方程 吸收了高頻信息 → 改善排名(Spearman 0.790,兩者之最)
- GARCH 殘差結構保留 → 讓 CF 修正可以有效運作
但 QLIKE 面向仍落後 HAR(0.209 vs 0.100),「悖論」未完全消除,而是被部分橋接。
方法論意涵
給研究者
- Proxy 的選擇不改變排名,但影響統計功效 :用 r² 評估可能需要 4 倍的樣本才能達到用 RV_day 評估的統計顯著性
- 公平比較是必要的 :K854 確認了即使統一樣本,Paradox 也成立,但這需要實驗設計明確控制
- VaR 評估與預測精度評估不可互換 :Patton (2011) proxy-robustness 只保證 QLIKE 排名一致,不保證 VaR 排名一致
給實務應用
| 用途 | 推薦模型 | 理由 |
|---|---|---|
| 波動率排名/擇時 | HAR-RV | QLIKE 最優,Spearman 高,適合相對判斷 |
| VaR/監管合規 | GJR+CF | Trinity PASS,Basel 綠燈 |
| 兩者兼顧(初步) | RGL+CF | Spearman 最高 + Trinity PASS,但 QLIKE 仍輸 HAR |
研究局限
- 單一資產 :0050.TW 結論未必適用於 SPY、外匯或其他資產類別
- OOS 期間 (2023–2024):相對平靜,結論在 COVID 級別衝擊下可能不同
- HAR 夜盤擴充 :若 HAR 也在 RV_total 上訓練,Condition C 的排名翻轉可能改變
- 分配假設搜索 :HAR 的 VaR 問題未用更完整的非參數尾部模型(如 EVT)修復
- K854 的 450 天 OOS :樣本較小,部分模型的 Kupiec 檢定功效有限
實驗腳本: experiments/k853_proxy_ablation.py、experiments/k854_common_sample_var.py
結果數據: experiments/k853_proxy_ablation_results.json、experiments/k854_common_sample_var_results.json
數據來源: TAIFEX TX1 tick data(5 分鐘 RV)+ yfinance 0050.TW,OOS 期間 2020–2025(K853)/ 2023–2024(K854)
參考文獻: Corsi (2009) J Fin Econometrics; Patton (2011) J Econometrics; Hansen & Lunde (2005) J Applied Econometrics; Harvey, Leybourne & Newbold (2016) JBES; Kupiec (1995); Christoffersen (1998); Basel Committee (2016)
相關文章
先讀正式關聯,若無則使用標籤與主題相似度補齊